一起学python-opencv十四(图像阈值化,图像缩放)
图像阈值化也可以叫做二值化,其实我们前面已经用过了很多次的cv2.threshold,另外就是cv2.inRange,这个主要用HSV颜色空间来分离出某一种颜色的区域。前面我们只用了几种阈值化的类型,那么这篇文章的开头,就让我们来认识一下其它的阈值化类型。

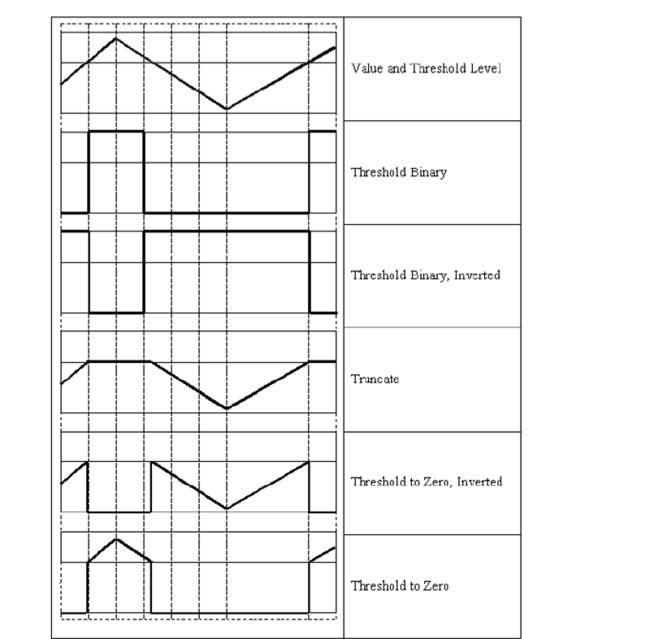
我觉得看图还是非常直观的,TRUNC就是设定一个阈值,高于这个阈值的话,就把值改为阈值这个值,当然这个maxVal就会直接被无视了。如果低于的话,就保持原来的值,TOZERO就是如果值低于阈值就变为0,高的保持,TOZERO_INV就是说如果值高于阈值变为0,低于保持,maxVal都是会被无视,但是这个参数肯定还是需要填的,不然就缺参数了。毕竟只有dst一个是用中括号括起来的,也就是只有dst是可选的。而且注意返回的是一个元组,需要用retval,dst分别来接收,retVal是阈值。
我们来分别试一下:
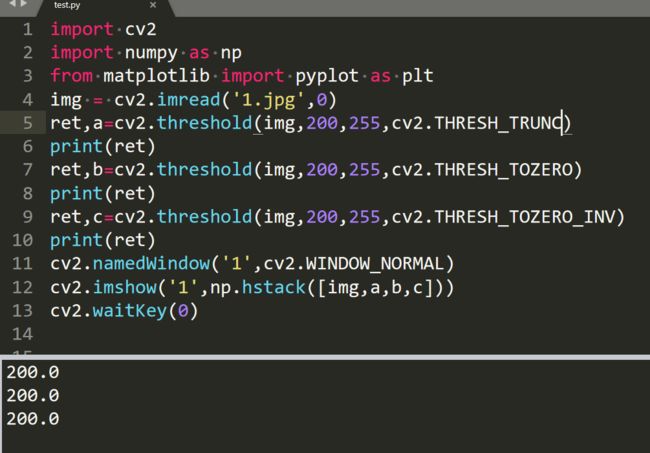
效果:
前面说的方法都是从cv2.threshold函数外面获得的,cv2.threshold还有根据直方图自动计算出阈值的两种方法:第一种是cv2.THRESH_OTSU。参考了https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_imgproc/py_thresholding/py_thresholding.html
在全局阈值处理中,我们使用主观值作为阈值,当然我们也可以计算一下图像的平均值或者中位数等其它统计特征然后作为输入。不过就有一个问题,我们如何知道我们选择的值是好还是不好?答案是,试凑法,一个一个去试,然后根据结果的好坏评判值得好坏。但考虑双峰图像(简单来说,双峰图像是直方图有两个峰值的图像)。对于该图像,我们可以将这些峰值中间的某一个值作为阈值,对吧?这就是Otsu二值化所做得事情。因此,简单来说,它会根据双峰图像的图像直方图自动计算阈值。(对于非双峰图像,二值化不准确。)
为此,使用了我们的cv2.threshold()函数,但传递了一个额外的标志cv2.THRESH_OTSU。对于阈值,只需传递零。然后算法找到最佳阈值并返回输出,retVal。如果未使用Otsu阈值,则retVal与您使用的阈相同。当然上面还不是原理,原理在下面。OTSU算法也叫大津法或最大类间方差法。

