Thanos组件基本介绍和如何接入监控平台
Thanos基本介绍
1.基本组件介绍
1.1thanos基础架构图
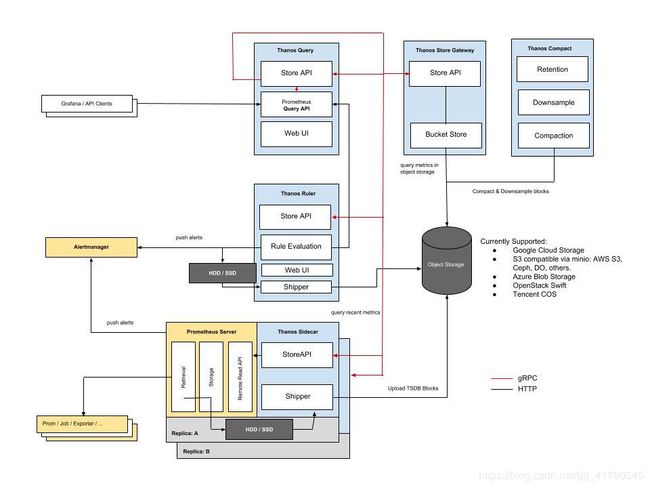
1.2引出thanos
在以往基于Prometheus的监控告警平台中Prometheus单例,导致query无法实现HA,alertmangager的HA也无法实现,Prometheus将数据存入本地磁盘,磁盘空间无法,无法支持历史数据的查询问题,数据量大时无法进行压缩,如果部署集群,查询数据去重问题又会出现,等等一系列的问题导致我们不得不寻找一个完整的解决方案,因此thanos的出现解决了上述问题。
1.3thanos基本组件
1.sidecar,边车组件
Thanos integrates with existing Prometheus servers through a Sidecar process, which runs on the same machine or in the same pod as the Prometheus server.
可以看出sidecar是内嵌于prometheus中,对外提供storeAPI。
->个人思考,thanos的sidecar组件和微服务中ServiceMesh的sidecar是否有相似之处。
2.store,存储组件
获取Prometheus生产的tsdb块,进行持久化,以支持历史数据查询。
3.query,查询组件
通过gRPC远程调用sidecar的storeAPI进行查询Prometheus的指标数据,并对外暴露一个查询API
4.ruler,全局告警规则组件
ruler基于query进行查询,进行全局告警。
5.compactor,压缩数据
prometheus本身是有压缩的功能的,在和thanos配合的时候必须关闭。由compactor组件进行压缩和下采样。以此节省一部分存储,并且通过下采样提供更快捷的查询能力。
1.4Sidecar
Thanos的sidecar组件与Prometheus实例一起部署,
它在Prometheus的远程读取API之上实现Thanos的Store API。这使Queriers可以将Prometheus服务器视为时间序列数据的另一个来源,而无需直接与其API对话。
在Prometheus每2小时生成一次TSDB块时,Sidecar将TSDB块上载到对象存储桶中。这使得Prometheus服务器可以以相对较低的保留时间运行,同时使其历史数据持久且可通过对象存储查询。
基本配置
$ prometheus \
storage.tsdb.max-block-duration=2h \
storage.tsdb.min-block-duration=2h \
web.enable-lifecycle
external_labels:
region: eu-west
monitor: infrastructure #thanos 查询中的指标
replica: A #prom server 和sidecar绑定的整体组件名称
$ thanos sidecar \
--tsdb.path "/path/to/prometheus/data/dir" #prom server存储tsdb的路径
--prometheus.url "http://localhost:9090" #prom server url
--objstore.config-file "bucket.yml" #持久化存储配置文件
示例内容bucket.yml:
type: GCS
config:
bucket: example-bucket
1.5query
查询步骤:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ltavlqCs-1587606362815)(https://thanos.io/img/querier.svg)]
1.通过PromQL 查询指标(通过gRPC调用sidecar组件的storeAPI)
2.filter过滤
3.fanout 输出到store api
4.merge 进行合并多个prom server实例上的数据
5.deduplicate 进行数据去重
query组件启动命令
$ thanos query \
--http-address "0.0.0.0:9090" #http查询端口
--query.replica-label "replica" #对应了external_labels中的monitor
--store ":" #存储url
--store ":"
例如:
up{job=“prometheus”,env=“2”}使用此选项查询指标,我们将获得2个结果:
- up{job=“prometheus”,env=“2”,cluster=“1”} 1
- up{job=“prometheus”,env=“2”,cluster=“2”} 1
没有此副本标志(重复数据删除已关闭),我们将获得3个结果:
- up{job=“prometheus”,env=“2”,cluster=“1”,replica=“A”} 1
- up{job=“prometheus”,env=“2”,cluster=“1”,replica=“B”} 1
- up{job=“prometheus”,env=“2”,cluster=“2”,replica=“A”} 1
查询API概述
例如:http://localhost:29090/api/vi/query?query=up&dedup=true&partial_response=true
API参数说明
| http参数 | 类型 | 默认 | 例 | 说明 |
|---|---|---|---|---|
| replicaLabels | []string | query.replica-label 标志(默认值:空)。 | replicaLabels=replicaA&replicaLabels=replicaB | 重复数据删除副本标签 |
| dedup | Boolean | 正确,但效果取决于query.replica配置标志。 | 1, t, T, TRUE, true, True 为“真” | 是否删除重复数据 |
| max_source_resolution | Float64/time.Duration/model.Duration | step / 5或0if query.auto-downsampling为false(默认值:False)。 | 5m | 自动采样,如5m->我们将使用最多5m的下采样。 |
| partial_response | Boolean | query.partial-response 标志(默认值:True) | 1, t, T, TRUE, true, True 为“真” | 部分响应策略,如果为true,则所有将不可用的storeAPI(因此不返回任何数据)不会导致查询失败,而是返回警告 |
还有自定义响应字段,可以自行拓展。
1.6Ruler
Ruler启动命令:
$ thanos rule \
--data-dir "/path/to/data" #存储目录
--eval-interval "30s" #每30s进行轮询
--rule-file "/path/to/rules/*.rules.yaml" #规则文件
--alert.query-url "http://0.0.0.0:9090" #alertmanager的url # This tells what query URL to link to in UI.
