莫烦pytorch(16)——BN批标准化
1.构造数据集
import torch
from torch import nn
from torch.nn import init
import torch.utils.data as Data
import matplotlib.pyplot as plt
import numpy as np
N_SAMPLES = 2000
BATCH_SIZE = 64
EPOCH = 12
LR = 0.03
N_HIDDEN = 8
ACTIVATION = torch.tanh
B_INIT = -0.2 # bias
# training data
x=np.linspace(-7,10,N_SAMPLES)[:,np.newaxis]
noise=np.random.normal(0,2,x.shape)
y=np.square(x)+noise-5
#test data
test_x=np.linspace(-7,10,200)[:,np.newaxis]
noise=np.random.normal(0,2,test_x.shape)
test_y=np.square(test_x)+noise-5
train_x,train_y=torch.from_numpy(x).float(),torch.from_numpy(y).float()
test_x,test_y=torch.from_numpy(test_x).float(),torch.from_numpy(test_y).float()
train_dataset=Data.TensorDataset(train_x,train_y)
train_loader=Data.DataLoader(dataset=train_dataset,batch_size=BATCH_SIZE,shuffle=True,num_workers=2)
plt.scatter(train_x.data.numpy(),train_y.data.numpy(), c='#FF9359', s=50, alpha=0.2, label='train')
plt.legend(loc="upper left")
plt.show()

2.构建网络
torch.nn.BatchNorm1d(num_features, eps=1e-05, momentum=0.1, affine=True)
参数:
num_features: 来自期望输入的特征数,该期望输入的大小为’batch_size x num_features [x width]’
eps: 为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。
momentum: 动态均值和动态方差所使用的动量。默认为0.1。
affine: 一个布尔值,当设为true,给该层添加可学习的仿射变换参数。
Shape: - 输入:(N, C)或者(N, C, L) - 输出:(N, C)或者(N,C,L)(输入输出相同)
class Net(nn.Module):
def __init__(self, batch_normalization=False):
super(Net, self).__init__()
self.do_bn = batch_normalization
self.fcs = []
self.bns = []
self.bn_input = nn.BatchNorm1d(1, momentum=0.5) # 初始数据进行一次BN
for i in range(N_HIDDEN): # build hidden layers and BN layers
input_size = 1 if i == 0 else 10 #如果是第一次输入隐藏层,那么输入就是1个,否则就是10个
fc = nn.Linear(input_size, 10)
setattr(self, 'fc%i' % i, fc) # 设置一个参数,必要要在fn使用的后面
self._set_init(fc) # 初始化
self.fcs.append(fc)
if self.do_bn:
bn = nn.BatchNorm1d(10, momentum=0.5)
setattr(self, 'bn%i' % i, bn) # IMPORTANT set layer to the Module
self.bns.append(bn)
self.predict = nn.Linear(10, 1) # output layer
self._set_init(self.predict) # 初始化
#以上就是把所有fc放入fcs,bn放入bns中
def _set_init(self, layer): #莫烦老师说是初始化,我也不懂为什么
init.normal_(layer.weight, mean=0., std=.1)
init.constant_(layer.bias, B_INIT)
def forward(self, x):
pre_activation = [x]
if self.do_bn: x = self.bn_input(x)
layer_input = [x]
for i in range(N_HIDDEN):
x = self.fcs[i](x)
pre_activation.append(x)
if self.do_bn: x = self.bns[i](x) # batch normalization
x = ACTIVATION(x)
layer_input.append(x)
out = self.predict(x)
return out, layer_input, pre_activation
nets=[Net(batch_normalization=False),Net(batch_normalization=True)]
opts = [torch.optim.Adam(net.parameters(),lr=LR) for net in nets]
loss_func=torch.nn.MSELoss()
3.训练
if __name__ == "__main__":
f, axs = plt.subplots(4, N_HIDDEN + 1, figsize=(10, 5))
plt.ion() # something about plotting
plt.show()
# training
losses = [[], []] # recode loss for two networks
for step,(b_x,b_y) in enumerate(train_loader):
