Python获取丁香园疫情数据并解析json数据
Python获取丁香园疫情数据并解析json数据
在利用pyecharts V1.x版本,使用Map对象进行制图时,对数据格式的要求比较高,如果数据格式不正确可能达不到我们预期的效果。在我的前一篇文章中介绍了如何利用丁香园疫情数据制作地图,今天就为大家说下如何爬取、解析数据。
-
- 地址解析
丁香园Github-疫情数据下载地址
https://github.com/BlankerL/DXY-2019-nCoV-Data/blob/master/json/DXYArea.json
- 爬虫爬取数据的页面
https://raw.githubusercontent.com/BlankerL/DXY-2019-nCoV-Data/master/json/DXYArea.json
-
- 爬虫实现
- 实现代码(更新于2020-04-01)
# -*- coding: utf-8 -*-
"""
@File : JsonCrawlerRelativeData.py
@Author : [email protected]
@Time : 2020/2/10 19:10
"""
import json
import requests
#爬取丁香园数据页面
url = 'https://raw.githubusercontent.com/BlankerL/DXY-2019-nCoV-Data/master/json/DXYArea.json'
response = requests.get(url)
# 将响应信息进行json格式化
versionInfo = response.text
print(versionInfo)#打印爬取到的数据
print("------------------------")
#一个从文件加载,一个从内存加载#json.load(filename)#json.loads(string)
jsonData = json.loads(versionInfo)
#用于存储数据的集合
dataSource = []
provinceShortNameList = []
confirmedCountList = []
curedCount = []
deadCountList = []
#遍历对应的数据存入集合中
for k in range(len(jsonData['results'])):
if(jsonData['results'][k]['countryName'] == '中国'):
provinceShortName = jsonData['results'][k]['provinceShortName']
if("待明确地区" == provinceShortName):
continue;
confirmedCount = jsonData['results'][k]['confirmedCount']
# 存储数据为键值对点形式([['江苏', 492], ['安徽', 830]])
dataSource.append("['"+provinceShortName+"',"+str(confirmedCount)+"]")
provinceShortNameList.append(provinceShortName)#省份名称简称
confirmedCountList.append(confirmedCount)
curedCount.append(jsonData['results'][k]['curedCount'])
deadCountList.append(jsonData['results'][k]['deadCount'])
# print(jsonData['results'][k]['provinceName'])#打印省份全称
print("data = "+str(dataSource).replace('"',''))#省份,确认人数集合data =[省份,确诊人数],[省份,确诊人数]...]
print("columns = "+str(provinceShortNameList))#省份集合
print("confirmedCount = "+str(confirmedCountList))#确诊人数集合
print("curedCount = "+str(curedCount))#治愈人数集合
print("deadCount = "+str(deadCountList))#死亡人数集合
- 爬取结果
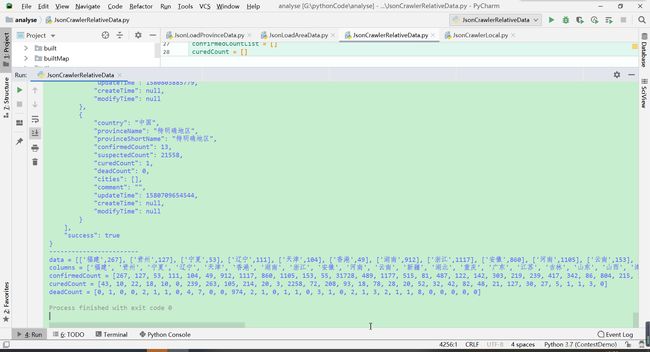
格式化JSON数据变成制图所需格式
-
反馈
在进行爬虫时,发现第一次爬取时有结果出现,第二次、第三次爬取…,可能被限制了IP。不过等个一个小时就又可以进行了。由于制图所需数据有限,爬一次就足够了。 -
本地方式获取(更新于2020-04-01)
如果不能爬下来,建议把今日份的JSON数据给保存到本地,然后通过读取本地文件的方式进行解析。
# -*- coding: utf-8 -*-
"""
@File : JsonLoadProvinceData.py
@Author : [email protected]
@Time : 2020/2/10 16:32
"""
import json
#数据下载地址
#https://github.com/BlankerL/DXY-2019-nCoV-Data/blob/master/json/DXYArea.json
#读取本地疫情JSON数据
f = open("./file/dat/data20200401.json",
encoding='utf-8') # 设置以utf-8解码模式读取文件,encoding参数必须设置,否则默认以gbk模式读取文件,当文件中包含中文时,会报错
jsonData = json.load(f)
#用于存储数据的集合
dataSource = []
provinceShortNameList = []
confirmedCountList = []
curedCount = []
deadCountList = []
#遍历对应的数据存入集合中
for k in range(len(jsonData['results'])):
if(jsonData['results'][k]['countryName'] == '中国'):
provinceShortName = jsonData['results'][k]['provinceShortName']
if("待明确地区" == provinceShortName):
continue;
confirmedCount = jsonData['results'][k]['confirmedCount']
# 存储数据为键值对点形式([['江苏', 492], ['安徽', 830]])
dataSource.append("['"+provinceShortName+"',"+str(confirmedCount)+"]")
provinceShortNameList.append(provinceShortName)#省份名称简称
confirmedCountList.append(confirmedCount)
curedCount.append(jsonData['results'][k]['curedCount'])
deadCountList.append(jsonData['results'][k]['deadCount'])
# print(jsonData['results'][k]['provinceName'])#打印省份全称
print("data = "+str(dataSource).replace('"',''))#省份,确认人数集合data =[省份,确诊人数],[省份,确诊人数]...]
