从图像集合中学习特定种类的网格重建cmr
项目地址:https://akanazawa.github.io/cmr/
代码地址:https://github.com/akanazawa/cmr
主要思想
这篇论文提出了从一张图片恢复这个物体的3D形状、摄像机姿态和纹理的学习框架。形状可以表示为一个可变的物体种类的3D网格模型,这个形状通过一个学习的平均形状和每一个实例的预测形变被参数化。通过融合纹理推断作为一幅图像在一个经典的外表空间的预测,他们提出的这种表示方法能够超越现在的3D表示方法,例如体素、深度、点云等,达到更好的效果,无论是在质量还是在数量上。并且他们的训练集只用了带有标注的图像集合,而没有用到3D模型,这在以前是很少有的。(我在服务器上面跑的,如果想要服务器的同学可以私聊我,免费赠送时长)
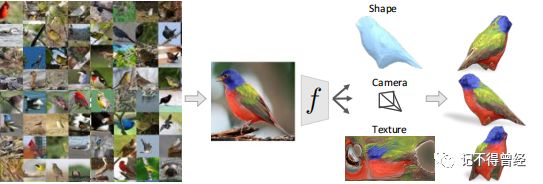
简介
给我们一张鸟的图片,我们能够推断出它的形状,因为一个鸟的虚拟模型已经在我们的脑海当中存在。这篇文章充分利用了这个点,他们通过一个平均形状+形变,来获取这个物体的真实形状。
输入一张鸟的图像,这个网络就能够推断出这个物体的形状、摄像机姿态和纹理,相比于其他方法,不需要任何的3D数据。这篇论文主要有三个方面的贡献:形状表示和推断的方法、从图像集中学习、能够推断纹理。
框架综述

图像I通过卷积编码器传递到潜在的表示形式,由估计摄像机姿态、变形和纹理参数的模块共享。变形是学习到的平均形状的一个偏移量,当它被添加到标准型坐标系中时,会产生实例特定的形状。这个框架还学习了网格顶点与语义关键点之间的对应关系。将纹理参数化为UV图像,通过纹理流对其进行预测。目标是最小化渲染蒙版、关键点和纹理渲染之间的距离,并使用相应的地面真相注释,不需要地面真相三维形状或多视图线索的训练。
推断3D形状
形状参数化:3D网格M≡(V, F),F对应于一个球面网格,V = V¯+∆V,即平均形状+形变。
相机投影:使用π(P)来表示一组3D点云P弱透视投影到图像坐标,定义为π≡(s, t, q)。
联想语义对应:根据预测的形状的顶点来预测关键点,这里共有13个。
从图像集学习
训练集:对于每一个物体,用有标注的训练集{(Ii,Si,xi,π˜i)}i=1到N表示,Ii表示某一张图片,Si表示实例分割后的图像,xi∈R2×K表示关键点位置的集合,还有弱透视投影参数π˜i。
对于每一个实例,定义如下损失函数:
![]()
![]()
![]()
为了提升效果,定义了平滑损失函数和形变的正则化:
![]()
![]()
总的损失函数:
![]()
对称约束:将预测的形状和变形约束为镜像对称。对于平均形状V¯和变形V,每对中只学习/预测一个顶点的参数。
初始化和实现细节:对平均顶点位置V¯进行更好的初始化可以加快学习速度。通过计算从运动中获得的平均关键点位置的凸包,并初始化平均顶点位置使其位于凸包上
纹理预测
文中提到的平均形状与一个球体同构,其纹理可以表示为一个图像Iuv,其值通过一个固定的UV映射映射到表面(类似于将一个球体展开成一个平面地图)。
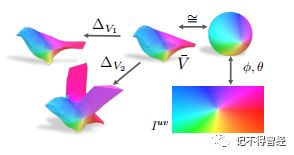
上面的说明了纹理图像Iuv如何在预测网格上诱导出相应的纹理。球面上的点可以通过球坐标映射到图像Iuv上。由于平均形状有相同的网格几何(顶点连接)作为一个球体,可以转移到平均形状的映射。不同的预测形状,反过来,只是平均形状的变形,可以使用相同的映射。

该框架预测了一个纹理流F用于双线性采样输入图像I来生成纹理图像Iuv,可以使用这个预测的UV图像Iuv,然后通过上图所示的UV映射过程对实例网格进行纹理处理。
现在来定义纹理损失,这有助于渲染纹理图像匹配前景图像:
![]()
是由Iuv定义的纹理的3D网格的渲染。
作者发现它有助于添加进一步的损失,有助于纹理流只从图像的前景区域选择像素。这可以简单地表示为:根据F对前景掩模DS(其中对于前景中的所有点x, DS(x) = 0)的距离变换域进行采样,并对得到的图像求和:
![]()
实验结果

在测试集上的结果,对于每一张左边输入的图像,得到预测的3D形状和不同角度看到的图像。
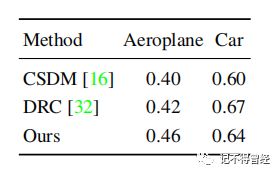
不同方法在PASCAL_3D+上的对比效果

在Pascal 3D+ 上的实验结果
我已知晓数据预处理以及训练过程,并实现车的三维重建,欢迎各位同行交流心得,关注公众号:记不到曾经,获取联系方式