推荐系统之矩阵分解(MF)没废话,有代码
前言
本文章,适合零基础学习MF(个人认为)数据集很小,只是简单但详细的讲解了矩阵分解,并给出了一个简单的代码
推荐系统中最为主流与经典的技术之一是协同过滤技术(Collaborative Filtering),它是基于这样的假设:用户如果在过去对某些项目产生过兴趣,那么将来他很可能依然对其保持热忱。其中协同过滤技术又可根据是否采用了机器学习思想建模的不同划分为基于内存的协同过滤(Memory-based CF)与基于模型的协同过滤技术(Model-based CF)。其中基于模型的协同过滤技术中尤为矩阵分解(Matrix Factorization)技术最为普遍和流行,因为它的可扩展性极好并且易于实现,接下来我们将讨论矩阵分解,即其代码实现
矩阵分解
我们都熟知在一些软件中常常有评分系统,但并不是所有的用户user人都会对项目item进行评分,因此评分系统所收集到的用户评分信息必然是不完整的矩阵。那如何跟据这个不完整矩阵中已有的评分来预测未知评分呢。使用矩阵分解的思想很好地解决了这一问题。
假如我们现在有一个用户-项目的评分矩阵R(n,m)是n行m列的矩阵,n表示user个数,m行表示item的个数
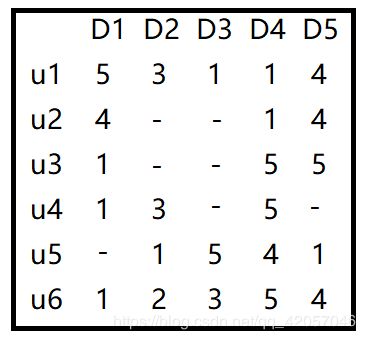
我们可以看出R矩阵是一个稀疏矩阵,在实际场景中,对于庞大的评分系统来说,每一歌用户所对用的项目是极小的。而R在实际场景中是一个极大地矩阵。
我们如何根据目前的矩阵R(5,4)对未打分的商品进行评分的预测呢(如何得到分钟为-或0的用户的分值?)
矩阵分解的思想很好的解决了这个问题,矩阵分解可以看做有监督的机器学习问题(回归问题)
矩阵R可以近似的表示为P和Q矩阵的乘积。
R可以分解为如下两个矩阵P(即nP)Q(即nQ),

预测矩阵
将矩阵P,Q进行矩阵的乘运算得到一个新的矩阵R1,R1就是基于R的预测矩阵
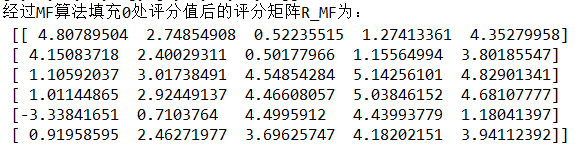
我们可以看出,矩阵R1和矩阵R是非常相似的
现在的问题是,如何求出矩阵Q和P呢
一个很简单的办法是通过迭代的方式逐步求得与R1=QP.T之间的距离变小。设置loss函数,然后使用梯度下降法。
矩阵分解算法推导
1.首先令![]()
![]()
2. 2. 损失函数:使用原始的评分矩阵![]() 与重新构建的评分矩阵
与重新构建的评分矩阵![]() 之间的误差的平方作为损失函数,即:
之间的误差的平方作为损失函数,即:
如果R(i,j)已知,则R(i,j)的误差平方和为:![]()
最终,需要求解所有的非“-”项的损失之和的最小值: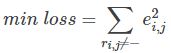
3. 使用梯度下降法获得修正的p和q分量:
- 求解损失函数的负梯度:
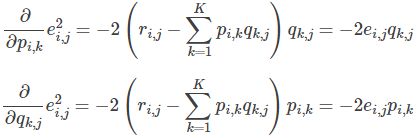
- 根据负梯度的方向更新变量:
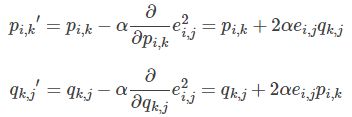
4. 不停迭代直到算法最终收敛(直到sum(e^2) <=阈值)
加入正则化项
【加入正则项的损失函数求解】
1. 首先令![]()
2. 通常在求解的过程中,为了能够有较好的泛化能力,会在损失函数中加入正则项,以对参数进行约束,加入![]() 正则的损失函数为:
正则的损失函数为:
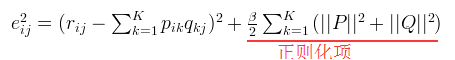
也即:
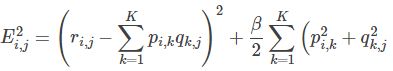
3. 使用梯度下降法获得修正的p和q分量:
- 求解损失函数的负梯度:
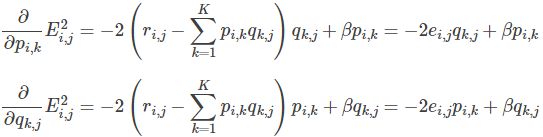
- 根据负梯度的方向更新变量:
