MySQL查询结果导出方式总结
说明:以下示例中使用的MySQL版本为MySQL8.0.13,Python版本为Python3.6.4,数据库第三方客户端Navicat Premium版本为 12.0.18
方法一:利用select ······ into outfile语句
首先登陆MySQL,然后查看系统变量secure_file_priv的值,如下所示:
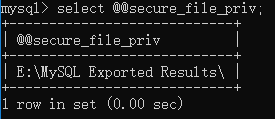
默认情况下,secure_file_priv的值为NULL,此时如果利用select ······ into outfile语句将查询结果导出,会因为权限问题而报错,要想解决这个问题可以在MySQL的配置文件my.ini中添加语句secure_file_priv = 'some directory',some directory指的是SQL语句查询结果要保存的位置。此处,笔者已在配置文件my.ini中添加了语句secure_file_priv = E:\MySQL Exported Results。
以.xls文件形式导出查询结果,SQL语句如下:

导出结果如下图所示:

利用这种方式导出的查询结果不包括列名,可以根据数据库中的原始数据手工给各列添上对应的列名。
以csv文件形式导出查询结果,SQL语句如下:
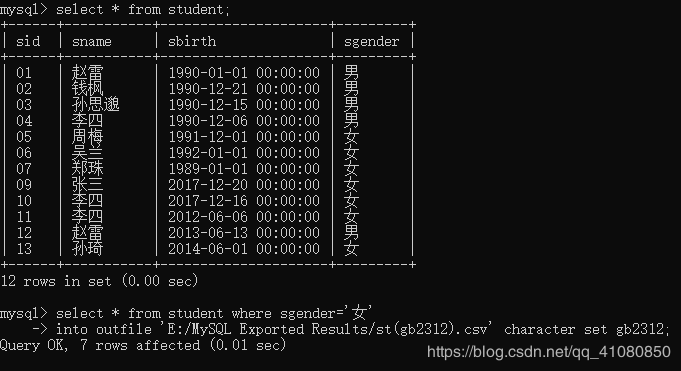
导出结果如下图所示:
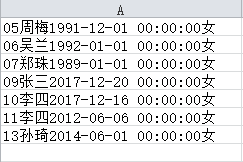
从上图可以看到导出结果全部都放入了同一列中,想要对导出的数据做进一步还要进行手工分列,比较麻烦。如有哪位朋友知晓用这种方式如何将查询结果以csv文件形式导出且分列正确,还请不吝赐教。
方法二:利用重定向命令
将查询结果以txt文件形式导出,SQL语句如下(默认已为mysql添加了环境变量):
![]()
最终导出结果如下:
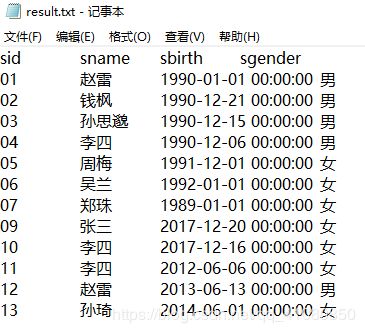
从上图可以看到,这种导出方式得到的导出结果分列正确,且带有列名。
方法三:利用第三方客户端工具Navicat Premium
以将查询结果导出为csv文件为例,具体步骤如下:
1)打开navicat premium(默认已经建立好MySQL数据库连接),选中相应的数据库,然后建立新的查询。