for net,opt in zip(nets,opts):
pred, _, _ = net(b_x)
loss = loss_func(pred, b_y)
opt.zero_grad()
loss.backward()
opt.step() # it will also learns the parameters in Batch Normalization
plt.ioff()
# plot training loss
plt.figure(2)
plt.plot(losses[0], c='#FF9359', lw=3, label='Original')
plt.plot(losses[1], c='#74BCFF', lw=3, label='Batch Normalization')
plt.xlabel('step');
plt.ylabel('test loss');
plt.ylim((0, 2000));
plt.legend(loc='best')
# evaluation
# set net to eval mode to freeze the parameters in batch normalization layers
[net.eval() for net in nets] # set eval mode to fix moving_mean and moving_var
preds = [net(test_x)[0] for net in nets]
plt.figure(3)
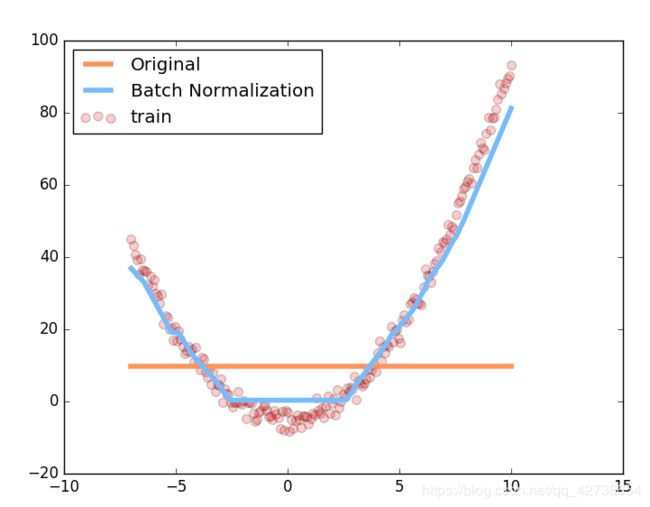
plt.plot(test_x.data.numpy(), preds[0].data.numpy(), c='#FF9359', lw=4, label='Original')
plt.plot(test_x.data.numpy(), preds[1].data.numpy(), c='#74BCFF', lw=4, label='Batch Normalization')
plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='r', s=50, alpha=0.2, label='train')
plt.legend(loc='best')
plt.show()
全代码
import torch
from torch import nn
from torch.nn import init
import torch.utils.data as Data
import matplotlib.pyplot as plt
import numpy as np
N_SAMPLES = 2000
BATCH_SIZE = 64
EPOCH = 12
LR = 0.03
N_HIDDEN = 8
ACTIVATION = torch.tanh
B_INIT = -0.2 # bias
# training data
x=np.linspace(-7,10,N_SAMPLES)[:,np.newaxis]
noise=np.random.normal(0,2,x.shape)
y=np.square(x)+noise-5
#test data
test_x=np.linspace(-7,10,200)[:,np.newaxis]
noise=np.random.normal(0,2,test_x.shape)
test_y=np.square(test_x)+noise-5
train_x,train_y=torch.from_numpy(x).float(),torch.from_numpy(y).float()
test_x,test_y=torch.from_numpy(test_x).float(),torch.from_numpy(test_y).float()
train_dataset=Data.TensorDataset(train_x,train_y)
train_loader=Data.DataLoader(dataset=train_dataset,batch_size=BATCH_SIZE,shuffle=True,num_workers=2)
plt.scatter(train_x.data.numpy(),train_y.data.numpy(), c='#FF9359', s=50, alpha=0.2, label='train')
plt.legend(loc="upper left")
plt.show()
class Net(nn.Module):
def __init__(self, batch_normalization=False):
super(Net, self).__init__()
self.do_bn = batch_normalization
self.fcs = []
self.bns = []
self.bn_input = nn.BatchNorm1d(1, momentum=0.5) # 初始数据进行一次BN
for i in range(N_HIDDEN): # build hidden layers and BN layers
input_size = 1 if i == 0 else 10 #如果是第一次输入隐藏层,那么输入就是1个,否则就是10个
fc = nn.Linear(input_size, 10)
setattr(self, 'fc%i' % i, fc) # 设置一个参数,必要要在fn使用的后面
self._set_init(fc) # 初始化
self.fcs.append(fc)
if self.do_bn:
bn = nn.BatchNorm1d(10, momentum=0.5)
setattr(self, 'bn%i' % i, bn) # IMPORTANT set layer to the Module
self.bns.append(bn)
self.predict = nn.Linear(10, 1) # output layer
self._set_init(self.predict) # 初始化
#以上就是把所有fc放入fcs,bn放入bns中
def _set_init(self, layer): #莫烦老师说是初始化,我也不懂为什么
init.normal_(layer.weight, mean=0., std=.1)
init.constant_(layer.bias, B_INIT)
def forward(self, x):
pre_activation = [x]
if self.do_bn: x = self.bn_input(x)
