OpenCV - 车牌识别新手入门级讲解
目录
0、引言
1、MFC中的车牌显示
2、车牌定位
3、字符提取
4、文字识别
5、文字预测
0、引言
第一次使用OpenCV完成一个完整的功能,有所收获,特此记录。
这篇博客中的车牌识别功能比较简单,只能识别一般的蓝色车牌,只能识别拍摄较为清楚的车牌。以后可以在此基础上实现更加高级的功能,比如识别较为糟糕环境中的车牌,同时识别多个车牌,识别黄色和绿色车牌,识别2行车牌等功能。
本文实现参考一个开源的EasyPR项目https://www.cnblogs.com/subconscious/p/4013591.html。以后的功能可以参考此博客。
本文中会贴出代码,完整工程下载(CSDN上要积分......自动设置的):https://download.csdn.net/download/qq_41828351/11140570
没有积分的小伙伴可以去github,代码下载:(文件大小超过100M没法上传......)
英文和字母的识别正确率比较高,中文字符的准确率有待提高,小伙伴们可以自行修改ANN网络训练提高正确率:
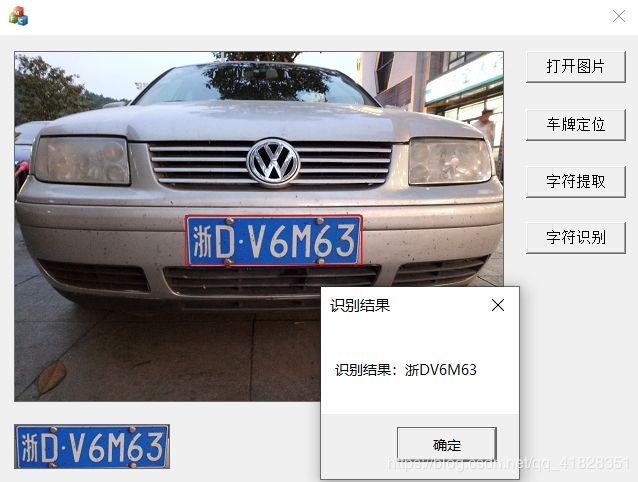
1、MFC中的车牌显示
MFC中的文件打开是在CFileDialog类下面,之前博客中有将Mat格式转化成CImage格式,由于显示存在问题,这里将Mat转化成为CvvImage。
void CEasyPRDlg::OnBnClickedBtnOpen()
{
CFileDialog dlg(TRUE);
dlg.m_ofn.lpstrTitle = "打开图像"; //文件打开对话框
//文件过滤器
dlg.m_ofn.lpstrFilter = "JPG Files(*.jpg)\0*.jpg\0All Files(*.*)\0*.*\0\0";
if (IDCANCEL == dlg.DoModal()) //弹出对话框,如果取消则直接返回
return;
CString strFileName = dlg.GetPathName(); //获取文件路径+文件名
string path(strFileName.GetBuffer());
m_src = imread(path);
m_showimg = m_src.clone();
drawImg();
}
//格式转换Mat2CvvImage
void CEasyPRDlg::showMatImg(Mat & m_showimg, UINT id)
{
IplImage img2 = m_showimg; // Mat -> IplImage
IplImage *img;
img = &img2;
CDC *pDC;
CRect rect;
int TempH, TempW;
float t;
//获得图像显示区的大小
GetDlgItem(id)->GetClientRect(&rect);
DrawHeight = rect.bottom - rect.top; //绘图框的高、宽
DrawWidth = rect.right - rect.left;
//根据画的大小,以应当比例完全显示出来
TempH = img->height;
TempW = img->width;
PicWidth = TempW;
PicHeight = TempH;
//如果图片大小大于矩形框
if (PicWidth > DrawWidth)
{
t = float(DrawWidth) / float(PicWidth);
TempW = DrawWidth;
TempH = (int)(t*(float)PicHeight);
}
if (TempH > DrawHeight)
{
t = float(DrawHeight) / float(TempH);
TempH = DrawHeight;
TempW = (int)(t*(float)TempW);
}
rect.SetRect(1, 1, DrawWidth - 1, DrawHeight - 1); //全屏显示
pDC = (CDC*)GetDlgItem(id)->GetDC(); //获取图片控件的设备上下文和客户区
CvvImage tm_image; //m_image
tm_image.CopyOf(img);
tm_image.DrawToHDC(pDC->GetSafeHdc(), rect);
tm_image.Destroy();
}2、车牌定位
车牌定位是车牌识别中难度较高的步骤,阅读EasyPR中的项目解读可以知道大概有两种方法:
1、使用Sobel算子边缘检测,闭运算,轮廓检测,判断轮廓是否为车牌,SVM对车牌进一步分类,仿射变换(纠正车牌位置),文字提取,ANN文字识别。
2、HSV空间中对车牌进行分割,轮廓检测,判断轮廓是否为车牌,文字提取,ANN文字识别。
上述的第二种方法相对来说较为简单,步骤也是被简过的步骤,因此比较适合新手学习,本工程也就用第二种方法练手。
由于HSV空间的特殊性(不懂HSV的同学可以阅读HSV参考文章),将普通的BGR图像转化到HSV空间中进行分割。
分割这边用到了inRange方法,inRange方法类似于threshold方法,但是其可以对单通道处理,也可以对多通道进行处理。
void inRange(InputArray src, InputArray lowerb, InputArray upperb, OutputArray dst);Mat CEasyPRDlg::HSVSeg(Mat &RGBsrc)
{
Mat hsv;
cvtColor(RGBsrc, hsv, CV_BGR2HSV); //注意这边是bgr BGR转为HSV
Mat imgHSV[3]; //存储三通道的数组
split(hsv, imgHSV); //分割为H S V 三通道
//inRange