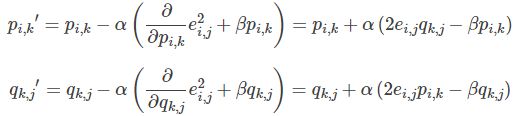
4. 不停迭代直到算法最终收敛(直到sum(e^2) <=阈值)
【预测】利用上述的过程,我们可以得到矩阵![]() 和
和![]() ,这样便可以为用户 i 对商品 j 进行打分:
,这样便可以为用户 i 对商品 j 进行打分:
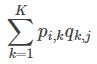
 点一下关注吧,下面是代码奥
点一下关注吧,下面是代码奥
代码实现(这里只给出加入正则化的代码)
import numpy as np
import matplotlib.pyplot as plt
def matrix(R, P, Q, K, alpha, beta):
result=[]
steps = 1
while 1 :
#使用梯度下降的一步步的更新P,Q矩阵直至得到最终收敛值
steps = steps + 1
eR = np.dot(P,Q)
e=0
for i in range(len(R)):
for j in range(len(R[i])):
if R[i][j]>0:
# .dot(P,Q) 表示矩阵内积,即Pik和Qkj k由1到k的和eij为真实值和预测值的之间的误差,
eij=R[i][j]-np.dot(P[i,:],Q[:,j])
#求误差函数值,我们在下面更新p和q矩阵的时候我们使用的是化简得到的最简式,较为简便,
#但下面我们仍久求误差函数值这里e求的是每次迭代的误差函数值,用于绘制误差函数变化图
e=e+pow(R[i][j] - numpy.dot(P[i,:],Q[:,j]),2)
for k in range(K):
#在上面的误差函数中加入正则化项防止过拟合
e=e+(beta/2)*(pow(P[i][k],2)+pow(Q[k][j],2))
for k in range(K):
#在更新p,q时我们使用化简得到了最简公式
P[i][k]=P[i][k]+alpha*(2*eij*Q[k][j]-beta*P[i][k])
Q[k][j]=Q[k][j]+alpha*(2*eij*P[i][k]-beta*Q[k][j])
print('迭代轮次:', steps, ' e:', e)
result.append(e)#将每一轮更新的损失函数值添加到数组result末尾
#当损失函数小于一定值时,迭代结束
if eij<0.00001:
break
return P,Q,result
R=[
[5,3,1,1,4],
[4,0,0,1,4],
[1,0,0,5,5],
[1,3,0,5,0],
[0,1,5,4,1],
[1,2,3,5,4]
]
R=numpy.array(R)
alpha = 0.0001 #学习率
beta = 0.002 #
N = len(R)
M = len(R[0])
K = 2
p = numpy.random.rand(N, K) #随机生成一个 N行 K列的矩阵
q = numpy.random.rand(K, M) #随机生成一个 M行 K列的矩阵
P, Q, result=matrix(R, p, q, K, alpha, beta)
print("矩阵Q为:\n",Q)
print("矩阵P为:\n",P)
print("矩阵R为:\n",R)
MF = numpy.dot(P,Q)
print("预测矩阵:\n",MF)
#下面代码可以绘制损失函数的收敛曲线图
n=len(result)
x=range(n)
plt.plot(x, result,color='b',linewidth=3)
plt.xlabel("generation")
plt.ylabel("loss")
plt.show()相关链接(有兴趣可以了解)
https://www.sohu.com/a/190681269_470008