2)先点击右上角的运行按钮,然后点击导出结果图标,出现如下图所示对话窗口,在导出格式选项中选择CSV文件。
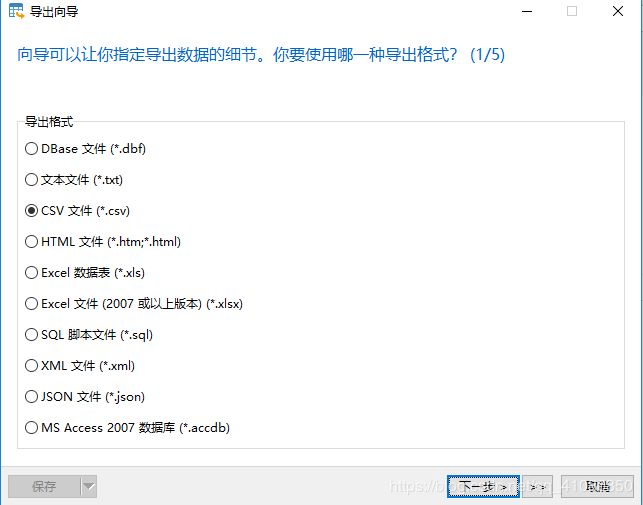
3)点击右下角的下一步后,跳出如下窗口。
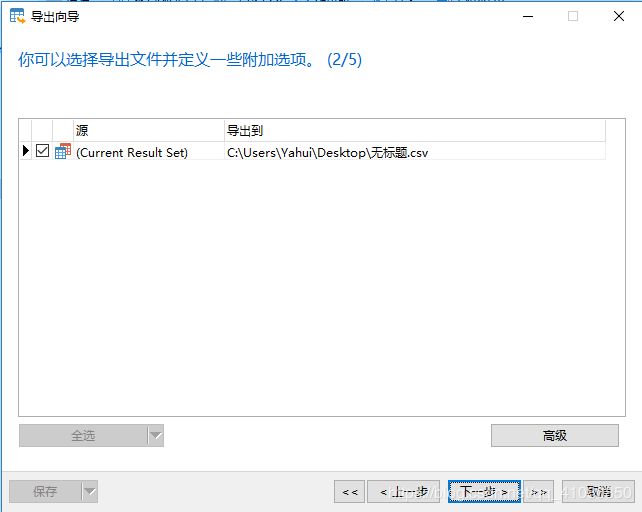
4)设置导出文件的保存位置及文件名称。

5)点击上图中右下角的高级选项,设置csv文件的字符集编码方式为GB2312(默认是UTF-8)。
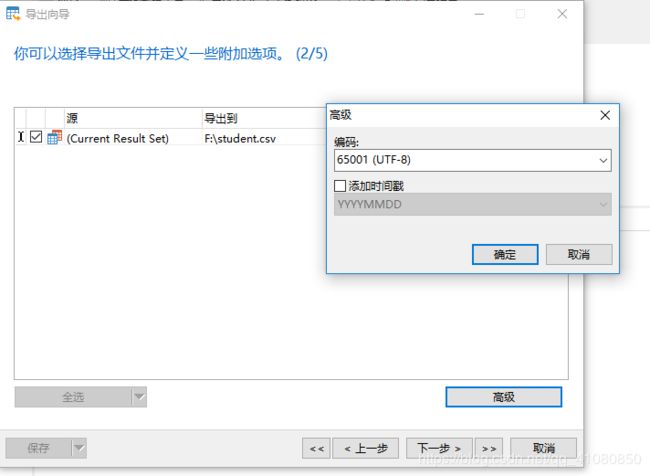
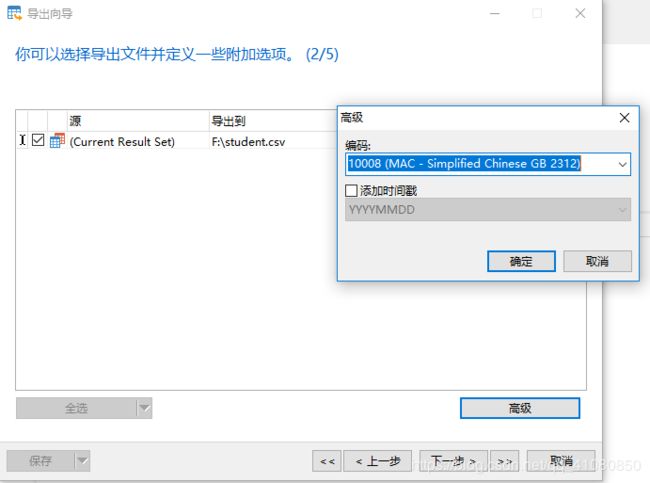
6)设置好字符集编码方式后,先点击确定按钮,再点击右下角的下一步,跳出如下窗口。
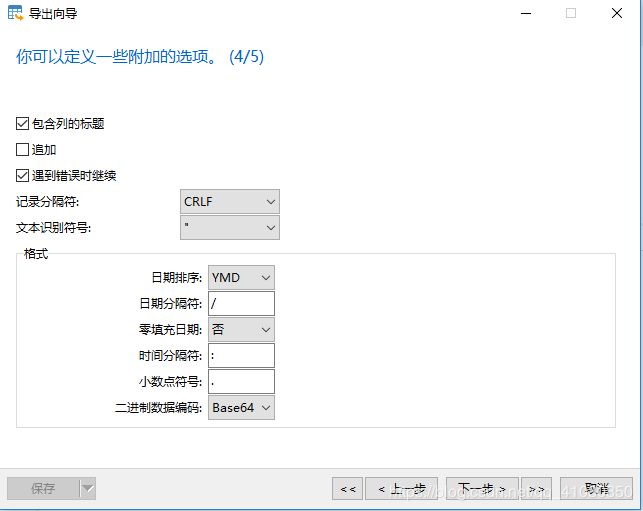
7)在上图中,勾选包含列的标题,并将日期排序更改为我们熟悉的YMD(即年月日)格式,其他保持默认值即可。然后点击右下角的下一步,跳出如下窗口。
8)在上述窗口中点击右下角的开始,即开始导出查询结果。