cv::inRange(imgHSV[0], Scalar(94), Scalar(115), imgHSV[0]);
cv::inRange(imgHSV[1], Scalar(90), Scalar(255), imgHSV[1]);
cv::inRange(imgHSV[2], Scalar(36), Scalar(255), imgHSV[2]);
cv::bitwise_and(imgHSV[0], imgHSV[1], imgHSV[0]); //通道合并
return imgHSV[0];
}效果如下:可以很清楚的看出,蓝色的部分被扣了出来。所以本方法如果遇到蓝色的车子就完了,估计整个车都被分割进来了。

分割完成之后就要对车牌进行定位,也是较为复杂的部分。
1、预处理。预处理部分首先对白色噪点进行了清除,防止之后出现多余的无效轮廓;然后将图像做闭运算,除掉白色车牌区域的文字不连接部分。效果如下:




2、轮廓查找。遍历所有查找到的矩形块,寻找最小的包围矩形,这边接触到可旋转矩形RotatedRect和minAreaRect(Mat)方法,然后找到最大的矩形块。为什么功能比较简单就体现在这里,这里只能找到面积最大的矩形作为车牌。找到最大面积的旋转矩形之后用boundingRect(Mat)方法找到正常矩形,作为分割出的矩形。
3、仿射变换。如果上述步骤得到的矩形的高大于宽,那么就需要将该矩形进行旋转90度。(本工程图像比较简单该步骤可以不要)
4、最后需要将车牌剪裁出来。之前一般用的是提取ROI的方法,这边又学习到了getRectSubPix()方法。为什么要用这个方法呢?因为矩形不一定是普通的矩形,如果是旋转矩形的话,用ROI提取的方法就有问题了,getRectSubPix方法中的参数,矩形中心也是旋转矩形中特有的。
Mat CEasyPRDlg::HSVGetPlate(Mat & img, Mat & src, cv::Rect & rect)
{
/*****************************图像预处理**********************************/
Mat cont;
resize(img, cont, Size(600, 400)); //为什么要resize呢,因为下面要卷积运算,减小尺寸可以加速运算,(速度差不多,可以删除)
clearHorizon(cont, 80); //清除横向白色噪点,低于80个白色像素则清除,
Mat element = getStructuringElement(MORPH_RECT, Size(15, 15));
morphologyEx(cont, cont, MORPH_CLOSE, element); //闭运算,去除黑色不连通的区域
medianBlur(cont, cont, 5); //中值滤波
resize(cont, cont, img.size(), 0, 0, CV_INTER_CUBIC); //回复源图像大小
/******************************轮廓查找***********************************/
vector> cntr;
findContours(cont, cntr, CV_RETR_EXTERNAL, CV_CHAIN_APPROX_NONE);
int plateId = 0;
double maxArea = 0;
vector>::iterator itr = cntr.begin();
int id = 0;
while (itr !=cntr.end())
{
RotatedRect mr = minAreaRect(Mat(*itr));
int area = (int)(mr.size.height*mr.size.width); //查找面积最大的矩形
if (area > maxArea)
{
maxArea = area;
plateId = id;
}
id++;
itr++;
}
Rect w_r = boundingRect(Mat(cntr[plateId])); //计算轮廓的垂直边界最小矩形
/*****************************仿射变换************************************/
rect = w_r;
RotatedRect rRect = minAreaRect(cntr[plateId]);
float r = (float)rRect.size.width / (float)rRect.size.height;
float angle = rRect.angle;
if (r < 1) angle += 90; //如果宽小于高,那么就旋转90度
Mat rotMat = getRotationMatrix2D(rRect.center, angle, 1); //得到旋转矩阵
Mat img_rotated;
warpAffine(src, img_rotated, rotMat, src.size(), CV_INTER_CUBIC); //仿射变换,对倾斜过大的车牌进行调整
Size rect_size = rRect.size;
if (r < 1)
{
int temp = rect_size.width;
rect_size.width = rect_size.height;
rect_size.height = temp;
}
/********************************图像裁剪***********************************/
Mat img_crop;
getRectSubPix(img_rotated, rect_size, rRect.center, img_crop); //裁剪车牌区域图像
return img_crop;
} 3、字符提取
