第一部分 Spark介绍
第二部分 Spark的使用基础
第三部分 Spark工具箱
第四部分 使用不同的数据类型
第五部分 高级分析和机器学习
第六部分 MLlib应用
第七部分 图分析
第八部分 深度学习
Spark开发中最令人兴奋的以部分就是深度学习。深度学习是迅速发展的用于解决机器学习问题的强大技术之一,特别是那些包含非结构化数据(如图片、音频、文本)的问题。本章会介绍Spark如何与深度学习协同工作,及一些你可以用Spark 和深度学习一起 来完成的不同处理。
本章不会关注那些对Spark必要的核心包,而是构建在Spark上的函数库中的大量创新。因为深度学习是一个新领域,许多最新的工具通过外部函数库执行。我们会从使用Spark上的深度学习的几种高级方法开始,讨论在什么使用它们,并讨论对它们来说可用的函数库。像往常 一样,我们会包含端到端的例子。
注意:如果你几乎没有使用机器学习或深度学习的经验,那很不幸,本章不会提供一个关于你需要知道的东西的完整总结。要想在这一章取得真正的成功,就像Spark的基础一样,你至少需要知道深度学习的基础。话虽如此,我们指出一个非常好的资源,有很多非常成功的研究者所编著的——Deep Learning Book。我们建议再开始本章之前,花一些时间去学习机器学习方法,并对深度学习有一个基本的理解。
什么是深度学习
为了定义深度歇息,我们必须首先定义神经网络。一个神经网络是一个由权重和激活函数构成的的点图。这些点被组织成叠在一起的layers。每层都部分地或完全地连接到网络中的前一层。每个点激活的函数,在满足条件的输入触发后被激活。同时,网络的层可以逐步的代表 更复杂的函数,其“学习”输入数据的 特征层次(如:用于图像识别的边,圆和纹理)。训练网络的目的是 联系特定的输入和特定的输出,通过调节各个连接相关的权重 及 网络中每个点的值。
深度学习或深度神经网络,只是将很多不同架构中的这样的层结合起来。神经网络本身存在了几十年,在各种机器学习问题的流行中 起伏不断。然而,最近,随着大数据集(用于目标识别的 ImageNet语料集),并行化基础设备(集群和GPU),及新的训练算法 已经能够训练更大的神经网络,胜过 以前以前的机器学习任务中的方法。深度神经网络现在已经成为计算机视觉、语言处理、继续读懂自然语言任务的标准。他们常能比以前的手动调节模型更好的 “学习”特征。他们还被积极地应用与其他领域的机器学习。Apache Spark作为大数据和并行化计算系统的强大 使它成为一个运用深度学习的自然框架。
在Spark中使用深度学习
大多数情况下,无论您的目标应用程序是什么,有三个在Spark中使用深度学习的主要方法:
1、Inference:最简单的使用深度学习的方法是 去一个预训练过的模型,使用Spark将其并行应用于大型数据集。比如,给定一个可以识别人类的图片分类模型,其通过一个标准数据集训练(如ImageNet)过。可以将其用在一个零售商店,来追踪店内的顾客流动。许多组织发布过 大型的,在常见数据集(如,用于目标检测的FasterRCNN和YOLO)上预训练过的模型,所以你可以从你最喜欢的深度学习框架中选取一个模型,并使用Spark函数并行地应用它。简单的在一个map函数中 调用一个框架(如TensorFlow或PyTorch)可以得到分布式推断,尽管一些我们讨论的函数库进行了进一步的优化。
2、Featurization and Transfer Learning:相对复杂一些的方式是用现存的模型(如一个featurizer),而不是获取它的最终输出。许多深度学习模型在为端到端任务训练网络时,在较低的层中学习有用的特征表示。例如,一个在ImageNet(一个有许多目标类别的有标签的流行数据集)上训练过的分类器也会学习存在于自然图像中的低级别特征。我们可以使用这些特征来为原始数据集中不包含的新问题 学习模型。例如,ImageNet数据集不包含任何 癌症肿瘤的图片,但很多研究文章都使用了在其上训练的模型来 作为featurizers(特征提取器),以生成其他类别图像的分类器。这种方法叫做 transfer learning,通常会 切断一个 预训练过的模型的最后几层,然后重新 用目标数据集来重新训练。迁移训练通常非常有效,如果你没有一个大规模的训练数据:从头开始训练一个成熟的网络需要包含成百上千张图片的数据集,如ImageNet,来避免过拟合,这在很多商业场景中是不满足的。相反地,transfer learning 可以 只用几百张图片就可以工作,因为它只更新较少的参数。
