python小爬虫脚本
靶场:
http://hackinglab.cn/ShowQues.php?type=scripts
其中题目很有意思:
http://lab1.xseclab.com/xss2_0d557e6d2a4ac08b749b61473a075be1/index.php
payload:
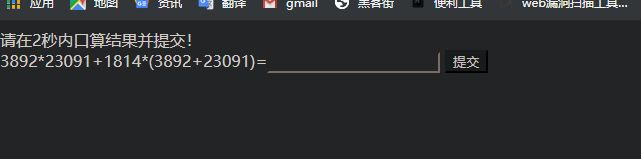
很简单,就是写一个小爬虫,爬下来里面数字内容,然后使用eval函数将其计算出来,不过可能很多简单题目中会使用到这种爬虫:
import re
from bs4 import BeautifulSoup
import requests
import json
x = "http://lab1.xseclab.com/xss2_0d557e6d2a4ac08b749b61473a075be1/index.php"
session = requests.session() #设置session连接,能保证连接的稳定性
line = session.get(x)
new2 = re.findall(' .+\)',line.text) #提取html流中数据的内容
new3 = new2[0]
new = new3.lstrip() #去掉前面的空格
p = eval(new)
d = dict(v=p) #将要提交的计算结果提交
exp = session.post(x,data=d) #data代表了post传参
print(exp.text)
运行脚本:
可以看到,key很简单就出来了
踩坑:
其中这种题目要首先看看存不存在session,这个平台题目都带有session,所以要使用session方式来建立连接,这样才能保持连接的稳定性。
另外,进行传参的时候可以直接传入字典,不一定非要json化,有的时候甚至会报错,另外就是re库正则表达式的使用,要总结一下,最好是用beautifulsoup库来进行解析,不过没有正则更加精准一些。