Python爬虫:猫眼电影反爬—动态字体处理(2020)
2020年5月25日更新,在爬了几百条后发现,有少部分数据会出错,出错概率很小。目前推测其原因是因为欧氏距离在对于(-1,0)和(0,1)这种数据计算结果差异不大的原因。有精度需求的建议改用别的距离计算算法。
前言
在百度「猫眼电影字体反爬」的时候,发现大多数热门的文章已经不管用了。因为目前猫眼的动态字体不仅仅只是文件和 unicode 编码的改变,还增加了字体对象的改变。

可以看见,两个字体存在着明显的差异,但字体比较小时,我们肉眼难以察觉得到。
下面我们一步步地来解决动态字体问题:
一、字体文件
首先在猫眼打开任意一部电影,打开浏览器开发者模式:
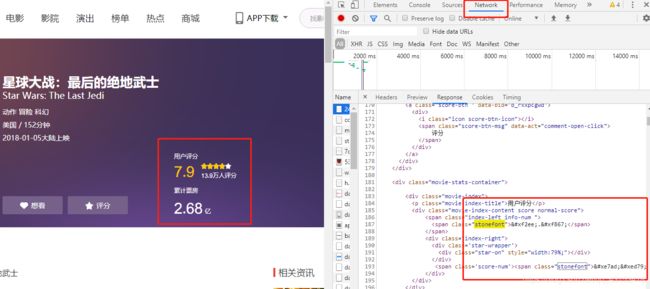
可以看到,这些评分和票房数据在 html 源码中对应的是一个个编码,这些编码是自定义的,一般是显示不出来的。因为浏览器在显示时采用了自定义的字体文件,所以可以显示成对应的数字。
要得到这些数字的关键是,找到对应的字体文件。在这些编码的附近,我们可以发现一个特别的关键字「stonefont」。我们在 html 源码中搜索一下这个关键字(stonefont),找到了如下内容。
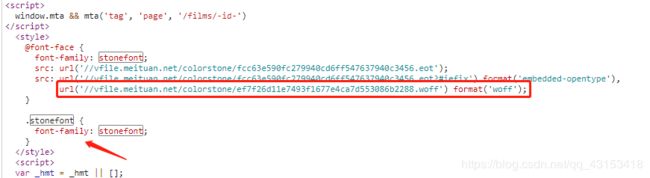
图中的三个 url 地址是当前页面使用的字体文件地址,浏览器就是使用它们来实现编码→字体。
我们下载最后一个地址中的文件,这个是一个 woff 文件。
woff 全名叫 Web 开发字体格式(Web Open Font Format),它是一种网页字体格式标准。
接下来需要用到两个工具:
1. Font Creator
Font Creator 是一个字体编辑器,可以用来制作字体文件(TTF)。我们需要它来查看每一个字体对应的编码。
下载可以直接百度「Font Creator」
2. fontTools
fontTools 是 python 的第三方库,可以借助该库来使用 python 代码操作 TTF 文件。
安装方法:
pip install fontTools
二、处理字体
首先,使用 Font Creator 打开我们下载的字体文件。

可以看到,猫眼的动态字体为数字 0-9,每个数字对应着一个编码。我们把这些数字对应的编码,在 Python 文件中构建成一个字典。(下面是我下载的字体文件对应的编码)
maoyan_dict = {
'uniF816': '1',
'uniE069': '2',
'uniE9FA': '8',
'uniEFD2': '0',
'uniE7CF': '3',
'uniE26F': '6',
'uniF6D9': '5',
'uniEFF5': '7',
'uniEFD4': '9',
'uniEADF': '4',
}
接下来我们刷新页面,再下载一个字体文件,对比一下两个字体文件的区别。
在 Python 文件中,使用 fontTools 库将下载的字体文件保存为 xml 文件。
from fontTools.ttLib import TTFont
TTFont('maoyan1.woff').saveXML('font1.xml')
TTFont('maoyan2.woff').saveXML('font2.xml')
然后,我们打开 xml 文件,关注到以下几点:
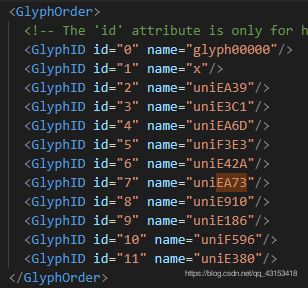
图中为编码对象,这里的 id 不是真实的。通过对比前面的图片,可以看到,前面有两个无用编码,因此在 Python 进行处理时要去掉。
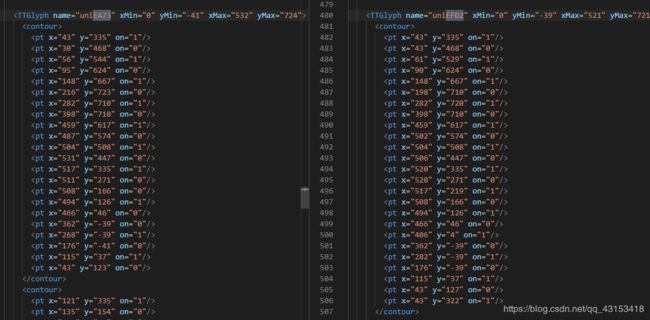