3、Model Traning:Spark还用来从头开始训练一个新的深度学习模型。有两种常用的方法。第一种,你可以使用Spark将单个模型的训练并行化到集群上,在各节点之间通信参数更新。另外,一些含数据允许使用者并行地 训练相似模型的多个实例,来尝试多种模型架构和超参数,加速模型搜索和调优过程。对这两种情况,Spark的深度学习函数库 都简化了 将数据从RDD和DataFrame 传递到深度学习算法的过程。最后,及时你不想并行地训练自己的模型,也可以使用这些库从集群中提取数据,并使用TensorFlow等框架的本地数据格式 将其导出到单机训练脚本。
在所有这三种情况下,深度学习代码 都作为 包含ETL步骤来解析输入数据,多数据源的I/O,潜在的批处理或流推断 的大型应用的一部分 来运行。对应用的这些其他部分,你可以简单地使用DataFrame,RDD,Mllib APIs。Spark的强大之一正是 将这些步骤组合为一个并行工作流的简单性。
深度学习库
在本节,我们会介绍一些可用于Spark上的深度学习的 最流行的函数库。我们会描述这些库的主要用例,如果可能的话 会链接到参考文献或一个小例子。这个列表名不是详尽的,因为这个领域正在迅速的严谨,所以我们鼓励你去查看每个库的网站和Spark文档的最近更新。Databricks 工程师博客 https://databricks.com/blog 也会定期发布关于深度学习的文章。
MLlib Neural Network Support
Spark的MLlib目前 原生地在ml.classification.MultilayerPerceptronClassifier中支持一个深度学习算法,多层感知器分类器。这个类 仅限于训练相对浅的神经网络,其中包含 有sigmod激活函数的全连接层,和一个有softmax激活函数的输出层。 当在一个现存的基于深度学习的featurizer上使用迁移学习时, 对训练分类器模型的最后几层非常有用。例如,它可以加在 深度学习pipeline的顶部,来快速地通过Keras和TensorFlow模型来执行迁移学习。然而,MultiLayerPerceptronClassifier 独自不足以基于原始输入数据训练一个深度学习模型。
TensorFrames
TensorFrames是一个 面向推理 和迁移学习的库,这使它可以很容易的在Spark DataFrames 和TensorFlow之间传递的数据。其支持Python和Scala接口,专注于提供一个简单且优化的接口,将数据从TensorFlow传递给Spark 并返回。尤其在使用TensorFrames来在Spark DataFrames上运用一个模型,其直接调用TensorFlow模型,由于更快的数据转换和摊销的启动成本,通常会比调用Python map函数更有效。TensorFrames对于推理、流设置和批处理设置以及传输学习都非常有用,你可以在原始数据上运用一个现有模型来进行特征化,然后使用MultilayerPerceptronClassifier来学习最后一层,或仅仅使用一个更简单的 逻辑回归 或随机森林分类器来学习。
https://github.com/databricks/tensorframes
BigDL
BigDL(读作big deal)是一个针对Apche Spark的分布式深度学习框架,主要由intel开发。其旨在对大模型支持分布式训练,以及使用推理快速应用这些模型。BigDL相比如其他库的一个主要的优点是 它对使用CPUs而不是GPUs进行了优化,使得它可以有效地运行在一个现存的基于CPU的集群(如 Apache Hadoop部署)。BigDL提供了高级别APIs来从头构建一个神经网络,并默认自动分配所有的操作。
https://github.com/intel-analytics/BigDL
TensorFlowOnSpark
TensorFlowOnSpark是一个被广泛使用的库,可以在Spark集群上并行地训练Google TensorFlow模型。TensorFlow 已经可以提供分布式训练的支持,但还没有提供一个集群管理器,或一个直接可用的分布式I/O层,用户必须手动地建立一个分布式的TensorFlow集群并输入数据。TensorFlowOnSpark在Spark job中启动 TensorFlow已存在的分布式模式,并自动地从Spark RDDs或DataFrame中输入数据到TensorFlow job中。 如果你已经知道如何使用TensorFlow的分布式模式,TensorFlowOnSpark可以使在Spark集群上启动job变得很简单,并可以将其他Spark库处理过的来自Spark所支持的数据源数据 输入给TensorFlow job。TensorFlowOnSpark最初由Yahoo开发,也在其他大型组织的产品中使用。
https://github.com/yahoo/TensorFlowOnSpark
