RefineDet笔记-SSD进阶
1. 引言
本篇博客是基于我的SSD工程,想进一步加深对目标检测的理解。在该工程基础上完善新的RefineDet方法。第一帖,由于长期evernote,以后会逐步转为CSDN。
论文参考:Single-Shot Refinement Neural Network for Object Detection
论文链接:https://arxiv.org/abs/1711.06897
代码链接:https://github.com/sfzhang15/RefineDet
2. 论文思想
- 采用 Two Stage类型的object detection算法,对bound box的由粗到细的回归思想(由粗到细回归其实就是定义一个类型不可知检测器,主要是采用RPN网络得到粗粒度的box信息,只包含前景和背景,然后再通过常规的分类和回归,从而得到更加精确的框信息)。
- 参考 FPN网络的特征融合(deconv)操作用于检测网络,可以有效提高对小目标的检测效果,检测网络的框架还是SSD思想。
3. 网络结构
主要包括三部分结构:
Anchor Refinement Modual(ARM):类似RPN部分,用来提取anchor,过滤掉部分负样本候选框(1:3比例),减小分类器的搜索范围只区分前景和背景,并回归出前景的anchor用于检测模块。
Transfer Connection Block(TCB):将特征进行细化,并与深层特征进行 Eltw sum操作(对应元素求和)。作为当前layer的特征输入到检测模块。
Object Detection Modual(ODM):典型的SSD结构,多层特征进行concat后,softmax分类,smooth L1 回归。

需要注意TCB模块,结构如下:
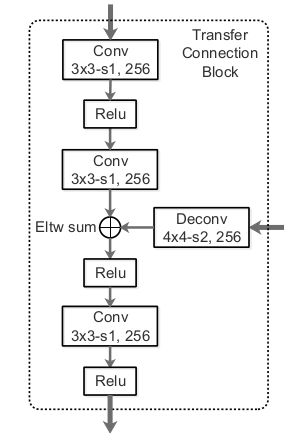
该模块上层是ARM的输入,经过两次33 conv后,与深层的deconv的特征进行Eltw sum。然后在经过两次 33 conv输出作为OBM输入。没有特别大的创新(后期参考DetNet的block块,用dilated conv代替验证下效果)
作者的backbone采用VGG16(the conv4_3, conv5_3, conv fc7, and conv6_2 feature layers)和Resnet101(res3b3, res4b22, res5c, and res6)作为ARM的四个蓝色框
参考源码自定义ARM输出层为:
| conv layer | size |
|---|---|
| relu4_3 | 64*64 |
| relu7 | 32*32 |
| relu8_2 | 16*16 |
| relu9_2 | 8*8 |
| relu10_2 | 4*4 |
| relu11_2 | 2*2 |
| relu12_2 | 1*1 |
需要注意:fc6和fc7采用conv层替代,conv6 的输入为32×32,采用dilated方式;conv7采用11卷积,输出32×32,同时增加5个类似ssd的conv输出层*
ARM模块的trick
- 作者借鉴了ParseNet的思想,对conv4_3和conv5_3层增加尺度信息(10,8).注意带了BN的网络不需要这方法。
对于scale的使用,ParseNet的作者给出实验结论,以512×512作为输入,backbone采用vgg16,此时conv4_3的size为64*64,直接与TCB模块进行Eltw sum会出现尺度不一致,导致训练不稳健。对该层输出计算L2_Norm ( x / ∣ ∣ x ∣ ∣ 2 , x = ( x 1 , . . . x d ) x/||x||_2, x=(x_1,...x_d) x/∣∣x∣∣2,x=(x1,...xd)),然后与scale进行element-wise product。

4. 损失函数
损失函数定义如下:
L ( { p i } , { x i } , { c i } , { t i } ) = 1 N a r m ( ∑ i L b ( p i , [ l i ∗ ⩾ 1 ] ) + ∑ i [ l i ∗ ⩾ 1 ] ) L r ( x i , g i ∗ ) ) + 1 N o d m ( ∑ i L m ( c i , l i ∗ ) + ∑ i [ l i ∗ ⩾ 1 ] ) L r ( t i , g i ∗ ) ) \mathcal L( \{p_i\} ,\{x_i\},\{c_i\},\{t_i\}) = \\ \frac{1}{N_{arm}}\big(\sum_i\mathcal L_b(p_i,[l_i^*\geqslant1])+\sum_i [l_i^*\geqslant1])\mathcal L_r(x_i,g_i^*)\big) \\ +\\ \frac{1}{N_{odm}}\big(\sum_i \mathcal L_m(c_i,l_i^*)+\sum_i [l_i^*\geqslant1])\mathcal L_r(t_i,g_i^*)\big) L({pi},{xi},{ci},{ti})=Narm1(i∑Lb(pi,[li∗⩾1])+i∑[li∗⩾1])Lr(xi,gi∗))+Nodm1(i∑Lm(ci,li∗)+i∑[li∗⩾1])Lr(ti,gi∗))
- 其中, i i i为mini-batch的anchor索引号, l i ∗ l_i^* li∗表示 i i i的ground truth类别, g i ∗ g_i^* gi∗表示ground truth的(x,y,w,h), p i p_i pi和 x i x_i xi表示ARM中的预测置信度和精细坐标。 c i c_i ci和 t i t_i ti表示ODM中的预测的类别和bounding box坐标。【】艾弗森括号表示条件真,否则为0.
- ARM中的 L b \mathcal L_b Lb表示交叉熵用于二分类,ODM中的 L m \mathcal L_m Lm表示softmax loss, L r \mathcal L_r Lr表示smooth L1.
(*可以考虑用focal loss 代替 softmax *)
5. 效果
以VGG-16为特征提取网络的RefineDet320在达到实时的前提下能在VOC 2007测试集上达到80以上的mAP,这个效果基本上是目前看到过的单模型在相同输入图像情况下的最好成绩
后续会补充code,有问题请留言