q1(t)和q2(t)分别是直方图累积数,P是直方图灰度值对应的数量,μ是被阈值分成的两个区间类的灰度值的期望,σ分别是两个区间灰度的方差,这样算的叫做最小加权类内方差,这个是官网给的数学原理。方差是表征数据信息量大小或者说数据分散程度的一个量,方差越大,数据信息量越大,数据越分散。最小化类内方差这种就是实现了分成的两个类的灰度的分散度最小,也就是比较接近了。我在网上还搜到了另一种计算方法。参考了https://www.cnblogs.com/xiaomanon/p/4110006.html


到目前为止和官方的做法还是一致的,不过下面就稍微不一样了。

这个等式其实蛮重要的。

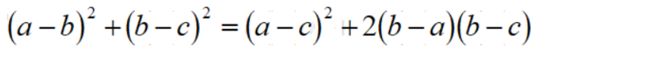
有点不知道它是怎么得出等式的,我这里计算的是只有当b=a=c的时候它们才会相等。可能是我的计算过程有疏漏或者是少考虑了什么。

假如那个等式是对的,那么其实最大类内方差的满足也就意味着满足了最小类内方差,因为它们的和σT的平方是不变的和k无关。

上面就是大概原理,当然其中还有一个问题没有解决,希望有大神在评论区指导一下我了。
我们来看一下代码:
我找了一张图片:

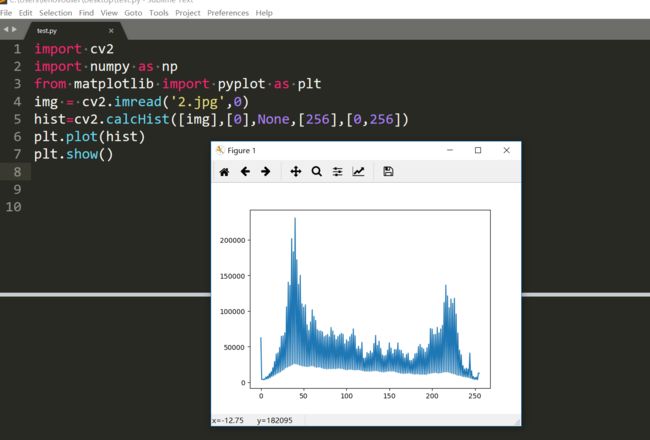
这个比较适合,因为有两个波峰。还有一个只有一个波峰的。
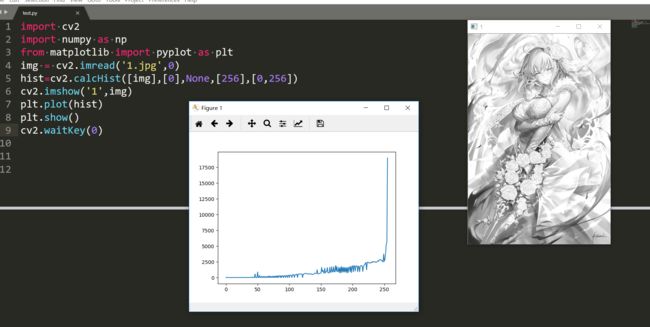
先来试一试单峰的。
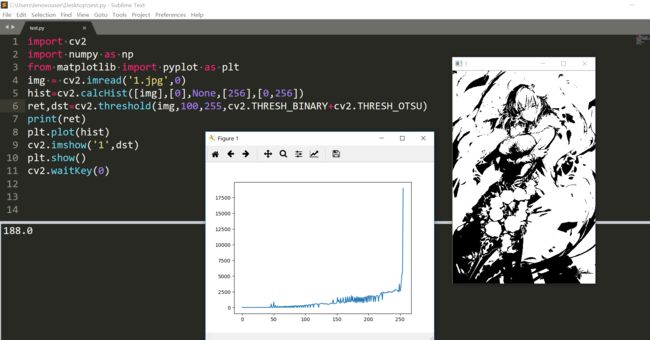
效果不怎么样,因为其实我们这张图都是偏白的,看到ret返回的是188而不是我们设定的100。
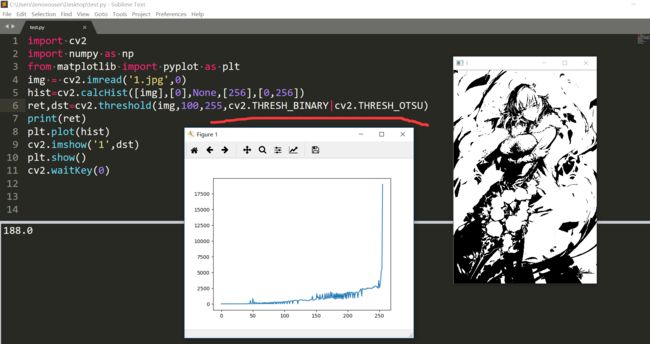
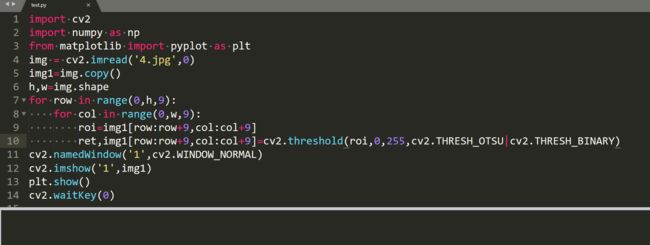
threshold输入二值化方式这个地方有点像泛洪填充的flags参数,应该有好几位,阈值选取方式和二值化方法应该是存在不同的位的,所以这里加和或操作都是可以的。
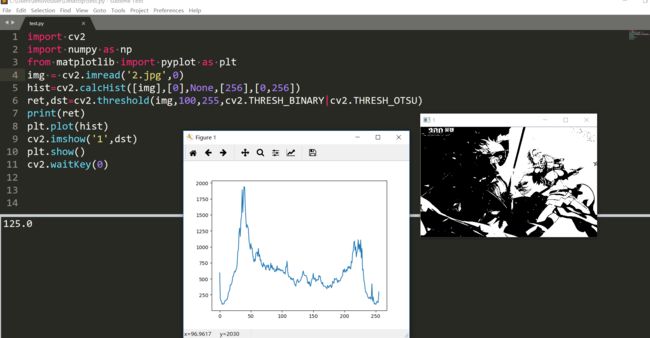
还不错,把黑贞的白贞的区域分得还是可以的。第二种方法是cv2.THRESH_TRIANGLE。参考https://blog.csdn.net/jia20003/article/details/53954092

