贪心算法的一个应用例
我们来看下面一道ACM竞赛题

看到这个题目,我的第一反应是这个问题具有可收缩性(可以递归)
。它可以展成类似拉普拉斯展开的形式,过程如下:
设问题的解为An;设去掉一行一列后他的任意n-1阶子矩阵满足题目条件的和为An-1(i),i取1到n,那么只需算出Ai加上去掉的这个元素,然后进行比较,保留最大的即可,对于An-1(i);我们还可以做相同的拆分,算他的n-2阶主子式。那么这样的过程很容易写出递归函数。
但要作为算法,就不得不考虑他的效率,以上过程的时间复杂度可以达到n的阶乘之巨,几乎等同于指数量级,这显然不符合ACM的要求。
其实想来这个问题还是蛮有意思的,他有他的实际意义:假如国家今年有42个科研项目,要分给42个双一流大学,为了公平起见,每个学校分一个,但每个学校对于每项任务的完成能力肯定是有所差异的,那么为了提高科研产出效率,就可以使用到这样一个算法。
笔者最近刚刚研究了贪婪算法,在这道题目中,灵机一动就产生了很多新的想法,那么就班门弄斧,在此拿来与大家分享以下自己的拙见。
既然题目要求每行每列都只能选一个元素,而且要保证和最大,那么我们何不求出每行的最大元素呢?
但因为每一列也不能重复,所以我们需要记录下来每一行最大元素所在的列数,以此为基础做进一步筛选。
由此我的解决思路是调用库函数qsort,对每一行进行排序,这样虽然比只找出最大值多做了很多无用功,但对于我们下一步的贪婪策略而言,却提供了很大的方便,因为最大的不一定都能取到,那最大的去不了的话,我们不妨就取第二大的,这样才能满足我们和最大的贪婪目标嘛
在代码中我是将int型数组扩充成了结构体数组,保留数值和原始列数。
下面是产生随机数组并排序的过程:
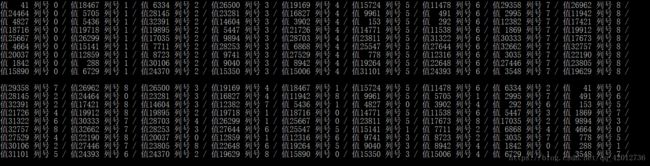
排序的过程是n次n个元素的快拍,时间复杂度大约为n*nlogn,排完序以后呢,就来讲讲我们的贪婪策略
想想最理想的情况,如果没有每列取一个的限制,我们把每行的最大值全部取出当然最好不过了,但这里又限制了每一列不能重复取,而我们排序后又不能保证每一行的最大值刚好分布于不同列,在刚才排序的时候我们已经记录了行最大元素的列号,这时候 我们想了,这些列号出现的次数会呈现出什么样的情况呢?每个列号出现的次数一定为0到n之间,假如某个列号只出现一次的话,因为我们的贪婪策略定的是尽量取出每行的最大值,我们可不可以毫不犹豫的把他取出来?这显然满足贪婪算法整体最优解的策略,所以我们把它取出来;
假如某个列号出现两次呢?这时候为了保证列不重复,为了满足贪婪策略,我们仍可以选择其中一个取出。但我们不得不忍痛割爱,舍弃其中一个,既然我们放弃了行最大值,那好吧,我们就取行第二大值把,这样还不算太亏,有时呢,第二大值所在的列已经取过了,这时候我们应转向第三大值,依次类推,直到找到一个可取的元素为止,这里就看到了我们先前进行排序的好处。所
以我们在这里引进一个退化度的概念,用它表示舍弃行最大值后,向后查找到的那个可取元素与最大值的差值。在此基础之上,对于行最大值的列号重复的那两行,我们分别算出这两行的“退化度”,再将其做比较,让“退化度低”的元素“退化”并取出“退化“后的值,即舍去行最大值,让“退化度”高的元素保留并取出。这样算来离理想最优解“所有行最大值的和”应该是最近的了。
在假如我们某个列号出现3次及以上呢(记为k次)?那我们就还按照原来的套路,对这k行算出退化度并进行比较,让“退化度”最小的行退化并取出,这样就还剩下k-1行了,对于这k-1行重新计算退化度,再重复上述过程即可,直至剩下一个,没人跟他竞争了,就保留取出了。
分析此算法的不足之处;首先我们想到,既然我们可以按行排序按行取数,那我们当然也可以按列取喽,而且两次得到的结果很可能是不同的,我们甚至未必能求出和正确答案相同的解。其次,我们排序时没有考虑出现相同数字的情况。
对于行列顺序引起的不同解,大不了我们算两次就好了。
而对于值相等的情况,粗糙的处理是算出退化度为0,优先退化,但是在实际运行过程当中,受制于之前取出的元素,有时候他是无法完成退化的,再者说,还有可能出现三个数连等的更特殊的情况,显然会引起贪婪策略失败。保证此算法精确度最核心的部分在于取出元素的次序,因为每取出一个元素都会导致后续再取其他元素计算的贪婪值发生改变。因此每一次我们都要算出所有未取行的贪婪值,并拿出最小的,然后检测是否有某列号满足了“唯一”的情况,可以优先取出。才可保证拿到我们想要的结果。换言之,不允许用for循环对列好经行逐一贪婪,而是要全局化地来考虑问题。这对我们运用语法也是一个不小的考验。
笔者可以给出一段并不完整的代码,因为笔者学习编程也只有半年,写的并不好。请各位大神还是重点理解算法思路,自己编写程序比较好。
我把它拆分成三个文件,写入visual studio。
文件1:stdafx.h
// stdafx.h : 标准系统包含文件的包含文件,
// 或是经常使用但不常更改的
// 特定于项目的包含文件
//
#pragma once
#include "targetver.h"
#include文件2: stdafx.cpp
// stdafx.cpp : 只包括标准包含文件的源文件
// 矩阵最大和.pch 将作为预编译标头
// stdafx.obj 将包含预编译类型信息
#include "stdafx.h"
#define MAX(a,b) (a)>(b)?(a):(b);
#define MIN(a,b) (a)<(b)?(a):(b);
// TODO: 在 STDAFX.H 中引用任何所需的附加头文件,
//而不是在此文件中引用
int Anl_thl;
in* Set_Squire(const int n)
{
in* a = (in*)calloc(n*n, sizeof(in));
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
*(a + i*n+j) = rand();
}
}
return a;
}
int Compin(const void*a, const void*b)
{
struct reflect* aa = (struct reflect*)a;
struct reflect* bb = (struct reflect*)b;
in rn = (*aa).val -(*bb).val;
if (rn > 0)
return -1;
else if (rn < 0)
return 1;
else
return 0;
}