CaffeOnSpark
Caffe是一个关注于图像处理的流行的深度学习框架。CaffeOnSpark是一个开源包,用来在Spark上使用Caffe,其中包括并行模型培训,测试,特征提取。就像TensorFlowOnSpark,其旨在与已有Spark集群上并行地运行Caffe,并能容易地将数据从Spark传入Caffe。CaffeOnSpark也由Yahho开发。
https://github.com/yahoo/CaffeOnSpark
DeepLearning4J
DeepLearning4J是一个开源的,用java和scala开发的分布式深度学习项目,支持单节点或分布式训练模式。一个比基于Python的深度学习框架 好的地方是 它是为JVM设计的,这对那些不不打算在他们的开发过程中加入Python的团队来说更方便的。其包含大量训练算法,并支持CPUs和GPUs。
https://deeplearning4j.org/spark
DeepLearningPipelines
Deep Learning Pipelines是一个来自Databricks的开源包,其将深度学习函数结合到Spark的ML Pipeline API中。该包调用现有的深度学习框架(TensorFlow 和 Keras),但关注于两个目标:(1)经这些合并到Spark标准中,比如ML Pipelines 和Spark SQL,来时他们更易于使用。(2)默认地将所有计算进行分布。
例如,Deep Learning Pipelines 提供了一个 DeepImageFeaturizer类,其可以在Spark ML Pipeline API中 作为一个 Transformer,允许你只有几行代码来构建一个 transfer learning pipeling(如,通过添加一个感知器或一个逻辑回归分类器)。同样地,该项目支持 使用MLlib的网格搜索和交叉检验的API 进行多模型参数的并行网格搜索。
最后,用户可以将一个ML模型导出为一个Spark SQL 的自定义函数,让使用SQL或流应用程序可以使用它。
https://github.com/databricks/spark-deep-learning
如下是一个对各种深度学习库 和他们所主要支持的使用情况 的总结:
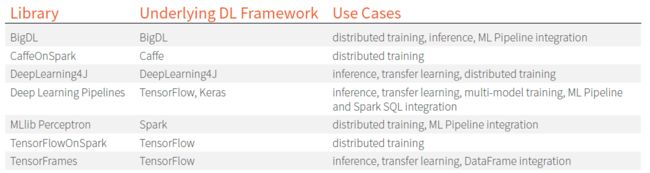
虽然不同的公司已经采用了几种方法来集成Spark和深度学习库,但目前 致力于将MLlib和DataFrames进行最紧密结合的是 Deep Learning Pipelines。这个项目致力于提高Spark对图像和tensor数据(在未来可能会集成进Spark核心代码)的支持,并在标准ML Pipeline API中提供所有深度学习功能,我们会在后面的章节用过简单的例子来介绍该项目的一些细节。
一个深度学习Pipeline的简单例子
正如我们所描述的,Deep Learning Pipelines 通过集成 流行的深度学习框架与Mlpipeline 和Spark SQL, 对可伸缩的深度学习 提供高级APIs。
Deep Learning Pipelines 基于Spark 的 ML Pipeline 进行训练,并使用Spark数据流和SQL来部署模型。其包含了用于深度学习共同之处的 高级APIs,使得可以通过几行代码有效地实施。
- 在Spark DataFrames中处理图像;
- 大规模应用图像和tensor数据的深度学习模型,不论是你自己的还是标准的流行模型。
- 使用 一般的预训练过的深度学习模型进行迁移学习。
- 将模型导出为一个Spark SQL函数,使所有用户可以运用深度学习。
- 用ML Pipeline进行分布式的 深度学习超参数调优。
- Deep Learning Pipelines 目前只提供一个python的API,这是设计用来与现有的Python深度学习包(如TensorFlow 和 Keras)进行紧密合作。
注意:读者需要意识到,该库,就像每个Spark 相关的深度学习库,目前都在活跃的开发当中。查看这些项目的目前的进展,来更好地理解它们当前的状况,以及新增功能。
安装
Deep Learning Pipeline是一个Spark 包,所以我们就像载入GraphFrames一样载入它。Deep Learning Pipelines 适用于Spark 2.x,在其中可以发现相应的包。你需要安装几个依赖,包括tensorframes,TensorFlow,keras和h5py。确保在driver和worker机器上都进行了安装。
我们将使用TensorFlow再培训教程中的flowers数据集。现在,如果你在一个集群上运行这些,你需要将这些 文件夹放在一个分布式文件系统中。我们在本书的GitHub仓库中包含了这些图片的样例。