图为单个字体的轮廓描写,通过对这些坐标进行绘制,就能得到要显示出来的字体。
图中,左边和右边分别为同一个字体在两个文件中的轮廓描写。可以看到,两个文件对同一个字体的轮廓描写,无论是坐标值,还是数量都有差别。这样我们就不能通过判断两个文件中的字体对象是否相等,来映射字体。要知道,在上一年的时候,猫眼的字体对象还是不变的。
接下来,就是如何找出编码对应的字体了。
三、编码映射
我们可以通过字体的轮廓坐标,来判断两个字体是否相似。但由于不同字体文件中,字体的坐标列表存在数量不相等的情况,因此我们无法通过查找两个字体的坐标差值最小的值的方法来判断,使用这种方法会产生很大的误差。
既然是判断字体是否相似,那么可以采用相似度距离算法来解决这个问题。
常见相似度算法有:欧式距离(Euclidean Distance)、余弦相似度(Cosine)、皮尔逊相关系数(Pearson)、汉明距离(Hamming Distance)、曼哈顿距离(Manhattan Distance)
这里采用 欧式距离(Euclidean Distance) 算法来完成相似度判断。
N维向量间的欧式距离计算公式:
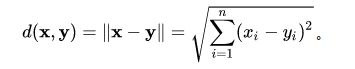
在 Python 中,有许多库提供了方便的计算操作,比如说 Numpy,使用 Numpy 库可以很方便的计算欧氏距离。
因为不同字体的坐标数量不一样,因此在计算欧式距离时,我们要使得两个字体的坐标列表具有相同的大小。下面是计算欧式距离的代码:
import numpy as np
# axis1 与 axis2 分别代表着两个字体的坐标
def compare_axis(axis1, axis2):
# 以坐标(0,0)补填空缺
if len(axis1) < len(axis2):
axis1.extend([0,0] for _ in range(len(axis2) - len(axis1)))
elif len(axis2) < len(axis1):
axis2.extend([0,0] for _ in range(len(axis1) - len(axis2)))
# 将列表转换为 Numpy 中的数组
axis1 = np.array(axis1)
axis2 = np.array(axis2)
# 计算并返回欧式距离
return np.sqrt(np.sum(np.square(axis1-axis2)))
四、处理逻辑
通过对上述步骤进行结合,得出以下处理逻辑:
-
下载一个字体文件作为对比文件(下面称为 base),并通过 Font Creator 找出字体对应的编码,然后在 Python 中手写编码字典,以及使用 fontTools 库提取 base 中的编码列表和字体坐标列表。
-
爬取页面时,获取并下载页面中的字体文件(下面称为 current),与对 base 进行处理的方法一样,使用 fontTools 库提取字体文件的编码列表和字体坐标列表。
-
循环访问 current 中的编码,计算其与 base 中每一个编码的欧式距离(越小的欧式距离,意味着两个字体越相似),并找出最小欧式距离的编码
-
利用在第一步构建的编码字典和上一步的欧氏距离,一一找出 current 中编码对应的字体。
五、效果展示
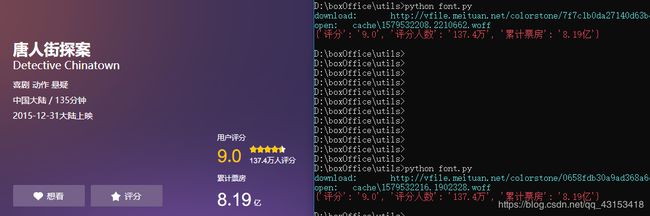
目前自己爬了几十次,没有发现有出错。这样看来,效果还不错。
如果需要完整代码,请浏览:https://github.com/LoliWithPick/maoyanFont
以上皆为本人学习时的笔录总结。若文章有错误之处,欢迎大家指正。