字符提取也是车牌识别中较为困难的部分,尤其是中文字符的提取。英文字符是一体的,一般可以用findCounters直接去找到轮廓,但是中文字符有偏旁部首等,很容易分到不同的轮廓之中去。EasyPR中提供了很好的想法。(大佬就是大佬,要学会像大佬一样思考)。
字符的提取主要分为几个步骤:
1、清除铆钉。清除铆钉是根据黑白交界的个数来判断的,如果交界次数较少,那么就是铆钉。反之,文字区域黑白交界次数是比较多的区域
2、提取字符轮廓。
3、验证轮廓大小。验证的是矩形的宽高和比例,宽高和比例可以自行调整
4、按照X轴坐标排序 。之前得到的矩形是乱序的,通过从左往右排列可以得到文字序列
5、找到中文字符后的第一个英文字符。之前说到中文字符的矩形框提取是存在问题的,那么就找到中文字符后的第一个英文字符,验证该字符的大小和位置,位置一般在车牌的1/7到2/7区域内。
6、从找到的字符位置开始向前推一个矩形轮廓得到中文字符的位置。得到英文字符,将矩形框位置向左推进得到中文
7、依次加入其他的字符轮廓
具体的实现方式和实现步骤在以下代码中有所体现。至此为止,字符就全部被提取出来了。

void CEasyPRDlg::SegmentChars(Mat img_input, vector& resultVec)
{
resultVec.clear(); //存储分割矩形结果
resize(img_input, img_input, Size(136, 36)); //将输入图像改成136*36,这是一个统计大小
Mat gray;
cvtColor(img_input, gray, CV_RGB2GRAY);
threshold(gray, gray, 0, 255, CV_THRESH_OTSU + CV_THRESH_BINARY); //使用OTSU二值化
clearMaoDing(gray); //清除铆钉
Mat img_contours;
gray.copyTo(img_contours);
//提取字符轮廓
vector> contours;
findContours(img_contours, contours, CV_RETR_EXTERNAL, CV_CHAIN_APPROX_NONE);
//遍历所有轮廓验证大小是否符合要求
vector>::iterator itc = contours.begin();
vector vecRect;
while (itc != contours.end())
{
Rect mr = boundingRect(Mat(*itc)); //获得最小包围矩形
if (verifyCharSizes(mr)) //验证轮廓大小,如符合就压入栈
{
vecRect.push_back(mr);
}
++itc;
}
vector sortedRect(vecRect);
sort(sortedRect.begin(), sortedRect.end(), //对矩形的x坐标排序
[](const Rect& r1, const Rect& r2) { return r1.x < r2.x; });
int specIndex = getSpecificRect(sortedRect); //计算中文字符后的第一个字符
Rect chineseRect = getChineseRect(sortedRect[specIndex]); //推测第一个中文字符的位置
vector newSortedRect;
newSortedRect.push_back(chineseRect); //将中文字符压入栈
reBuildRect(sortedRect, newSortedRect, specIndex); //将其他6个字符压入栈
for (int i = 0; i < newSortedRect.size(); i++) //遍历新的矩形数组,将矩形区域全部提取出来
{
Rect mr = newSortedRect[i];
Mat roi(img_input, mr);
Mat newRoi;
cvtColor(roi, roi, CV_BGR2GRAY);
newRoi = preprocessChar(roi);
resultVec.push_back(newRoi);
/*********************用来输出分割结果***************************/
//if (true)
//{
// char buf[256] = { 0 };
// CString str; //获取系统时间
// CTime tm;
// tm = CTime::GetCurrentTime();
// str = tm.Format("%Y_%m_%d_%H_%M_%S");
// sprintf_s(buf, "%s_%d", str.GetBuffer(), i);
// string ss(buf);
// ss += ".jpg";
// imwrite(ss, newRoi);
//}
}
}
bool CEasyPRDlg::clearMaoDing(Mat & img)
{
//清除铆钉是根据黑白交界的个数来判断的,如果交界次数较少,那么就是铆钉。反之,文字区域黑白交界次数是比较多的
std::vector fJump;
int whiteCount = 0; //存储的所有的白点的个数
const int x = 7;
Mat jump = Mat::zeros(1, img.rows, CV_32F); //jump中存储的由白到黑或者由黑到白的交界的个数
for (int i = 0; i < img.rows; i++) {
int jumpCount = 0;
for (int j = 0; j < img.cols - 1; j++) {
if (img.at(i, j) != img.at(i, j + 1)) jumpCount++;
if (img.at(i, j) == 255) {