layer_input = [x]
for i in range(N_HIDDEN):
x = self.fcs[i](x)
pre_activation.append(x)
if self.do_bn: x = self.bns[i](x) # batch normalization
x = ACTIVATION(x)
layer_input.append(x)
out = self.predict(x)
return out, layer_input, pre_activation
nets=[Net(batch_normalization=False),Net(batch_normalization=True)]
opts = [torch.optim.Adam(net.parameters(),lr=LR) for net in nets]
loss_func=torch.nn.MSELoss()
def plot_histogram(l_in, l_in_bn, pre_ac, pre_ac_bn):
for i, (ax_pa, ax_pa_bn, ax, ax_bn) in enumerate(zip(axs[0, :], axs[1, :], axs[2, :], axs[3, :])):
[a.clear() for a in [ax_pa, ax_pa_bn, ax, ax_bn]]
if i == 0:
p_range = (-7, 10);the_range = (-7, 10)
else:
p_range = (-4, 4);the_range = (-1, 1)
ax_pa.set_title('L' + str(i))
ax_pa.hist(pre_ac[i].data.numpy().ravel(), bins=10, range=p_range, color='#FF9359', alpha=0.5)
ax_pa_bn.hist(pre_ac_bn[i].data.numpy().ravel(), bins=10, range=p_range, color='#74BCFF', alpha=0.5)
ax.hist(l_in[i].data.numpy().ravel(), bins=10, range=the_range, color='#FF9359')
ax_bn.hist(l_in_bn[i].data.numpy().ravel(), bins=10, range=the_range, color='#74BCFF')
for a in [ax_pa, ax, ax_pa_bn, ax_bn]: a.set_yticks(());a.set_xticks(())
ax_pa_bn.set_xticks(p_range);ax_bn.set_xticks(the_range)
axs[0, 0].set_ylabel('PreAct');axs[1, 0].set_ylabel('BN PreAct');axs[2, 0].set_ylabel('Act');axs[3, 0].set_ylabel('BN Act')
plt.pause(0.01)
if __name__ == "__main__":
f, axs = plt.subplots(4, N_HIDDEN + 1, figsize=(10, 5))
plt.ion() # something about plotting
plt.show()
# training
losses = [[], []] # recode loss for two networks
for epoch in range(EPOCH):
print('Epoch: ', epoch)
layer_inputs, pre_acts = [], []
for net,l in zip(nets,losses):
net.eval()
pred,layer_input,pre_act=net(test_x)
l.append(loss_func(pred,test_y).data.item())
layer_inputs.append(layer_input)
pre_acts.append(pre_act)
net.train()
plot_histogram(*layer_inputs,*pre_acts)
for step,(b_x,b_y) in enumerate(train_loader):
for net,opt in zip(nets,opts):
pred, _, _ = net(b_x)
loss = loss_func(pred, b_y)
opt.zero_grad()
loss.backward()
opt.step() # it will also learns the parameters in Batch Normalization
plt.ioff()
# plot training loss
plt.figure(2)
plt.plot(losses[0], c='#FF9359', lw=3, label='Original')
plt.plot(losses[1], c='#74BCFF', lw=3, label='Batch Normalization')
plt.xlabel('step');
plt.ylabel('test loss');
plt.ylim((0, 2000));
plt.legend(loc='best')
# evaluation
# set net to eval mode to freeze the parameters in batch normalization layers
[net.eval() for net in nets] # set eval mode to fix moving_mean and moving_var
preds = [net(test_x)[0] for net in nets]
plt.figure(3)
plt.plot(test_x.data.numpy(), preds[0].data.numpy(), c='#FF9359', lw=4, label='Original')
plt.plot(test_x.data.numpy(), preds[1].data.numpy(), c='#74BCFF', lw=4, label='Batch Normalization')
plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='r', s=50, alpha=0.2, label='train')
plt.legend(loc='best')
plt.show()