[论文学习]1——Stacked AutoEncoder(SAE)堆栈自编码器
《Deep Learning-Based Feature Representation and Its Application for Soft Sensor Modeling With Variable-Wise Weighted SAE》
论文地址:https://ieeexplore.ieee.org/document/8302941
这篇论文是Central South University的Xiaofeng Yuan,Biao Huang,Yalin Wang,Chunhua Yang,Weihua Gui所写的,发表在《IEEE Transactions on Industrial Informatics》期号:No.7;卷号:Vol.14;页码:3235-3243上面的。
为什么我要解读这篇论文呢,因为我的研究生导师就是其中的作者。言归正传,让我们来好好学习并总结一下这篇论文中主要的内容吧。
在这篇论文中,作者提出了Variable-wise weighted stacked autoencoder (VWSAE) 模型,用于逐层对输出相关量分层的特征表示,通过与输出变量的相关性分析,从每个自编码器的输入层的其他变量识别出重要变量,相应的变量分配不同的权重。
对于多层神经网络,深度学习分层提取输入数据的深层特征主要由两个程序组成:无监督的分层预训练和监督的微调。
首先我们需要知道什么是栈式自编码器?
1 Stacked AutoEncoder(SAE)堆栈自编码器
在论文中指出,SAE是由多层Autoencoder(AE)组成的层级深度神经网络结构。AE是一种无监督的含有一个隐含层神经网络,其中输出层被设置为等于输入层,AE的目的是尽可能的准确地重建原始输入。AE模型的结构如下图所示:
![[论文学习]1——Stacked AutoEncoder(SAE)堆栈自编码器_第1张图片](http://img.e-com-net.com/image/info8/8a55fc9483c14112a9455bfa0a7226d5.jpg)
AE由编码器和解码器组成。我们假设AE的输入是
![]()
其中dx是输入的维数。
编码器通过映射函数f将x从输入层投影到隐含层
![]()
其中d(h)是隐含层变量向量的维度。
其中f(x)函数表示为
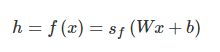
其中w是dh×dx权重矩阵,b∈Rdx是偏差向量。解码器的激活函数sf可以是sigmoid函数、tanh函数或者rectified linear unit function(ReLu函数)。关于这三个函数的对比及解释先提供两个网站,过段时间会自己学习并整理一下。
1.Sigmoid和tanh的异同
2.ReLu(Rectified Linear Unit Function)
在编码器中,通过映射函数f将隐含层表示的h映射到输出层的x∈Rdx,其中f函数如下:
![]()
其中w是dx×dh权重矩阵,b∈Rdx是输出层的偏差向量。同样sf的激活函数可以是sigmoid函数、tanh函数或者rectified linear unit function(ReLu函数)。因此,AE的参数集是
![]()
AE用于通过对网络施加限制(例如限制隐含层单元的数量)来重新构建输出x尽可能的与输入x相似。训练的输入数据表示为
![]()
其中N是训练样本总数。
每一个训练样本xi都被投影到隐含表示hi,然后被映射到重构数据xi。为了获得模型参数,通过计算均方重构误差最小化来重构损失函数
![[论文学习]1——Stacked AutoEncoder(SAE)堆栈自编码器_第2张图片](http://img.e-com-net.com/image/info8/3fa35c9d218a4c45aad55e9291594ae7.jpg)
AE的参数可以通过梯度下降算法来更新。
训练完成后,AE的权重和偏差被保存下来。SAE是一种具有分层结构的神经网络,由多个AE层逐层连接组成。SAE的模型如下图(a)所示
![[论文学习]1——Stacked AutoEncoder(SAE)堆栈自编码器_第3张图片](http://img.e-com-net.com/image/info8/973f0a5e7d434076b459018f6f106379.jpg)
通过两个步骤来训练SAE模型:逐层无监督预训练的监督微调
(这里我们通过别人写好的介绍来了解学习,之后会自己学习并整理自己的blog。
1.深度学习: greedy layer-wise pre-training (逐层贪婪预训练)
2.优化:微调Finetuning)
在本篇文章中,我们学习到。在预训练的步骤中,第一层AE通过最小化重构误差将原始输入数据映射到第一个隐含特征层。训练了第一个AE层之后,第一个隐含层的输出被用作第二个隐含层的输入。然后训练第二层AE得到参数{W2,B2}。通过这种方式,对整个SAE进行逐层预训练直到得到最后一个AE层。
在无监督预训练之后,将输出层加到SAE的顶部用来微调权重和偏差。预训练的权重被用作每个隐含层的权重的初始化,可以随机输出层的参数{W0,B0}.然后通过反向传播对整个网络进行微调,通过最小化目标变量的预测误差来获得改进的权重{WK,BK},k=1,2,3,...,K。反向传播函数为
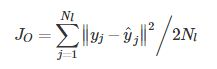
其中yj和yj^分别代表第j个数据样本的标记值和预测值。SAE的训练过程如上图(b)所示。
学习编码器相关知识