whiteCount++;
}
}
jump.at(i) = (float)jumpCount;
}
int iCount = 0;
for (int i = 0; i < img.rows; i++) {
fJump.push_back(jump.at(i));
if (jump.at(i) >= 16 && jump.at(i) <= 45) {
// jump condition
iCount++;
}
}
// if not is not plate
if (iCount * 1.0 / img.rows <= 0.40) {
return false;
}
if (whiteCount * 1.0 / (img.rows * img.cols) < 0.15 ||
whiteCount * 1.0 / (img.rows * img.cols) > 0.50) {
return false;
}
for (int i = 0; i < img.rows; i++) {
if (jump.at(i) <= x) { //交界小于7
for (int j = 0; j < img.cols; j++) {
img.at(i, j) = 0;
}
}
}
return true;
}
bool CEasyPRDlg::verifyCharSizes(Rect mr)
{
float error = 0.7f; //误差率
float aspect = 20.0f / 30.0f; //宽高比
//字符1的尺寸比较特殊,他的比例大概为0.2左右
float rmin = 0.05f; //最小宽高比
float rmax = aspect + aspect * error; //最大宽高比
float charAspect = (float)mr.width / (float)mr.height;
//设置最小和最大高度
float minHeight = 10.f;
float maxHeight = 35.f;
//判断矩形的宽高是否在范围内,比例是否在范围内
if (mr.height >= minHeight && mr.height <= maxHeight && charAspect >= rmin && charAspect <= rmax)
{
return true;
}
else
{
return false;
}
}
int CEasyPRDlg::getSpecificRect(vector& vecRect)
{
vector xpositions;
int maxHeight = 0;
int maxWidth = 0;
for (size_t i = 0; i < vecRect.size(); i++) { //计算最大的宽高
if (vecRect[i].height > maxHeight) {
maxHeight = vecRect[i].height;
}
if (vecRect[i].width > maxWidth) {
maxWidth = vecRect[i].width;
}
}
int specIndex = 0; //计算中文字符后的第一个英文字符
for (size_t i = 0; i < vecRect.size(); i++) {
Rect mr = vecRect[i];
int midx = mr.x + mr.width / 2;
// use known knowledage to find the specific character
// position in 1/7 and 2/7
if ((mr.width > maxWidth * 0.8 || mr.height > maxHeight * 0.8) &&//该字符在整个车牌的1/7和2/7之间
(midx < int(136 / 7) * 2 &&
midx > int(136 / 7) * 1)) {
specIndex = i;
}
}
return specIndex;
}
Rect CEasyPRDlg::getChineseRect(Rect rectSpe)
{
int height = rectSpe.height;
float newwidth = rectSpe.width * 1.10f;
int x = rectSpe.x;
int y = rectSpe.y;
//int newx = x - int(newwidth * 1.10f); //这边做一点改动
int newx = x - int(newwidth * 1.25f); //将中文字符后的第一个矩形向前推一定距离得到新的矩形
newx = newx > 0 ? newx : 0;
Rect a(newx, y, int(newwidth), height);
return a;
}
int CEasyPRDlg::reBuildRect(const vector& vecRect, vector& outRect, int specIndex)
{
int count = 6;
for (size_t i = specIndex; i < vecRect.size() && count; ++i, --count) { //将后面6个矩形压入栈
outRect.push_back(vecRect[i]);
}
return 0;
} 4、文字识别
提取除了文字,那就要对提取出的文字进行识别,本次工程中用的是人工神经网络进行识别的。要注意车牌中是没有字母I和O的。文字的识别模型和数字字母的模型是两个模型。
像我这么暴躁的脾气竟然仔细的讲到这里了。我真的快忍不住了。
模型建立:每个文字或者是字符的样本个数大概为50个(其实有很多,但是训练量太大!样本在本文工程中都能下载到)。由于两个模型的建立方式十分相似,所以这边只讲中文字符的模型训练。