--alertmanagers.url "alert.thanos.io" \
--query "query.example.org" \
--query "query2.example.org" \
--objstore.config-file "bucket.yml" \
--label 'monitor_cluster="cluster1"' #需要的label,进行HA
--label 'replica="A"'
标尺具有概念上的折衷,对于大多数用例而言可能并不有利。主要的折衷是它对查询可靠性的依赖。对于Prometheus,由于评估是本地的,因此不太可能出现警报/记录规则评估失败。
对于Ruler,读取路径是分布式的,因为Ruler最有可能查询Thanos Querier,后者从远程商店API获取数据。
这意味着查询失败的可能性更高,这就是为什么在警报不可用以及警报不可用期间制定明确策略的原因。
Ruler默认使用abort对警报保持部分响应
为确保警报有效,必须监视标尺并从位于同一群集中的另一个Scraper(Prometheus + Sidecar)发出警报。也就是当某一个Ruler失效,那么需要从另一个集群的Ruler中发出告警,保证分区容错性。
其中:
要提醒的最重要指标是:
thanos_alert_sender_alerts_dropped_total。如果大于0,则表示未将由Rule触发的警报发送到alertmanager,这可能表明存在连接,不兼容或配置错误的问题。
prometheus_rule_evaluation_failures_total。如果大于0,则表示该规则无法评估,这将导致规则缺口或可能被忽略的警报。此度量标准可能表明您使用的queryAPI端点存在问题。如果发生的时间长于警报阈值,请对此进行严重警报。 strategy标签会告诉您失败是否来自允许部分响应的规则。
prometheus_rule_group_last_duration_seconds < prometheus_rule_group_interval_seconds如果差异很大,则意味着规则评估花费的时间超过了计划的时间间隔。它可能表明您的查询后端(例如Querier)花费了太多时间来评估查询,即,它不够快,无法满足规则。这可能表明存在其他问题,例如StoreAPis速度慢或规则中的查询表达式过于复杂。
thanos_rule_evaluation_with_warnings_total。如果您选择将规则和警报的部分响应策略的 值设置为“警告”,则该指标将告诉您有多少评估最终带有某种警告。要查看实际警告,请参阅警告日志级别。这可能表明这些评估返回了部分响应,并且可能不准确。
外部标签:它是强制性的添加一定的外部标签,以显示标尺原点(如label='replica=“A”'或cluster)。否则将无法运行多个标尺副本,从而导致压缩期间发生冲突。配置外部标签来实现Ruler的HA
例如:
标尺在群集中mon1,我们在群集中有普罗米修斯eu1
默认情况下,我们可以尝试使用一致的标签,因此我们可以cluster=eu1使用Prometheus和cluster=mon1Ruler。
我们配置ScraperIsDown警报,以监视来自work1群集的服务。
触发此警报后,ScraperIsDown{cluster=mon1}由于外部标签始终会替换源标签,因此会产生此警报。
这有效地删除了重要的元数据,并且在不退回手动查询的情况下,无法准确分辨cluster出ScraperIsDown警报发现的问题。
对于HA中的Ruler,您需要确保具有以下标签设置:
标识HA组标尺的标签和每个标尺实例具有不同值的副本标签,例如: cluster=“eu1”, replica="A"和cluster=eu1, replica="B"使用–label标志。
在发送给alermanager之前需要删除的标签,以使alertmanager重复删除警报,例如 --alert.label-drop=“replica”。
1.7 store
进行外部存储
1.8compactor
对外部存储的数据进行压缩,如:对多个小的block进行合并。