Python3.5+fiddler4 爬取微信公众号点赞,阅读,标题,推送时间等信息
代码测试至2019/03/08有效
微信爬虫步骤:
必须品:
- 自己的微信公众账号
- Fiddler 抓包工具
- Python 3+ 版本
Fiddler 下载地址
HTTP代理工具又称为抓包工具,主流的抓包工具 Windows 平台有 Fiddler,macOS 有 Charles,阿里开源了一款工具叫 AnyProxy。它们的基本原理都是类似的,就是通过在手机客户端设置好代理IP和端口,客户端所有的 HTTP、HTTPS 请求就会经过代理工具,在代理工具中就可以清晰地看到每个请求的细节,然后可以分析出每个请求是如何构造的,弄清楚这些之后,我们就可以用 Python 模拟发起请求,进而得到我们想要的数据。
安装包就 4M 多,在配置之前,首先要确保你的手机和电脑在同一个局域网,如果不在同一个局域网,你可以买个随身WiFi,在你电脑上搭建一个极简无线路由器。安装过程一路点击下一步完成就可以了。
Fiddler 配置 选择 Tools > Fiddler Options > Connections Fiddler 默认的端口是使用 8888,如果该端口已经被其它程序占用了,你需要手动更改,勾选 Allow remote computers to connect,其它的选择默认配置就好,配置更新后记得重启 Fiddler。一定要重启 Fiddler,否则代理无效。.接下来你需要配置手机,但是这里微信有pc客户端,因此不需要配置手机
现在打开微信随便选择一个公众号,进入公众号的【查看历史消息】
同时观察 Fiddler 的主面板 当微信从公众号介绍页进入历史消息页面时,在 Fiddler 上已经能看到有请求进来了,这些请求就是微信 APP 向服务器发送的请求,现在简单介绍一下这个请求面板上的每个模块的意义。

我把上面的主面板划分为 7 大块,你需要理解每块的内容,后面才有可能会用 Python 代码来模拟微信请求。 1、服务器的响应结果,200 表示服务器对该请求响应成功 2、请求协议,微信的请求协议都是基 于HTTPS 的,所以前面一定要配置好,不然你看不到 HTTPS 的请求。 3、微信服务器主机名 4、请求路径 5、请求行,包括了请求方法(GET),请求协议(HTTP/1.1),请求路径(/mp/profile_ext...后面还有很长一串参数) 6、包括Cookie信息在内的请求头。 7、微信服务器返回的响应数据,我们分别切换成 TextView 和 WebView 看一下返回的数据是什么样的。
TextView 模式下的预览效果是服务器返回的 HTML 源代码

