python数据分析笔记1:准备工作、ipython、jupyter notebook
python数据分析
GitHub仓库(章节数据文件和相关材料):https://github.com/wesm/pydata-book
陈刊错误、示例和附加信息:http://bit.ly/python_data_analysis_2e
利用python操作、处理、清洗和操作数据,专注于python语言编程、类库以及工具
结构化数据:
表格型的数据、多维数组(矩阵)、由键位列关联的多张表数据、均匀或非均匀的时间序列
重要的python库
NumPy
(http://numpy.org) numerical python 数值计算
多种数据结构、算法以及接口
多维数组对象、数组计算或数组操作函数、读写基于数组的数据集工具、线性代数操作、傅里叶变换、随机数生成、C语言API、python拓展、C语言/c++访问
pandas
(http://pandas.pydata.org)
高级数据结构和函数 DataFrame 实现表格化、面向列、使用行列标签的数据结构、一维标签数组对象(Series) 索引函数(重组、切块、切片、聚合、子集选择)
深度时间序列、时间索引数据
matplotlib
(http://matplotlib.org).
制图、二维数据可视化库
ipython/jupyter
(http://ipython.org) 执行-探索工作流
(http://jupyter.org) 适应更多语言的交互式计算工具
ipython实际是一个加强版的python解释器;Jupyter notebook是一个基于web的代码笔记本
jupyter可以使用多种语言,不仅仅是python。
SciPy
(http://scipy.org)
scipy.integrate 数值积分例程、微分方程求解器
scipy.linalg 线性代数例程、矩阵分解
scipy.optimize 函数优化器(最小化器)、求根算法
scipy.signal 信号处理工具
scipy.sparse 稀疏矩阵、稀疏线性系统求解器
scipy.special SPECFUN包容器(SPECFUN是Fortran语言下的通用数据函数包)
scipy.stats 标准的连续和离散概率分布(密度函数、采样器、连续分布函数)、各类统计测试、描述性统计。
scikit-learn
(http://scikit-learn.org)
机器学习工具包,与pandas、statsmodels、ipython使python成为了高效的数据科学编程语言。专注于预测。
分类:SVM、最近邻、随机森林、逻辑回归
回归:Lasso 、岭回归
聚类:k-means、谱聚类
降维:PCA、特征选择、矩阵分解
模型选择:网格搜索、交叉验证、指标矩阵
预处理:特征提取、正态化
statsmodels
(http://statsmodels.org)
统计分析包、 源于r语言实现的各类统计分析模型、专注于统计推理、提供不确定性评价和p值参数。
包含经典的统计学、经济学算法
回归模型:线性回归、通用线性模型、鲁棒线性模型、线性混合效应模型
方差分析(ANOVA)
时间序列分析:AR、ARMA、ARIMA、VAR
非参数方法:核密度估计、核回归
统计模型结果可视化
安装开发环境:
Windows7+Anaconda(python3.6版本)
安装与更新第三方库:
方法一:
conda install package_name
conda update package_name
方法二:
pip install package_name
不要使用pip更新conda安装的包;使用anaconda最好使用conda更新包。
