Hadoop学习之路(一):Hadoop完全分布式搭建(附带实用集群管理脚本)
Hadoop完全分布式搭建
- 一、Hadoop搭建方式简介
- 1. 本地模式
- 2. 伪分布式
- 3. 完全分布式
- 二、Hadoop完全分布式搭建所用到的组件
- 三、Hadoop完全分布式搭建
- 1.安装JDK
- 2.编写host文件
- 3.配置ssh无秘登录
- 4.下载并安装Hadoop
- 5.配置Hadoop的配置文件
- 6.格式化并启动集群
- 四、编写两个非常有用的脚本管理集群
- 1.分发文件到各个节点的脚本
- 2.各个节点同时执行同一命令的脚本
- 五、测试集群
- 1.上传文件以及下载文件
- 2.在YARN上跑一个简单的任务
- 六、总结
一、Hadoop搭建方式简介
-
1. 本地模式
本地模式下的Hadoop的HDFS即为本地文件系统,在Linux下的Hadoop本地模式的文件系统就是根 /,且本地模式下的Hadoop无需任何的配置,把压缩包解压即为本地模式。 -
2. 伪分布式
- 伪分布式是指Hadoop的几个进程:NameNode,Secondary Namenode,DataNode,ResourceManager,NodeManager在同一台主机中,即Master和Slave在同一台主机。
-
3. 完全分布式
完全分布式是指Master和Slave在不同的主机。本次咋们搭建的就是完全分布式。
二、Hadoop完全分布式搭建所用到的组件
- 1.虚拟机软件VMware Workstation Pro
- 2.三台相同的虚拟机(博主因为电脑原因只可以开三台,数量自定义,大于2台即可),装上linux系统,本次演示用的是CentOs 7.0
- 3.JDK版本为1.8.
- 4.Hadoop版本为hadoop-2.6.0-cdh5.7.0
- 5.(可选)使用xshell连接虚拟机操作
三、Hadoop完全分布式搭建
-
1.安装JDK
(1). 在三台主机下安装JDK,请自行去Oracle官方网站下载即可,本次演示使用的JDK版本是:jdk-8u65-linux-x64。
(2). 在Linux终端下的home目录下创建文件夹 software 用于存放下载的安装包,创建 app 目录存放解压的软件,tmp 文件夹存放日志或者存储数据。
(3). 下载后的jdk安装包放在software目录下:

(4). 在software目录下执行命令:tar -zxvf jdk-8u65-linux-x64.tar.gz -C ~/app/,将JDK解压至app目录下。

(5). 配置环境变量
在三台主机下的终端使用命令vim ~/.bash_profile编写配置文件,保存并退出:
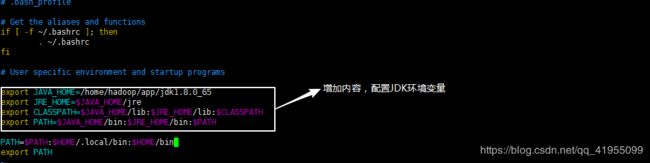
-
2.编写host文件
在本次演示中共用到三台虚拟机,其中hadoop000作为Master,hadoop001和 hadoop002作为Slave,所以要编辑host文件对其进行IP地址的映射:
在三台主机的终端下使用命令:sudo vim /etc/hosts,注意编辑该文件需要root权限,编辑内容如下:

-
3.配置ssh无秘登录
(1). 为什么需要无秘登录
在Hadoop执行作业或者文件的上传等操作中Master与Slave大量的通信,且Master需要登录到Slave中操纵Slave完成任务,这就需要Master可以无秘登录至所有的Slave,因此需要配置ssh无秘登录。
(2). 配置过程
a. 在Master处执行命令:cd ~/.ssh进入隐藏目录ssh,在该目录下执行命令:ssh-keygen -t rsa,回车三次,会得到两个文件:id_rsa(私钥),id_rsa.pub(公钥):

b. 将Master生成的公钥即id_rsa.pub文件发给Slave主机,执行以下命令:
ssh-copy-id hadoop@hadoop001和ssh-copy-id hadoop@hadoop002,这两个命令会将Master的公钥追加到服务端对应用户的 $HOME/.ssh/authorized_keys 文件中,查看hadoop001的 $HOME/.ssh/authorized_keys:

发现Master的公钥已经加进去,hadoop000可以无密码登录hadoop001和hadoop002主机。 -
4.下载并安装Hadoop
(1). 在三台主机的software目录下执行以下命令,下载Hadoop安装包:wget http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.7.0.tar.gz.
(2). 解压Hadoop安装包到app目录:tar -zxvf hadoop-2.6.0-cdh5.7.0.tar.gz -C ~/app/
(3). 配置环境变量
在三台主机下的终端使用命令vim ~/.bash_profile编写配置文件,保存并退出:

-
5.配置Hadoop的配置文件
执行命令cd app/hadoop-2.6.0-cdh5.7.0/etc/hadoop,进入到Hadoop的配置文件目录,配置如下文件:
(1). hadoop-env.sh

(2). hdfs-site.xml
(3). core-site.xml<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>dfs.replication</name> # 副本系数,因为我只有两台slave所以为2 <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/hadoop/app/tmp/dfs/name</value> # namenode临时文件所存放的目录 </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/hadoop/app/tmp/dfs/data</value> # datanode临时文件所存放的目录 </property> <property> <name>dfs.namenode.secondary.http-address</name> # secondary namenode的地址 <value>hadoop000:9001</value> </property> <property> <name>dfs.namenode.fs-limits.min-block-size</name> #文件最小块大小 <value>1024</value> </property> </configuration>
(4). mapred-site.xml<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>fs.default.name</name> <value>hdfs://hadoop000:8020</value> # 指定默认的访问地址以及端口号 </property> </configuration>
(5). yarn-site.xml<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>mapreduce.framework.name</name> #配置调度mapreduce的框架 <value>yarn</value> </property> </configuration>
(6). slaves<?xml version="1.0"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> #指定resourcemanager的主机名 <value>hadoop000</value> </property> </configuration>
该文件配置的是slave主机的IP或者主机名,一行一个:

注意: 以上6个文件在三台主机中都应该保持一致。 -
6.格式化并启动集群
(1). 在 Master(hadoop000) 上执行命令hadoop namenode -format格式化集群。
(2). Hadoop的几个启动脚本简介:
在/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/sbin下有以下启动脚本:
start-dfs.sh:启动HDFS,包括NameNode,Secondary Namenode,DataNode进程。
start-yarn.sh:启动YARN,包括ResourceManager,NodeManger进程。
start-all.sh:启动HDFS和YARN。
在Linux终端执行命令:start-all.sh,启动Hadoop。
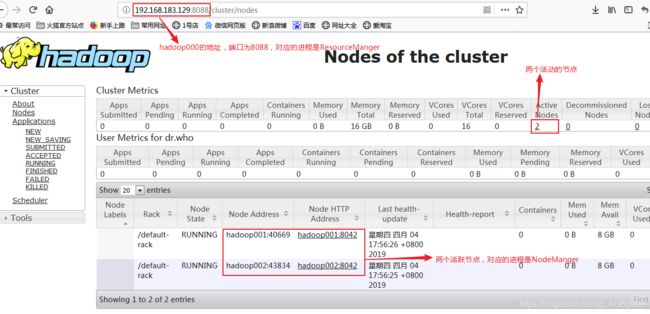
(3). 验证是否启动成功
在Master(hadoop000)主机执行命令:jps,查看Java进程:

在hadoop001上执行相同命令:

在hadoop002上执行相同命令:

或者查看WebUI,端口为50070和8088

四、编写两个非常有用的脚本管理集群
-
1.分发文件到各个节点的脚本
在配置过程中不难发现,有大量的工作是重复的,比如说环境变量的配置,Hadoop的配置等等,最后没台主机都是具有相同的配置文件,因此我们可以先在hadoop000配置好文件,然后分发给hadoop001和hadoop002,因此在home目录下创建目录shell,在shell目录下编写脚本xscp.sh:
执行命令#!/bin/bash prame=$1 #接收文件名 dirname=`dirname $1` basename=`basename $1` #得到文件的basename cd $dirname #进入该文件路径下 fullpath=`pwd -P .` #获得该文件的绝对路径 user=`whoami` #获得当前用户的身份 for(( i = 1; i < 3; i = $i + 1 ));do #遍历发送 echo ============ hadoop00$i ============= scp -rv $prame ${user}@hadoop00$i:$fullpath donesudo chmod a+x xscp.sh赋予脚本执行权。 -
2.各个节点同时执行同一命令的脚本
在测试集群是否启动成功的过程中我们分别对三台主机使用,命令jps查看其Java进程,过程很繁琐,因此编写一个shell脚本 xcall.sh 使其可以在hadoop000上完成对子节点的监控:
执行命令#!/bin/bash prame=$1 #接收命令参数 i=0 for((i = 0;i < 3;i++));do #每台主机执行该命令 echo ============= hadoop00$i $prame ============== ssh hadoop00$i "$prame" donesudo chmod a+x xcall.sh赋予脚本执行权。
测试脚本:在shell目录下执行./xcall.sh jps:

实现了在hadoop000监控其他的子节点。
五、测试集群
-
1.上传文件以及下载文件
将我们刚刚写的脚本上传至HDFS的根目录:hdfs dfs -put xcall.sh /
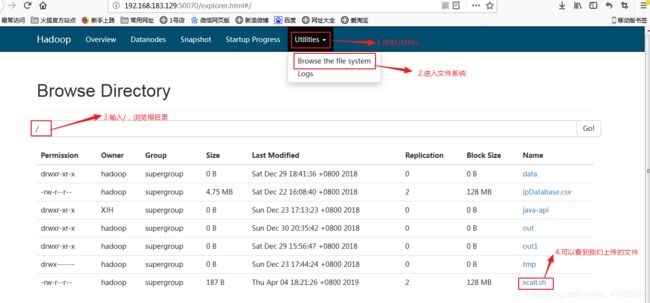
从HDFS下载文件:hdfs dfs -get /xcall.sh -
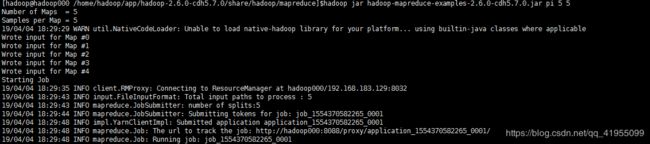
2.在YARN上跑一个简单的任务
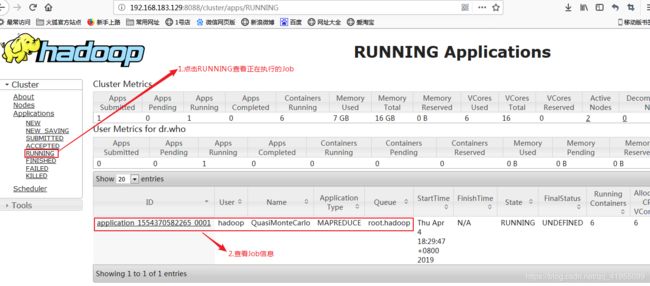
进入目录:$HADOOP_HOME/share/hadoop/mapreduce下执行如下命令:hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar pi 5 5使用mapreduce在YARN上就算pi的值:
六、总结
在本章中,我们首先了解了Hadoop的三种部署模式,然后就其完全分布式进行了演示,还为了解决实际的问题而写了两个shell脚本管理集群,最后简单操作一下HDFS和在YARN上跑一个小Job。至此,完成了Hadoop完全分布式的搭建,下一节将演示Hadoop节点的委任与解除,详情移步 Hadoop学习之路(二):Hadoop节点的委任与解除。谢谢大家的阅读,我是人间,乐于结识共同学习的小伙伴~