上图的阈值也就是在160左右了。
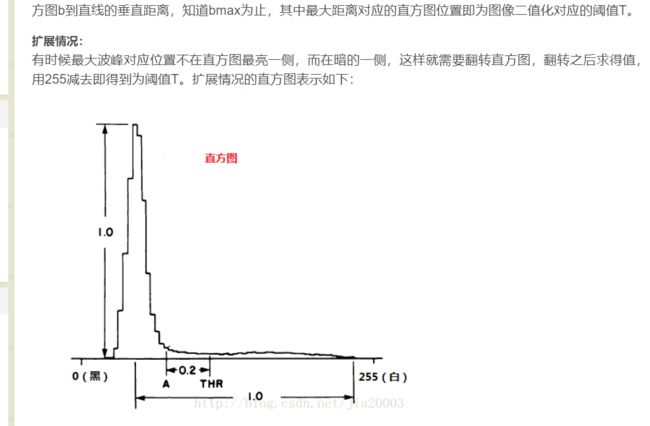

原理挺简单的,但是更基本的数学原理没有解释清楚,就是到底是根据什么数学方法得到的这个阈值呢?我们都来试验一下,这次我用的是
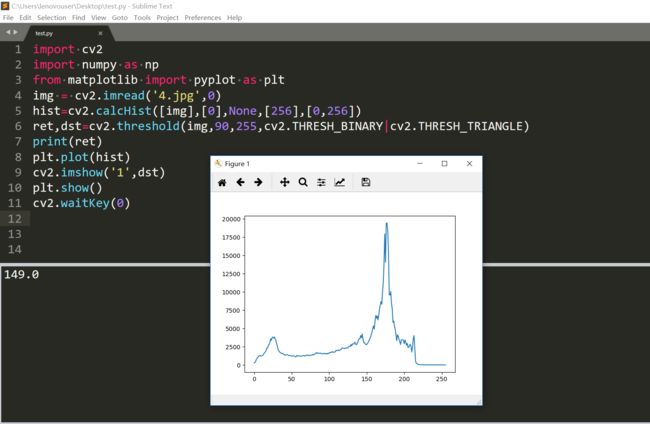
阈值是149,效果不是很好。主要还是照明太不均匀了。

那么otsu呢?阈值时111效果也不是很好。
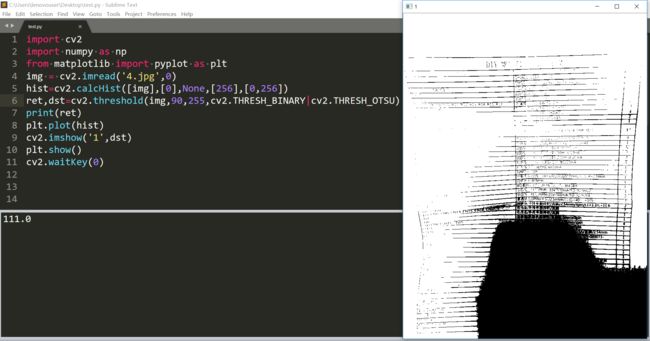
我用灰度值的期望作为阈值。
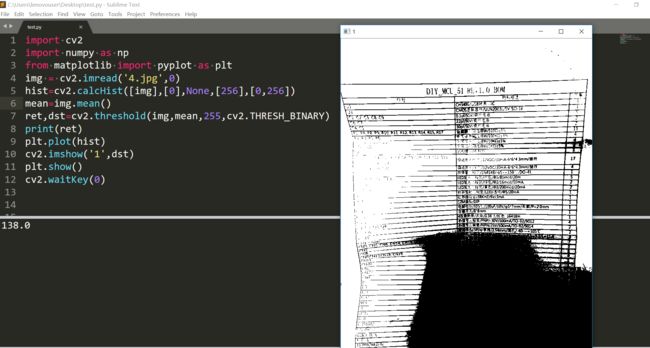
效果也不是很好。中值也不行。
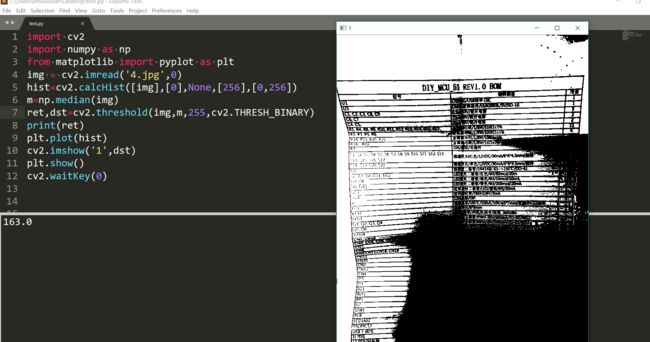
这个究其原因还是照明不均引起的。这个时候就需要我们的自适应阈值化出场了。自适应阈值有点像CLAHE,其实也是用一个一个小的矩形在图像上滑动,在每个小矩形内进行阈值化操作,不过它不是对图像直方图操作的,而是直接对图像操作的。

cv2.ADAPTIVE_THRESH_GAUSSIAN_C就是卷积核是高斯核而已。C是一个偏置量,阈值根据前面计算出来以后,还会减去这个值。块大小就是卷积核的阶数,必须是奇数。