集成开发环境和文本编辑器
1 pycharm
2 Spyder(anaconda)
主要内容
应用pandas、NumPy和matplotlib进行数据分析。
基本流程:
读写各种格式文件以及数据存储
对分析数据进行清洗、处理、联合、正态化、重组、切片、切块和转换
利用数学或统计操作使数据集的分组产生新数据集
数据接入统计模型、机器学习算法和其他计算机工具
创建动态/静态的图形可视化或文字描述
http://github.com/wesm/pydata-book
https://github.com/wesm/pydata-book
第三方库导入方式:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import statsmodels as sm
Python解释器
可以通过命令行输入python,转换成python的交互式环境。
可以通过输入命令:python name.py 执行文件name.py(文件必须在命令行当前路径)。
可以输入exit()退出并回到之前命令提示符。
IPython
可以通过命令行输入ipython,转换成ipython的交互式环境。
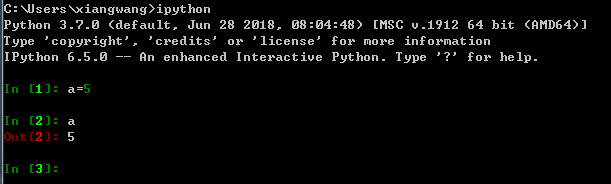
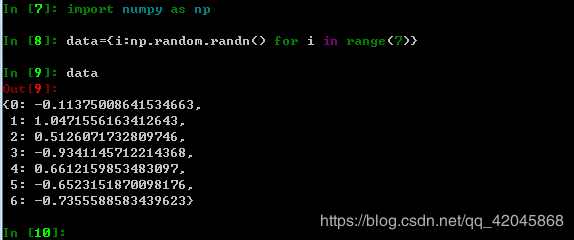

data为创建字典。
ipython中的对象被格式化,比print()打印出来的可读性更好更美观。
Jupyter notebook
可以通过命令行输入jupyter notebook, 默认浏览器自动打开。
也可以通过网址:http://localhost:8888/tree。
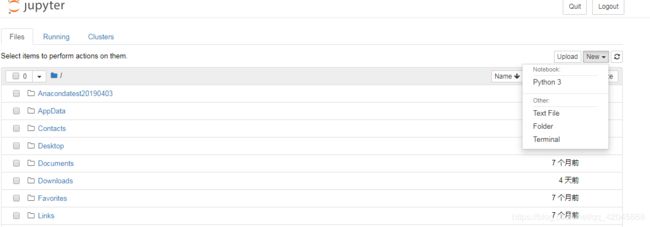
Jupyter web页面上的这些文件来自于默认路径(命令行处的路径)。将其他下载的Jupyter notebook笔记放在默认路径文件夹中,即可从web页面端导入并打开编辑。
新建笔记本:python3或conda[默认]

执行代码;shift+enter。
保存:save and checkpoint。后缀名.ipynb文件。
https://github.com/wesm/pydata-book
Tab 补全功能:通过tab键。
对象内省:在对象前后使用?(英文状态下),显示相关信息。使用??可以显示函数源代码。使用* *?显示所有相关的表达式的命名。
%run 命令 使用其运行程序
%run ipython_script_test.py (注意文件路径)
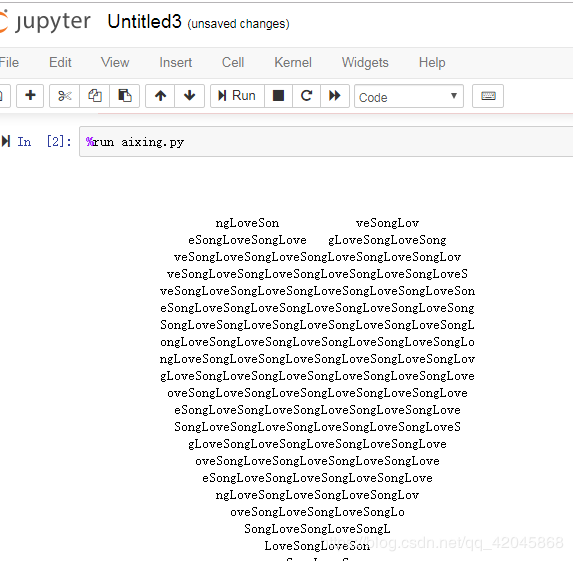
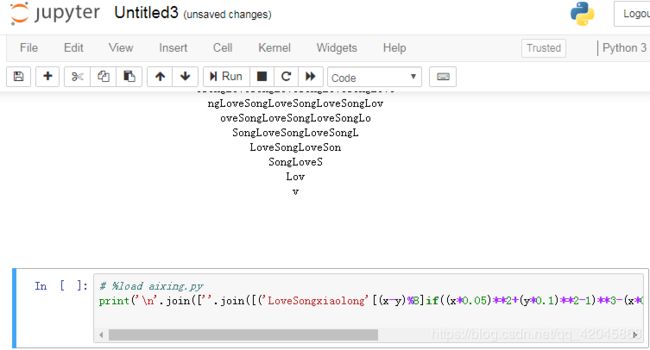
aixing.py文件在Jupyter web 的默认路径(命令行处的路径C:\Users\xiangwang)。
Jupyter notebook 中,利用%load魔术函数将脚本导入一个代码单元。
%load ipython_script_test.py (注意文件路径)
中断运行代码:ctrl+C
使用%paste和%cpaste魔术函数,可以直接执行剪贴板(经过复制)上的程序。
魔术命令:前缀符号%(省略%通过%automagic启用/禁用);魔术命令输出可以赋值给一个变量。
%quickref 显示ipython快速参考卡。
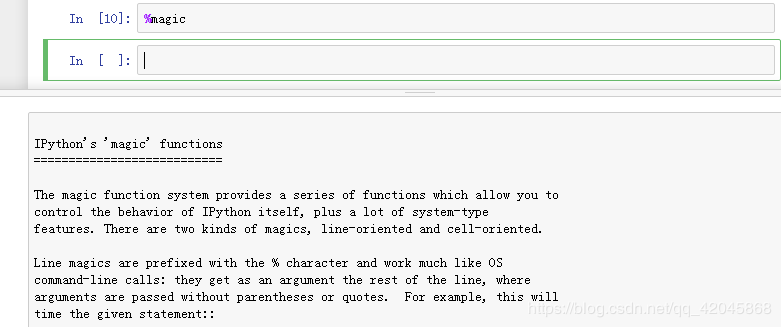
%magic 查看所有魔术命令详细文档。
matplotlib集成
在IPython中,使用%matplotlib。
在Jupyter中,使用%matplotlib inline。