图片 和 DataFrames
在Spark中处理图像时,一个历史性的挑战是将数据放入DataFrame是困难和乏味的。Deep learning Pipelines包含了实用函数,使得 分布式地载入和解码图片变得容易。
%python
from sparkdl import readImages
img_dir = ‘/mnt/defg/deep-learning-images/’
image_df = readImages(img_dir)
生成的DataFrame包含路径,然后是图像以及一些相关的元数据。
%python
image_df.show()
image_df.printSchema()
+--------------------+-----+
| filePath|image|
+--------------------+-----+
| /mnt/defg/de... | null|
+--------------------+-----+
root
|-- filePath: string (nullable = false)
|-- image: struct (nullable = true)
| |-- mode: string (nullable = false)
| |-- height: integer (nullable = false)
| |-- width: integer (nullable = false)
| |-- nChannels: integer (nullable = false)
| |-- data: binary (nullable = false)
迁移学习
现在我们已经有了一些数据,我们可以送一些简单的迁移学习开始。请记住,这意味着利用一个别人已经创建的模型,然后调整它来更好地适用与我们的目的。首先我们会载入每种花类型的数据,创建一个训练集和一个测试集。
%python
from sparkdl import readImages
from pyspark.sql.functions import lit
tulips_df = readImages(img_dir + "/tulips").withColumn("label", lit(1))
daisy_df = readImages(img_dir + "/daisy").withColumn("label", lit(0))
tulips_train, tulips_test = tulips_df.randomSplit([0.6, 0.4])
daisy_train, daisy_test = daisy_df.randomSplit([0.6, 0.4])
train_df = tulips_train.unionAll(daisy_train)
test_df = tulips_test.unionAll(daisy_test)
下一步会利用一个叫做DeepImageFeaturizer 的transformer。这允许我们利用一个叫做Inception的预训练过的模型,一个成功地用于图像模式识别的强大神经网络。我们使用的版本是经过预先训练的,可以很好地处理图像。这是Keras库附带的标准预训练模型的一部分。然而,这个特别的神经网络不是用来处理我们的涉及花的图像集的。因此,我们需要使用迁移学习来使它变成对我们有用的东西。
这里非常强大的一点是,我们可以使用 与贯穿本书用于处理机器学习的 相同的ML pipeling概念。DeepImageFeaturizer只是一个Spark ML transformer。此外,我们为扩展这个模型所做的所有事情 就是 田间一个逻辑回归模型,为了帮助训练我们最后的模型。在这里,我们也可以使用其他的分类器。
注意:下面的代码片段不太可能在小型机器上运行成功,因为在使用和应用这个模型需要大量的资源。
%python
from pyspark.ml.classification import LogisticRegression
from pyspark.ml import Pipeline
from sparkdl import DeepImageFeaturizer
featurizer = DeepImageFeaturizer(inputCol="image", outputCol="features", modelName="InceptionV3")
lr = LogisticRegression(maxIter=1, regParam=0.05, elasticNetParam=0.3, labelCol="label")