自适应二值化的函数就是cv2.adaptiveThreshold。这个返回值是有一个dst,不返回阈值,因为返回阈值会有很多个,可能比较麻烦就不返回了。
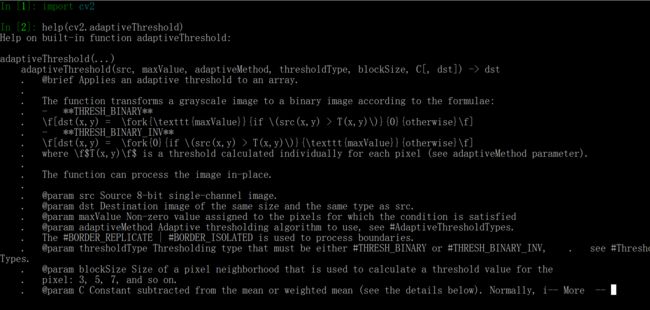
先用一下阈值采用均值的方法:
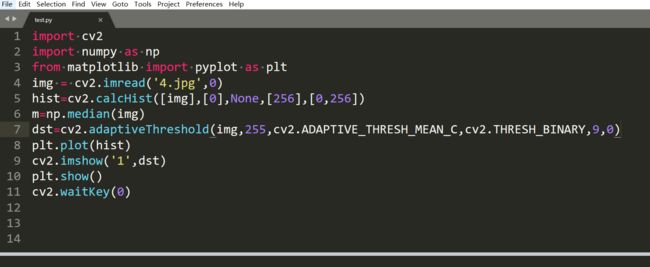

问题在于有些空白的地方也给显示黑的,这个是因为我的C是0,所以空白区域肯定还是会有区域要黑的。如果我把C变大一点,也就是说阈值减小,也就是说降低了成为255的门槛,本身那些白色区域的值都很接近,只是因为光照不均略有不同,很容易让所有的都显示为白色。
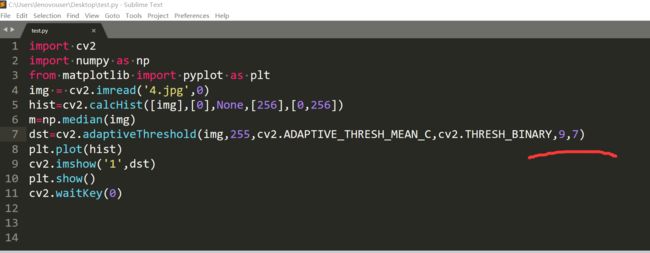
我把阈值降低7,就有了不错的效果了。

只不过右边的一些黑点没有去掉。我们再来试一试高斯核。
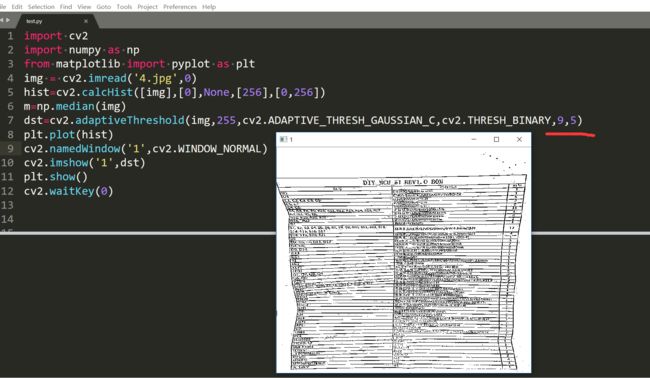
试了试C是5的效果比较好一些。我们还有一种处理空白的方法就是自己去处理。
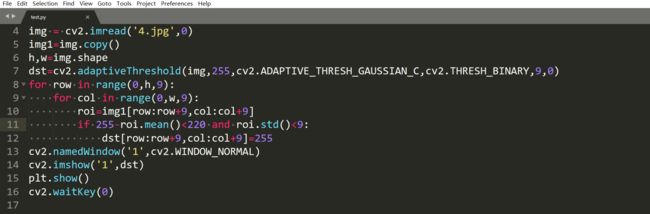
加一个均值核标准差的判断,这两个阈值是自己选的。