自编码器是单个编码器构成,是通过一个x -> h -> x 的三层网络,通过学习出一种特征变化h = f(wx+b)。实际上训练结束后,输出层就没有什么意义了,因为我们只关心从x到h的变换。单自动编码器,充其量也就是个强化补丁版PCA,只用一次好不过瘾。
![[论文学习]1——Stacked AutoEncoder(SAE)堆栈自编码器_第4张图片](http://img.e-com-net.com/image/info8/0739de8267574f0d8f8aeaa0a23bbc60.jpg)
但是堆栈自编码器的思路是:我们已经得到特征表达h,将h作为原始信息,训练一个新的自编码器,得到新的特征表达。Stacked 就是逐层堆叠的意思,当把多个自编码器 Stack 起来之后,这个系统看起来就像这样:
![[论文学习]1——Stacked AutoEncoder(SAE)堆栈自编码器_第5张图片](http://img.e-com-net.com/image/info8/04bf0c99123649188c7579ab1d20dea6.jpg)
需要注意的是,整个网络的训练不是一蹴而就的,而是逐层进行的。比如说我们训练一个n -> m -> k 结构的网络,实际上我们是先训练网络 n -> m -> n ,得到 n -> m 的变换,然后再训练 m -> k -> m 网络,得到 m -> k 的变换。最终堆叠成 SAE ,即为 n -> m -> k 的结果,整个过程就像一层层往上面盖房子,这就是大名鼎鼎的 layer-wise unsuperwised pre-training (逐层非监督预训练)。
具体实例
让我们来看个具体的例子,假设你想要训练一个包含两个隐含层的栈式自编码网络,用来进行MNIST手写数字分类(这将会是你的下一个练习)。 首先,你需要用原始输入 x^{(k)} 训练第一个自编码器,它能够学习得到原始输入的一阶特征表示 h^{(1)(k)}(如下图所示)。
![[论文学习]1——Stacked AutoEncoder(SAE)堆栈自编码器_第6张图片](http://img.e-com-net.com/image/info8/a6cec373b4084fd0825016bb050d6435.jpg)
接着,你需要把原始数据输入到上述训练好的稀疏自编码器中,对于每一个输入 x^{(k)},都可以得到它对应的一阶特征表示h^{(1)(k)}。然后你再用这些一阶特征作为另一个稀疏自编码器的输入,使用它们来学习二阶特征 h^{(2)(k)}。(如下图所示)
![[论文学习]1——Stacked AutoEncoder(SAE)堆栈自编码器_第7张图片](http://img.e-com-net.com/image/info8/3d652f04b4c8455cbfbd96ce1ac321cd.jpg)
同样,再把一阶特征输入到刚训练好的第二层稀疏自编码器中,得到每个 h^{(1)(k)} 对应的二阶特征激活值 h^{(2)(k)}。接下来,你可以把这些二阶特征作为softmax分类器的输入,训练得到一个能将二阶特征映射到数字标签的模型。
![[论文学习]1——Stacked AutoEncoder(SAE)堆栈自编码器_第8张图片](http://img.e-com-net.com/image/info8/365e528ecab348269923e52c1f6ad987.jpg)
如下图所示,最终,你可以将这三层结合起来构建一个包含两个隐藏层和一个最终softmax分类器层的栈式自编码网络,这个网络能够如你所愿地对MNIST数字进行分类。
![[论文学习]1——Stacked AutoEncoder(SAE)堆栈自编码器_第9张图片](http://img.e-com-net.com/image/info8/3d15034e92c7499a95657cf3946f96e8.jpg)
讨论
栈式自编码神经网络具有强大的表达能力及深度神经网络的所有优点。
更进一步,它通常能够获取到输入的“层次型分组”或者“部分-整体分解”结构。为了弄清这一点,回顾一下,自编码器倾向于学习得到能更好地表示输入数据的特征。因此,栈式自编码神经网络的第一层会学习得到原始输入的一阶特征(比如图片里的边缘),第二层会学习得到二阶特征,该特征对应一阶特征里包含的一些模式(比如在构成轮廓或者角点时,什么样的边缘会共现)。栈式自编码神经网络的更高层还会学到更高阶的特征。
举个例子,如果网络的输入数据是图像,网络的第一层会学习如何去识别边,第二层一般会学习如何去组合边,从而构成轮廓、角等。更高层会学习如何去组合更形象且有意义的特征。例如,如果输入数据集包含人脸图像,更高层会学习如何识别或组合眼睛、鼻子、嘴等人脸器官。
具体实例来源:UFLDL—栈式自编码算法
另一种解释:
原理:
![[论文学习]1——Stacked AutoEncoder(SAE)堆栈自编码器_第10张图片](http://img.e-com-net.com/image/info8/75dba57e4f2348b79d5eb9f518eff3e1.jpg)
逐层训练,利用完全训练的LayerOutput i作为LayerInput i+1
非监督学习网络训练方式和监督学习网络的方式是相反的。
在监督学习网络当中,各个Layer的参数W受制于输出层的误差函数,因而Layer i参数的梯度依赖于Layer i+1的梯度,形成了"一次迭代-更新全网络"反向传播。
但是在非监督学习中,各个Encoder的参数W只受制于当前层的输入,因而可以训练完Encoder i,把参数转给Layer i,利用优势参数传播到Layer i+1,再开始训练。形成"全部迭代-更新单层"的新训练方式。这样,Layer i+1效益非常高,因为它吸收的是Layer i完全训练奉献出的精华Input。