WebView 模式是 HTML 代码经过渲染之后的效果,其实就是我们在手机微信中看到的效果,只不过因为缺乏样式,所以没有手机上看到的美化效果。

如果服务器返回的是 Json格式或者是 XML,你还可以切换到对应的页面预览查看。
开始爬虫:
1,自己的微信公众账号
登录微信公众账号,菜单栏中:素材管理—>新建素材,出现如下页面
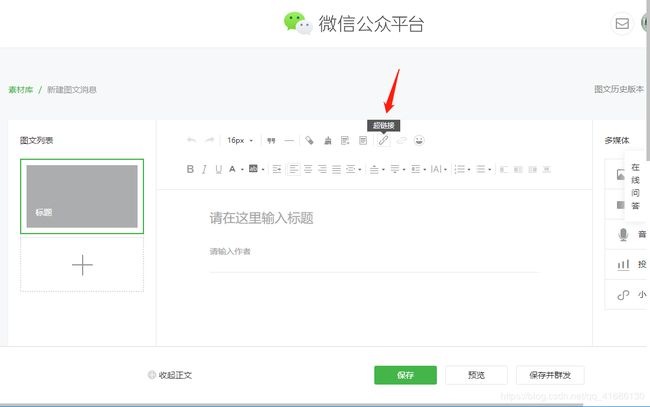
F12 查看network,点击图中位置
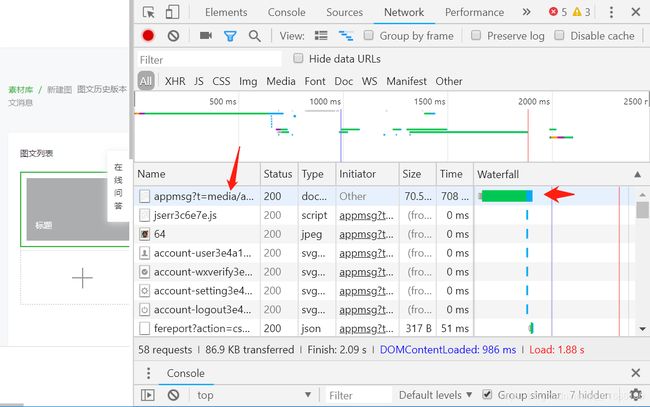
公众号的cookies,和 user-Agent 如下
Fakeid 和token 获取方式如下:
点击要爬取的公众号:
F12,点击图中路径
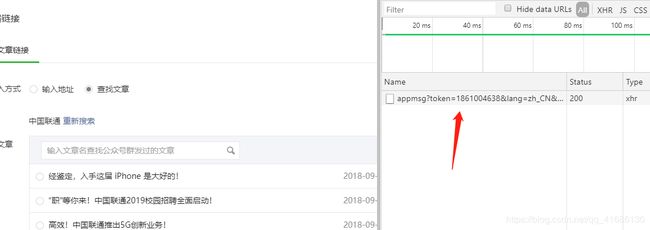

以上获得的是电脑端 需要的4个重要参数
Cookies、user-Agent 、fakeid 、token
对应程序中:

接下来是爬取点赞数和阅读数的需要的参数:
分别是 pass_ticket 、 appmsg_tojen 、 cookies 、user-Agent 、key

这里req_id不需要添加,之前需要,现在利用pc机不需要了
如何获取以上数据:
pc微信点击一个文章,按如下红色框,获取Key、 pass_ticket 、 appmsg_tojen

点击上面红框地址:获取 pc微信端cookie 和user-agent
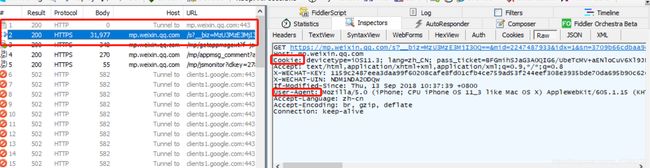
依次替换后
在入库部分:


直接运行等待结果即可。
PS:更换公众号爬虫只需要更换PC微信的Key、 pass_ticket 、 appmsg_tojen以及公众号的Fakeid ,对某一公众号爬虫时,KEY大约20-30分钟会失效,可以再最后面的range(a,b)填写当前爬取的页面,假如需要爬到第20页,b需要填21,如果没有装mongodb的,可以改写保存为其他文件输出。
# -*- coding: utf-8 -*-
import requests
import time
import json
from pymongo import MongoClient
# 西安
sheetName = "郑州市教工幼儿园"
# 目标url
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
Cookie = "noticeLoginFlag=1; remember_acct=sisecx; pgv_pvi=7219193856; RK=G5400dGxMt; ptcz=557d79434d3b03505b26caa42def3262945db5b8327b95a0a003cc5513325400; pgv_pvid=2825329760; ua_id=rdfu3R15vwoD0zBWAAAAAEuTMkfxxxLJWgk5F4JZ1rg=; mm_lang=zh_CN; eas_sid=e1G5K3I7Q413H327D8r2D0N0m8; tvfe_boss_uuid=d04d93bc9e7c29dd; o_cookie=1094925362; pac_uid=1_1094925362; noticeLoginFlag=1; pgv_si=s6094909440; uuid=3fcfd3536a1da1617b1c460561fe4ee9; ticket=a42969b394561892ff83833984636cebf5e230e8; ticket_id=gh_bbec56f0be44; cert=kZiwXU4vUjwS4L4VbRFNhQ7wdk1nAg7w; data_bizuin=3279092990; bizuin=3202111501; data_ticket=vS4jc0RF6mPDMY34/PsmRIVOBbvvFgajttGtWY2XrQ7Letj9v+P853t42+JkQ112; slave_sid=ZkZqT2U5SFdCalJNUEhQaV9YWEpQbWRMT3lOWlNZZm9BUExGU0dybjVNZVZxS3d4TFB0YW04dW5VRG94cjA2bmlqd0lBc1FibmJ0cVhOS19TMm1IUWlFSVJZX1RZU3RraG4yMTlBazBZNnhCX2w0aUpNWjMzS2c5WTRJUWhtdmtBOHlmdWsxakFtNDJIc1ph; slave_user=gh_bbec56f0be44; xid=e42471c91cfa65d371d6fe4d219f1c3f; openid2ticket_o_vxyw0uA4Vzrdz952biH10elOaI=blxqkvVWDqz0nohpf5e4CJFqWP8P66HqBtotbbb9bpk=; rewardsn=; wxtokenkey=777"
# 使用Cookie,跳过登陆操作
headers = {
"Cookie": Cookie,
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36",
}
"""
需要提交的data
以下个别字段是否一定需要还未验证。
注意修改yourtoken,number
number表示从第number页开始爬取,为5的倍数,从0开始。如0、5、10……
token可以使用Chrome自带的工具进行获取
fakeid是公众号独一无二的一个id,等同于后面的__biz
"""
token = "381897441"
fakeid ="MzA3ODU2ODE3Mg=="
# type在网页中会是10,但是无法取到对应的消息link地址,改为9就可以了
type = '9'
data1 = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": "365",
"count": "5",
"query": "",
"fakeid": fakeid,
"type": type,
}
# 毫秒数转日期
def getDate(times):
# print(times)
timearr = time.localtime(times)
date = time.strftime("%Y-%m-%d %H:%M:%S", timearr)
return date
# 获取阅读数和点赞数
def getMoreInfo(link):
# 获得mid,_biz,idx,sn 这几个在link中的信息
mid = link.split("&")[1].split("=")[1]
idx = link.split("&")[2].split("=")[1]
sn = link.split("&")[3].split("=")[1]
_biz = link.split("&")[0].split("_biz=")[1]
# fillder 中取得一些不变得信息
#req_id = "0614ymV0y86FlTVXB02AXd8p"
pass_ticket = "4KzFV%252BkaUHM%252BatRt91i%252FshNERUQyQ0EOwFbc9%252FOe4gv6RiV6%252FJ293IIDnggg1QzC"
appmsg_token = "999_SVODv6i0%2FSNhK8CliOHzbKOydLO3IWXbnYfk2aiso-KkGL9w9a38IZlJCyOAXYyNJXdGn3zR5PTNWklR"
# 目标url
url = "http://mp.weixin.qq.com/mp/getappmsgext"
# 添加Cookie避免登陆操作,这里的"User-Agent"最好为手机浏览器的标识
phoneCookie = "wxtokenkey=777; rewardsn=; wxuin=2529518319; devicetype=Windows10; version=62060619; lang=zh_CN; pass_ticket=4KzFV+kaUHM+atRt91i/shNERUQyQ0EOwFbc9/Oe4gv6RiV6/J293IIDnggg1QzC; wap_sid2=CO/FlbYJElxJc2NLcUFINkI4Y1hmbllPWWszdXRjMVl6Z3hrd2FKcTFFOERyWkJZUjVFd3cyS3VmZHBkWGRZVG50d0F3aFZ4NEFEVktZeDEwVHQyN1NrNG80NFZRdWNEQUFBfjC5uYLkBTgNQAE="
headers = {
"Cookie": phoneCookie,
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 MicroMessenger/6.5.2.501 NetType/WIFI WindowsWechat QBCore/3.43.901.400 QQBrowser/9.0.2524.400"