print("columns = "+str(provinceShortNameList))#省份集合
print("confirmedCount = "+str(confirmedCountList))#确诊人数集合
print("curedCount = "+str(curedCount))#治愈人数集合
print("deadCount = "+str(deadCountList))#死亡人数集合
-
- 保存本地
将从github爬到的数据保存到本地磁盘上。
- 实现代码
# -*- coding: utf-8 -*-
"""
@File : JsonCrawlerLocal.py
@Author : [email protected]
@Time : 2020/2/10 18:41
"""
# 数据下载地址
import datetime
import json
import requests
# 获取所有数据json文件
def download_Json(url):
print("-----------正在下载json文件 %s" % (url))
# try:
# 将响应信息进行json格式化
response = requests.get(url)
versionInfo = response.text
versionInfoPython = json.loads(versionInfo)
# print(versionInfo)
path = './file/data' + str(datetime.datetime.now().strftime('%Y%m%d')) + '.json'
# 将json格式化的数据保存
with open(path, 'w', encoding='utf-8') as f1:
f1.write(json.dumps(versionInfoPython, indent=4))
# except Exception as ex:
# print("--------出错继续----")
# pass
# url = 'https://github.com/BlankerL/DXY-2019-nCoV-Data/blob/master/json/DXYArea.json'
url = 'https://raw.githubusercontent.com/BlankerL/DXY-2019-nCoV-Data/master/json/DXYArea.json'
# 获取疫情数据json文件
download_Json(url)
-
- 解析某省地级市的疫情数据(更新于2020-04-01)
这是一个基于本地下载好的,丁香园疫情github-JSON数据的解析。如果爬虫不能用可以手动复制到本地进行解析。本次以河南省为例,进行解析。
- 实现代码(更新于2020-04-01)
# -*- coding: utf-8 -*-
"""
@Author : [email protected]
@Time : 2020/2/10 16:32
"""
import json
#数据下载地址
#https://github.com/BlankerL/DXY-2019-nCoV-Data/blob/master/json/DXYArea.json
#读取本地JSON数据
f = open("./file/dat/data20200401.json",
encoding='utf-8') # 设置以utf-8解码模式读取文件,encoding参数必须设置,否则默认以gbk模式读取文件,当文件中包含中文时,会报错
jsonData = json.load(f)
#用于存储数据的集合
dataSource = []
cityNameList = []
confirmedCountList = []
curedCount = []
deadCountList = []
#遍历对应的数据存入集合中
for k in range(len(jsonData['results'])):
if(jsonData['results'][k]['countryName'] == '中国'):
provinceShortName = jsonData['results'][k]['provinceShortName']
#去除没有归属区域的数据
if( "河南" != provinceShortName):
continue;
for j in range(len(jsonData['results'][k]['cities'])):
confirmedCount = jsonData['results'][k]['cities'][j]['confirmedCount']
# 存储数据为键值对点形式([['江苏', 492], ['安徽', 830]])
cityName = jsonData['results'][k]['cities'][j]['cityName']
if ("待明确地区" == cityName or '境外输入' == cityName):
continue;
dataSource.append("['"+cityName+"市',"+str(confirmedCount)+"]")
cityNameList.append(cityName)#地级市名称
confirmedCountList.append(confirmedCount)#确诊人数
curedCount.append(jsonData['results'][k]['cities'][j]['curedCount'])#治愈人数
deadCountList.append(jsonData['results'][k]['cities'][j]['deadCount'])#死亡人数
# print(jsonData['results'][k]['provinceName'])#打印省份全称
print("data = "+str(dataSource).replace('"',''))#地级市,确认人数集合data =[[地级市,确诊人数],[地级市,确诊人数]...]
print("columns = "+str(cityNameList))#地级市集合
print("confirmedCount = "+str(confirmedCountList))#确诊人数集合
print("curedCount = "+str(curedCount))#治愈人数集合
print("deadCount = "+str(deadCountList))#死亡人数集合
- 解析结果
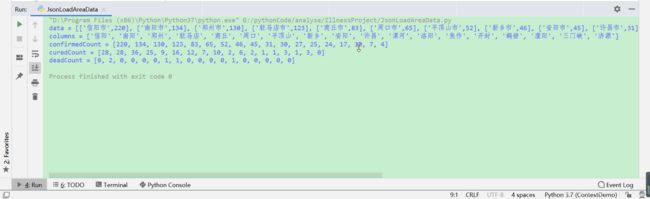
河南省丁香园疫情数据解析结果-2020/02/11
-
- 结尾
喜欢的朋友们可以点个关注,后续将持续更新,精彩无限^ - ^