如上图所示,则表明查询结果已成功导出。
最终的导出结果如下图所示:

从上图可以看到,这种方式导出的查询结果可以包含查询结果各列对应的列名,且有着正确的分列。上述步骤说的是将查询结果导出为csv文件,若想将查询结果导出为.xls或者.xlsx文件,步骤与上述类似,且不用更改导出文件的字符集编码方式,使用默认的UTF-8即可。
方法四:利用Python与MySQL的交互
import pandas as pd
import pymysql
# 定义一个用于与MySQL数据库交互的上下文管理器:
class DataBase(object):
def __init__(self,name,password):
# 创建数据库连接
self.conn = pymysql.connect('localhost','root',str(password),str(name),charset='utf8mb4')
# 创建cursor对象
self.cursor = self.conn.cursor()
def __enter__(self):
return self.cursor # 返回cursor对象,且这个cursor对象会被赋给with语句中as后面的变量
def __exit__(self,exc_type,exc_value,traceback):
self.cursor.close() # 关闭游标对象
self.conn.close() # 断开数据库连接
def main():
with DataBase('sql50',883721) as db:
db.execute("select * from student where sgender='男'") # 执行sql语句
content = db.fetchall() # 获取数据(db中保存着查询结果集)
df = pd.DataFrame(list(content)) # 将从数据库中查询出的数据放入DataFrame对象中
return df
if __name__ == '__main__':
df = main()
new_cols = ['sid','sname','sbirth','sgender']
df.columns = new_cols
df.head()查询结果df的数据结构如下图所示:

# 将查询结果df写入csv文件:
df.to_csv('E:/student.csv',sep=',',index=False,encoding='gbk')导出的csv文件student中的数据如下所示:

利用这种方式将SQL语句的查询结果导出时,也需要根据数据库中的原始数据给导出数据中的各列添加对应的列名。
类似的,如果想以.xlsx文件的形式导出SQL语句的查询结果,可以调用DataFrame的to_excel方法,此处不再赘述。
参考:
https://dev.mysql.com/doc/refman/8.0/en/select-into.html
https://dev.mysql.com/doc/refman/8.0/en/server-system-variables.html#sysvar_secure_file_priv
https://blog.csdn.net/qq_41080850/article/details/85100641
http://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.to_csv.html?highlight=dataframe%20to_csv#pandas.DataFrame.to_csv
https://blog.csdn.net/pengchengliu/article/details/82884046