训练集的路径是这样设置的,每种样本都在一个文件夹下。那么就根据该文件夹的文件名来对数据集进行分类。下面的getFileName方法就是用来获取文件路径的上一层文件名的(不要问我为什么,抄的,不重要)。
因为上面分割出的字符全是20*20的,所以这边把训练集全部设置成为20*20,因此特征个数为400,有31个省直辖市的数据,所以总共有31个分类。 至此训练完成,得到下面这个文件:
![]()
准确度不高,勉强能用:  。有兴趣的同学自己调参,或者增加训练数量训练自己的模型。
。有兴趣的同学自己调参,或者增加训练数量训练自己的模型。
这么多文件路径怎么获得?数据集下有个bat文件,点击就可以生成路径了,(可以看看路径中有什么,前面有几行是要删掉的),因此,代码中读取的path也就是这么来的
![]()
static const string kChars[] = {
"zh_cuan", //川
"zh_e",
"zh_gan",
"zh_gan1",
"zh_gui",
"zh_gui1",
"zh_hei",
"zh_hu",
"zh_ji",
"zh_jin",
"zh_jing",
"zh_jl",
"zh_liao",
"zh_lu",
"zh_meng",
"zh_min",
"zh_ning",
"zh_qing",
"zh_qiong",
"zh_shan",
"zh_su",
"zh_sx",
"zh_wan",
"zh_xiang",
"zh_xin",
"zh_yu" ,
"zh_yu1",
"zh_yue",
"zh_yun",
"zh_zang",
"zh_zhe",
};
const int numCharacters = 31; //样本的种类,也是最后输出的特征个数
void train(Mat trainData, Mat classes, int nLayers);
string getFilename(string s);
//void Vector2Mat(vector>src, Mat dst);
int main()
{
ifstream in("path.txt");
string path;
vector labels;
Mat trains;
int num = 0;
//读入图像和对应的图像标签
while (getline(in, path)) //逐行读取
{
num++;
Mat img = imread(path, IMREAD_GRAYSCALE); //读取灰度图
resize(img, img, Size(20, 20)); //样本的大小全部变成20*20
Mat im = img.reshape(1, 1); //转成1行
trains.push_back(im); //存储到trains中
string name = getFilename(path); //读取name
for (int i = 0; i < numCharacters; ++i) { //循环判断上一级路径名称
if (name == kChars[i]) {
labels.push_back(i); //根据名称来给标签贴值
break;
}
}
}
Mat trainData;
trains.convertTo(trainData,CV_32FC1); //ANN中的输入数据要Float类型
Mat classes(labels); //将标签转换成矩阵
//进行模型训练
cout << "开始训练..." << endl;
/*******************读下一行的注释***********************/
//train(trainData, classes, 62); //训练,注意运行第一次这行不用注释,其他时候这行要注释掉,不然就又训练一次了
cout << "训练完成...done" << endl;
Ptr ann = ANN_MLP::load("ann_chars.xml"); //读取模型
//使用模型进行预测
Mat p;
int count = 0;
p.create(1, 400, CV_32FC1); //测试的样本大小为1*400
for (int i = 0; i < trainData.rows; ++i)
{
p = trainData.row(i); //这边没有弄新的测试集,就用训练集当测试集,取出某一行
Mat res; //训练结果
ann->predict(p, res); //所有的概率都存在res中
float max = -1;
int index;
for (int i = 0; i < 31; ++i) //计算最大的概率,最为最后的输出值
{
if (res.at(0, i) > max)
{
max = res.at(0, i);
index = i;
}
//printf("%.2f ", res.at(0, i));
//cout << res.at(0, i) << " ";
}
cout << endl;
cout << " 预测结果: " << index << "---原本标签 : " << classes.at(i) << endl;
if (index == classes.at(i)) {
count++; //做统计
}
}
cout << "=========================================================================" << endl;
cout << "训练的准确度为:" << endl;
cout << count / float(num) * 100 << "% " << endl;
getchar();
}
/************************************************************************************************
* 说明:
* Mat TrainData 训练数据(N*M, 每行为一个样本的特征向量)
矩阵中每个元素的类型为float 32bits
* Mat classes 训练数据的类数 (列向量N*1,和输入训练样本的个数相等),
向量中每个元素的类型为int 32bits
* int nlayers 三层神经网络影藏层节点的个数
*************************************************************************************************/
void train(Mat trainData, Mat classes, int nLayers)
{
Mat layers(1, 3, CV_32SC1);
layers.at(0) = trainData.cols; //输入层的特征个数等于样本的列数,也就是400
layers.at(1) = nLayers; //隐藏层个数,自己设定
layers.at(2) = numCharacters; //输出层特征个数也就是样本分类数
//one-hot matrix
Mat trainClasses;
trainClasses.create(classes.rows, numCharacters, CV_32FC1);
for (int i = 0; i < trainClasses.rows; i++) //转换为独热矩阵
{
for (int k = 0; k < trainClasses.cols; k++)
{
if (k == classes.at(i))
trainClasses.at(i, k) = 1;
else
trainClasses.at(i, k) = 0;
}
}
Ptr ann = ml::ANN_MLP::create();
ann->setLayerSizes(layers); //设置层数
ann->setActivationFunction(ml::ANN_MLP::SIGMOID_SYM); //设置激活函数
ann->setTrainMethod(cv::ml::ANN_MLP::BACKPROP, 0.1, 0.1); //反向传播参数
ann->setTermCriteria(cv::TermCriteria(TermCriteria::MAX_ITER, 1000, 1e-6)); //停止条件
cv::Ptr TrainData = TrainData::create(trainData, ml::ROW_SAMPLE, trainClasses); //制作训练集
ann->train(TrainData); //训练
//ann->train(trainData, ml::ROW_SAMPLE, trainClasses); //上面不制作训练集也可以这么训练
ann->save("ann_chars.xml"); //保存模型
}
/*=================================================================================*
从文件路径中文件名的上一级目录名称
*==================================================================================*/
string getFilename(string s)
{
char sep = '\\';
size_t i = s.rfind(sep, s.length()); //反向查找分割符
s = s.substr(0, i);
i = s.rfind(sep, s.length()); //反向查找分割符
if (i != string::npos) {
string fn = (s.substr(i + 1, s.length() - i));
size_t j = fn.rfind('.', fn.length());
if (i != string::npos)
return fn.substr(0, j); //截取字符串
else
return fn;
}
else
return "";
} 5、文字预测
有了模型,那就对提取出的文字进行预测了。预测也是分为两部分,第一个是对中文预测,第二个是对剩下的英文数字字符进行预测,然后将预测的结果用一个string叠加起来。
string CEasyPRDlg::DoAnn(vector& resultVec)
{
vector::iterator itr = resultVec.begin(); //取第一个中文字符进行预测
Mat img = itr->clone();
vector feature = img.reshape(1, 1); //转换为一列
Mat ch(feature);
ch = ch.t(); //这边要对数据进行转置,得到一行
int ch_index = PredictCH(ch); //预测得到中文字符索引
string str_CH = kChars_CH[ch_index]; //根据索引得到字符
string str_CHAR; //英文字符的string
++itr; //迭代器迭代到下一个英文字符
while (itr != resultVec.end())
{
img = itr->clone();
feature = img.reshape(1, 1);
Mat ch2(feature);
ch2 = ch2.t();
int char_index = PredictCHars(ch2); //预测
str_CHAR += kChars[char_index]; //根据索引得到字符
++itr;
}
return str_CH + str_CHAR; //合并字符
} 至此就小功告成了,如果有同学有更深层次的要求或者要改进,根据EasyPR的项目来做改进。有问题可以联系我的。