p = Pipeline(stages=[featurizer, lr])
p_model = p.fit(train_df)
一旦我们训练了模型,我们就可以使用我们在前面几章所看到的的相同的分类评估器。我们可以指定我们想要测试的度量,然后根据它进行测试。
%python
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
tested_df = p_model.transform(test_df)
evaluator = MulticlassClassificationEvaluator(metricName="accuracy")
print("Test set accuracy = " + str(evaluator.evaluate(tested_df.select("prediction", "label"))))
以我们的DataFrame为例,我们可以检查 在之前训练时出错的行和图片。
%python
from pyspark.sql.types import DoubleType
from pyspark.sql.functions import expr
# a simple UDF to convert the value to a double
def _p1(v):
return float(v.array[1])
p1 = udf(_p1, DoubleType())
df = tested_df.withColumn("p_1", p1(tested_df.probability))
wrong_df = df.orderBy(expr("abs(p_1 - label)"), ascending=False)
wrong_df.select("filePath", "p_1", "label").limit(10).show()
在大规模数据上应用深度学习模型
Spark DataFrames是一个在大规模数据集上应用深度学习模型的天然架构。Deep Learning Pipeline 提供一系列Transformers(Spark MLlib) 来 运行成规模的 TensorFlow Graphs 和 TensorFlow-backed Keras模型。此外,流行的图像模型可以直接使用,不需要任何TensorFlow和Keras代码。Transformers,在Tensorframes库的支持下,可以在Spark workers上有效地处理模型和数据的分发。
应用流行的图像模型
有很多关于图像的标准深度学习模型。如果手头的任务与模型所提供的类似(如:使用ImageNet类进行对象识别),或只是单纯的探索,你可以使用DeepImagePredictor这个Transformer,只需要指定模型名称。Deep Learning Pipeline支持各种标准模型,包括Keras,这些模型在其网站上有列出。
%python
from sparkdl import readImages, DeepImagePredictor
image_df = readImages(img_dir)
predictor = DeepImagePredictor(inputCol="image", outputCol="predicted_labels",
modelName="InceptionV3", decodePredictions=True, topK=10)
predictions_df = predictor.transform(image_df.where("image.mode is not null"))
注意到 使用这个基础模型,对所有样例花卉图片,predicted_labels列显示“daisy”是一个高可能性的类。然而,从概率值的差异可以看出,神经网络具有识别两种花卉类型的信息。因此,上述的迁移训练例子 能够基于基础模型 正确地学习 daisies 和 tulips之间的差别。
df = p_model.transform(image_df)
应用 Keras 模型
Spark深度学习也允许 以分布式的方式应用 TensorFlow-backed Kears模型。查看KerasImageFileTransformer上的用户指南来学习。其方法是通过 载入keras模型,然后在与前面段落相同的DataFrames上应用模型。
应用 TensorFlow 模型
Deep Learning Pipelines,通过与TensorFlow的深度结合,可以用来创建 定制transformers,来使用TensorFlow操作图像。比如,你可以创建一个改变图像大小和调整色谱的transformer。