void Prt_all(const void*free, const int n)
{
struct reflect* a = (struct reflect*)free;
for (int i = 0; i < n; i++)//print
{
for (int j = 0; j < n; j++)
{
printf("值%5d ", (a + i * n + j)->val);
printf("列号%2d / ", (a + i * n + j)->position);
}
printf("\n");
}
printf("\n");
}
int Tuihuadu(int*record, struct reflect*a, int l,int n)
{
bool find = 0;
int boluo,tem;
for (int i = 1; i < n; i++)
{
if (!(*(record + (a+l*n+i)->position)))
{
find = 1;
tem = (a + l * n + i)->val;
printf("tem=%d", tem);
boluo = (a + l * n)->val - tem;
Anl_thl=i; //排序后所处列号
break;
}
}
if (find)
return boluo;
else
{
Anl_thl = 0;
return 0;
}
}
文件3:任意名.cpp
这是主程序
// 贪婪算法
//
#include "stdafx.h"
extern int Anl_thl;
int main()
{
re:
int n;
scanf_s("%d",&n);//确定数据规模
in*Jz= Set_Squire(n); //建立矩阵
int* cot = (int*)calloc(n, sizeof(int));//列消除次数记录
int*record=(int*)calloc(n, sizeof(int));//纪录列消除值和真值
int*konglong = (int*)calloc(n, sizeof(int));//用于记录退化度
int out = n;
int*t_line= (int*)calloc(n, sizeof(int));//纪录列消除列号
int*kill = (int*)calloc(n, sizeof(int));//纪录列消除列号
struct reflect*p = (struct reflect*)calloc(n*n, sizeof(struct reflect));//建立同构映射
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
(p + n * i + j)->val = *(Jz + n * i + j);
(p + n * i + j)->position = j;
}
}
Prt_all(p, n);
for(int l=0;lsizeof(struct reflect), Compin);//让每一行有序
Prt_all(p, n);//打印看一看对不对
for (int l = 0; l < n; l++) //第l行 第i列
{
*(cot + l) = 0;//归零
}
for (int l = 0; l < n; l++)
{
*(cot + (*(p + l * n)).position) += 1;//计数 第i列有*(cot+i)个行最大值
}
for (int l = 0; l < n; l++)
{
if (*(cot + l) == 1)//如果唯一,就选它
{
for (int j = 0; j < n; j++)//回找
{
int t = (p + j * n)->position; //p+j*n是第j行首元素
if (l == t)
{
*(record + l) = (p + j * n)->val;//找到了第j行独占,按行号j取出
printf("找到贪婪值=%d ", *(record + l));
out--;
break;
}
}
}
*(cot + l)-=1;
}
while (out>0)
{
for (int j = 0; j < n; j++)
{
*(konglong + j) = 0;
*(t_line + j) = 0;
}
for (int l = 0; l < n; l++)
{
if (*(cot + l)>0)
{
for (int j = 0; j < n; j++)//按行找
{
int t = (p + j * n)->position; //p+j*n是第j行首元素
if (l == t)
{
printf("j=%d ", j);
*(konglong + j) = Tuihuadu(record, p, j, n);
*(t_line + j) = Anl_thl;
printf("退化度=%d ", *(konglong + j));
printf("列号=%d ", *(t_line + j));
}
}
}
}
int jk = 0;
bool flag = 0;
int tuihuazhi = 0;
for (int j = 0; j < n; j++) //遍历找到最小退化值,将行号存在jk里
{
if (*(konglong + j) > 0)
{
if (flag)
{
if (*(konglong + j) < tuihuazhi)
{
jk = j;
tuihuazhi = *(konglong + j);
}
}
else
{
flag = 1;
jk = j;
tuihuazhi = *(konglong + j);
}
}
}
printf("jk=%d ", jk);
//让jk行退化一次
//这里有问题
int li = (p + jk * n )->position;
*(cot + li) -= 1;
*(record + (p + jk * n) ->position) = (p + jk * n + *(t_line + jk) )->val;
printf("找到退化值=%d ", *(record + li));
printf("li=%d ", li);
out--; printf("out=%d ", out);
}
for (int i = 0; i < n; i++)
{
printf("%d ", *(record + i));
}
goto re;
return 0;
}