基于深度self-attention的字符集语言模型(transformer)论文笔记
论文题目:Character-Level Language Modeling with Deeper Self-Attention
论文地址:https://arxiv.org/abs/1808.04444v1
摘要
LSTM和其他RNN的变体在字符级别的语言建模方面取得了很好的成功。这些模型一般情况下都会使用反向传播来进行训练,并通常把这些模型的成功归结与RNN结构的长时记忆能力。在本文中,我们将为大家介绍一个深层(64层)的transformer模型。在2个常用的测试基准数据集上这个模型结构取得大大优于RNN变种的成绩(1.13 bits per character on text8 and 1.06 on enwik8),成为目前最为领先的技术。在得到这个良好的结果过程中,我们证明了在中间网络层和中间序列位置附加损失是非常重要的。
简介
自然语言文本的字符集建模存在很多挑战。首先,模型必须“从头开始”学习大量的词汇。其次,自然文本很难处理数百或者数千长距离步长的序列问题(长时依赖)。第三,字符集序列要比单词级序列长很多,因此需要更多的计算步骤。
近年来的,高级的语言模型普遍遵循一个套路,使用相对较短的序列长度(例如限制为200个字符)对小批量的文本序列训练RNN模型。那么怎么捕获上下文信息呢?我们按顺序训练数据批次,并将前以批次的隐藏状态传递给当前批次。这个过程称为“truncated backpropagation through time” 按时间的反向传播(TBTT),很显然RNN的梯度计算不会每个批次更新一步。到目前已经出现了很多优化TBTT的算法。
虽然这样的结构取到了很好的成效,但是它增加了训练的复杂性。但最近一些研究表明,用这样的方式训练模型实际上并没有真的得到‘很强’的长期记忆能力。例如Khandelwal等人,发现基于单词的LSTM语言模型只能有效地使用约200个上下文(即使提供了更多),并且该单词顺序仅在最后的~50个标记内有效。
本文中,我们使用了一个非循环的神经网络结构并在基于字符级的语言模型上取得了强有力的结果。具体来说,我们使用了一个基于transformer self attention层的深度网络。这个模型从训练语料的随机位置训练每个小批次的序列,取消了RNN的按时传递信息的方式,使用causal (backward-looking) attention的方式反向传播。
我们有个很重要的发现就是transformer很适合语言模型的建模,并且是达到了可以取代RNN的位置。我们推transformer的成功源于它能够‘快速的’在任意距离上传播信息。相比之下,RNN需要逐步学习来传递相关信息。我们还发现,对基础transformer架构进行一定的修改可能会带来一定的益处。但最重要的,我们添加了3个auxiliary losses,要求模型预测即将到来的字符
- 在序列中的位置。
- 隐藏层中的表示。
- 在目标位置预测未来的的多少个步骤。
这些损失加速了收敛,使得我们可以训练更深层的网络。
字符集transformer模型
语言模型通过有限长度的公式分解联合概率,并分配到标记序列上。
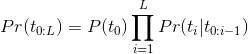
为了用模块化的方式计算条件概率![]() ,我们选了一个transformer的网络来处理字符集的序列
,我们选了一个transformer的网络来处理字符集的序列![]() 。transformer网络最近在处理序列问题上表现突出,相较于传统网络结构,transformer网络往往能够取得更好的效果。
。transformer网络最近在处理序列问题上表现突出,相较于传统网络结构,transformer网络往往能够取得更好的效果。
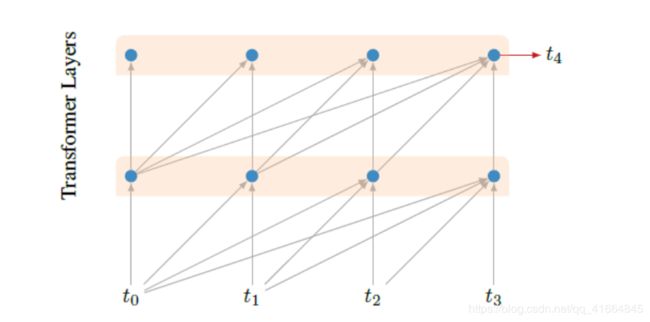
我们的字符级的transformer结构由64个transformer层组成。如Vaswani所介绍,transformer层 是由有多个self-attention层后跟着2个全连接层组成的前馈神经网络组成。更多有关transformer的细节可以前往这个地址-tensor2tensor。为了确保这个模型在预测的时候只以考虑当前词之前的词,我们将我们的attention层转化为causal attention,(attention layer只向(右)后传播),这个原理与seq2seq问题的原始transformer架构的decoder 组件中的“masked attention”相同。
下图展示了causal attention的原理框图,causal attention只允许信息从序列的左边流转到右边,对单词的预测只考虑到在这个单词前面出现的单词。
Auxiliary Losses
在我们的了解中,我们的网络结构是目前为止最深的transformer网络。在最初的实验中我们发现,训练网络的深度超过10层就会出现收敛慢准确性差的挑战。在这里我们提出了auxiliary losses的概念,它能使得深层的网络更好的发挥作用,从而大大的加快了收敛的速度。
我们在中间位置,中间层和非相邻目标中添加了几种类型的auxiliary losses。在实验中我们猜测这些损失不仅可以加速收敛,还可以作为额外的正则化器,训练的时候我们将auxiliary losses添加到更新权值网络的最终loss中。每种类型的auxiliary loss 都有自己schedule of decay。在评估和预测的时候,仅仅需要用到最终层的最终位置。
具体来说就是,这种方法的意义在于许多的训练参数仅仅在训练的期间使用,分类层(输出层)的参数与中间层和非相邻目标的预测预测值有关。所以在我们模型的介绍中,需要注意我们讨论的是“训练参数”还是预测“预测参数”。
Multiple Positions