效果还算不错。所以其实我们还可以分块处理:
不过结果不算好。

还有
效果也不算很好。这样其实和自适应的方法就是少了一个C,这个C还是比较有用的。
图像缩放
参考了https://blog.csdn.net/william_hehe/article/details/79604082
https://blog.csdn.net/qq78442761/article/details/61425664
https://blog.csdn.net/chaipp0607/article/details/60780472
在画图中我们就曾经体会过图像的缩放。我们现在来看一看opencv如何实现。
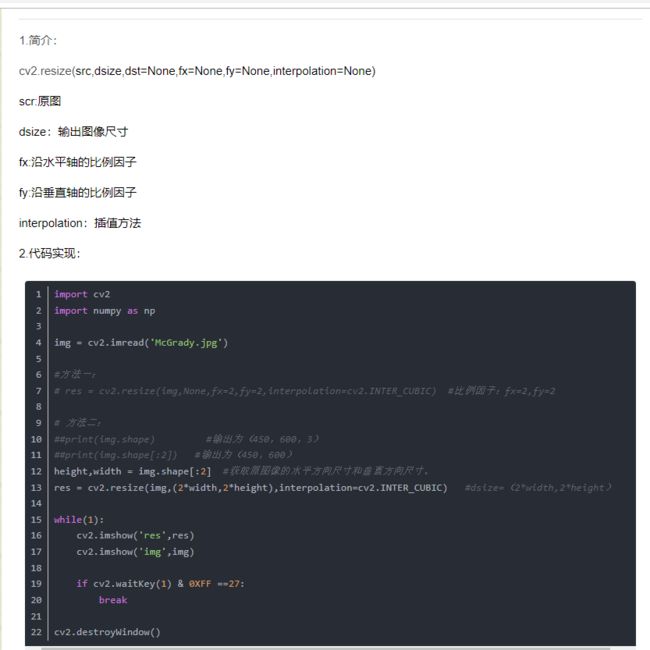

缩小的原理:

那么如果不能整除该怎么办呢?比如16%3!=0,我的猜想是先进行补全到可以整除,例如16就补到18,然后再进行区平均值的操作,怎么补全呢?就是用插值咯。放大还是比较好理解的,就是直接插值咯。
应该是我这个图片选的比较特别,所以看不出来插值方式的区别。
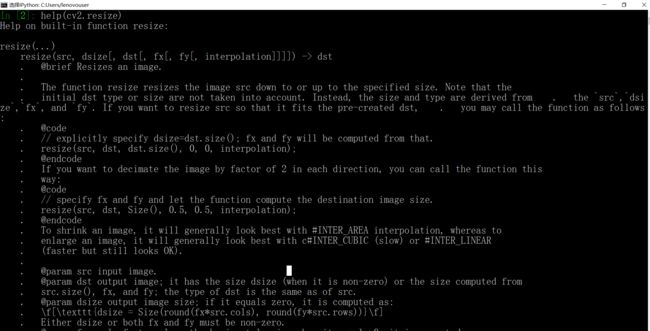
填了dsize就不要填fx,fy了,当然dszie必须得是非0才行。
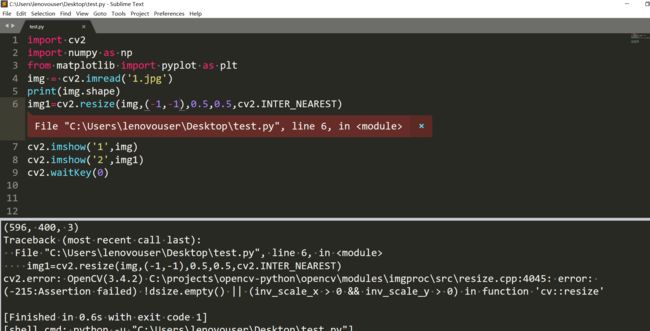
但是有要求都大于0,我是有点懵比了。
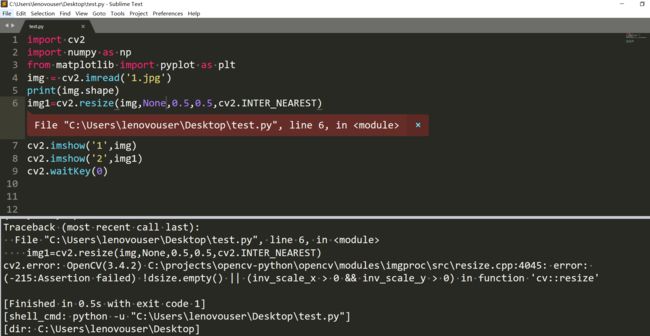
暂时不知道怎么用fx,fy来缩放图像。不过我们可以计算,直接给dsize。