}
# 添加data,`req_id`、`pass_ticket`分别对应文章的信息,从fiddler复制即可。
data = {
"is_only_read": "1",
"is_temp_url": "0",
"appmsg_type": "9",
'reward_uin_count':'0'
}
"""
添加请求参数
__biz对应公众号的信息,唯一
mid、sn、idx分别对应每篇文章的url的信息,需要从url中进行提取
key、appmsg_token从fiddler上复制即可
pass_ticket对应的文章的信息,也可以直接从fiddler复制
"""
params = {
"__biz": _biz,
"mid": mid,
"sn": sn,
"idx": idx,
"key": "f488c6fef5eafe9df3b4884c84601447488b75476cd7c26116c5427e86704be66818df57ccf6e8710db981ea2e9067fd6adb2080066cc7633e8b1d6fe60c52a812ac2b7af0e792c9c845edec8e62c84b",
"pass_ticket": pass_ticket,
"appmsg_token": appmsg_token,
"uin": "MjUyOTUxODMxOQ%3D%3D",
"wxtoken": "777",
}
# 使用post方法进行提交
content = requests.post(url, headers=headers, data=data, params=params).json()
# 提取其中的阅读数和点赞数
#print(content["appmsgstat"]["read_num"], content["appmsgstat"]["like_num"])
try:
readNum = content["appmsgstat"]["read_num"]
print(readNum)
except:
readNum=0
try:
likeNum = content["appmsgstat"]["like_num"]
print(likeNum)
except:
likeNum=0
try:
comment_count = content['comment_count']
print("true:" + str(comment_count))
except:
comment_count=0
print("error:"+str(comment_count))
# 歇3s,防止被封
time.sleep(3)
return readNum, likeNum,comment_count
# 最大值365,所以range中就应该是73,15表示前3页
def getAllInfo(url, begin):
# 拿一页,存一页
messageAllInfo = []
# begin 从0开始,365结束
data1["begin"] = begin
# 使用get方法进行提交
content_json = requests.get(url, headers=headers, params=data1, verify=False).json()
time.sleep(10)
# 返回了一个json,里面是每一页的数据
if "app_msg_list" in content_json:
for item in content_json["app_msg_list"]:
# 提取每页文章的标题及对应的url
url = item['link']
# print(url)
readNum, likeNum ,comment_count= getMoreInfo(url)
info = {
"title": item['title'],
"readNum": readNum,
"likeNum": likeNum,
'comment_count':comment_count,
"digest": item['digest'],
"date": getDate(item['update_time']),
"url": item['link']
}
messageAllInfo.append(info)
# print(messageAllInfo)
return messageAllInfo
# 写入数据库
def putIntoMogo(urlList):
host = "127.0.0.1"
port = 27017
# 连接数据库
client = MongoClient(host, port)
# 建库
lianTong_Wx = client['lianTong_Wx']
# 建表
wx_message_sheet = lianTong_Wx[sheetName]
# 存
for message in urlList:
wx_message_sheet.insert_one(message)
print("成功!")
def main():
# messageAllInfo = []
# 爬10页成功,从11页开始
for i in range(11,20):
begin = i * 5
messageAllInfo = getAllInfo(url, str(begin))
print("第%s页" % i)
putIntoMogo(messageAllInfo)
if __name__ == '__main__':
main()
另附一个读取数据库数据保存为execl的程序
import pymongo
from openpyxl import Workbook
excel_QA = Workbook() # 建立一个工作本
sheet = excel_QA.active # 激活sheet
sheet.title = '郑州市教工幼儿园' # 对sheet进行命名
sheet.cell(1, 1).value = '推送日期'
sheet.cell(1, 2).value = '推送时刻'
sheet.cell(1, 3).value = '标题'
sheet.cell(1, 4).value = '点赞数'
sheet.cell(1, 5).value = '阅读量'
# 郑州市教工幼儿园 郑州小哈佛建业贰号城邦幼儿园
# 郑州市实验幼儿园 河南省郑州市惠济区实验幼儿园
# 郑州市中原区汝河新区第二幼儿园
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["lianTong_Wx"]
mycol = mydb["郑州市教工幼儿园"]
count=2
for x in mycol.find():
sheet.cell(count, 1).value = x['date'].split(" ")[0]
sheet.cell(count, 2).value = x['date'].split(" ")[1]
sheet.cell(count, 3).value = x['title']
sheet.cell(count, 4).value = x['likeNum']
sheet.cell(count, 5).value = x['readNum']
count+=1
excel_QA.save("微信爬虫5.xlsx")#保存