SMPL-CN
paper-reading
为方便理解smpl文章的主要实现思想,此文为论文中文解读,资料来源zju。
日后有空,会写出论文的主要推导过程以及值得注意的重点。
- 摘要:
我们提出了一个人体形状和姿势相关的形状变化的学习模型,它比以前的模型更准确,并与现有的图形管道兼容。我们的蒙皮多人线性模型(SMPL)是一种基于顶点的蒙皮模型,能够准确地表现人体自然姿势中的各种体形。从包括剩余姿势模板,混合权重,依赖于姿势的混合形状,依赖于身份的混合形状以及从顶点到关节位置的回归量的数据中学习模型的参数。与先前的模型不同,依赖于姿势的混合形状是姿势旋转矩阵的元素的线性函数。这种简单的配方使得能够从不同姿势的不同人的相对大量的对齐3D网格训练整个模型。我们使用线性或双四元数混合蒙皮定量评估SMPL的变体,并显示两者都比在相同数据上训练的BlendSCAPE模型更准确。我们还将SMPL扩展到逼真地模拟动态软组织变形。因为它基于混合蒙皮,SMPL与现有的渲染引擎兼容,我们将其用于研究目的。
- 1 Introduction

我们的目标是创造逼真的动画人体,可以代表不同的体形,自然地随姿势变形,并表现出像真人一样的软组织运动。我们希望这些模型能够快速呈现,易于部署并与现有的渲染引擎兼容。商业方法通常涉及手工操纵网格并手动雕刻混合形状以纠正传统蒙皮方法的问题。通常需要许多混合形状,并且构建它们所需的手动操作很大。作为替代方案,研究界一直致力于通过各种姿势的不同身体的示例扫描来学习统计身体模型。虽然很有希望,但这些方法与使用标准皮肤方法的现有图形软件和渲染引擎不兼容。
我们的目标是自动学习一个既现实又与现有图形软件兼容的身体模型。为此,我们描述了一种人体的“皮肤多人线性”(SMPL)模型,该模型可以逼真地表现出广泛的人体形状,可以呈现出与自然姿势相关的变形,展现出软组织动力学,动画效率很高,并且与现有的渲染引擎兼容(图1)。
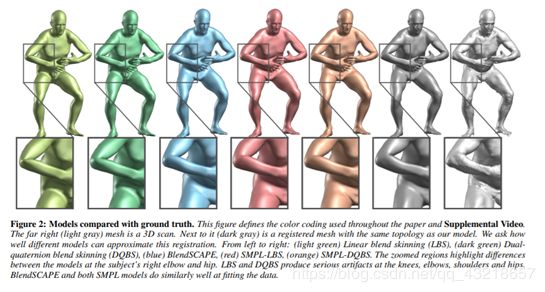
传统方法模拟顶点与底层骨架结构的关系。基本线性混合蒙皮(LBS)模型是使用最广泛的模型,受到所有游戏引擎的支持,并且渲染效率很高。不幸的是,它们在关节处产生不切实际的变形,包括众所周知的“太妃糖”和“领结”效应(见图2)。皮肤改善这些效果的方法已经付出了巨大的努力[Lewis 等人 2000; Wang和Phillips 2002; Kavan和Z ara 2005; Merry等人2006; Kavan等人2008]。从数据中学习高度逼真的身体模型也有很多工作[Allen 2006;安古洛夫等人 2005; Freifeld和Black 2012; Hasler等人2010; Chang和Zwicker 2009;陈等人2013。这些方法可以捕捉许多人的身体形状以及由于姿势造成的非刚性变形。最现实的方法可以说是基于三角形变形[Anguelov 2005;陈等人 2013; Hasler等人2010; Pons-Moll等2015年]。尽管进行了上述研究,现有模型要么缺乏真实性,要么不能与现有的包装一起使用,不能代表各种各样的体形,与标准图形管道不兼容,或者需要大量的手工劳动。
与之前的方法相比,我们工作的一个关键目标是使身体模型尽可能简单和标准,以便可以广泛使用,同时保持基于变形的模型的真实性。数据。具体来说,我们学习混合形状来纠正标准蒙皮的局限性。用于身份,姿势和软组织动力学的不同混合形状在通过混合蒙皮转化之前与休息模板相加地组合。我们方法的一个关键组成部分是我们将姿势混合形状公式化为零件旋转矩阵元素的线性函数。这种配方与以前的方法不同[Allen 2006; Merry等人2006; Wang和Phillips 2002]并且使混合形状的训练和动画变得简单。因为旋转矩阵的元素是有界的,所产生的变形也是有界的,这有助于我们的模型更好地推广。
我们的公式使用一个客观函数,它惩罚注册网格和我们模型之间的变形差异,从而实现数据训练。为了了解人们如何使用姿势变形,我们使用各种姿势的不同主题的1786高分辨率3D扫描。我们将模板网格与每次扫描对齐以创建训练集。我们优化混合权重,依赖于姿势的混合形状,平均模板形状(静止姿势)以及从形状到关节位置的回归量,以最小化模型在训练集上的顶点误差。该关节回归器预测关节的位置作为身体形状的函数,并且对于为任何身体形状制作逼真的姿势依赖性变形是关键的。从对齐的扫描中自动估计所有参数。
我们从CAESAR数据集中学习了男性和女性体形的线性模型[Robinette 2002](每性别约2000次扫描)使用主成分分析(PCA)。我们首先在每次扫描中注册模板网格并对数据进行标准化,这在学习基于顶点的形状模型时至关重要。由此产生的主要成分变为体形混合形状。
我们以各种形式训练SMPL模型,并将其定量地与BlendSCAPE模型进行比较[Hirshberg等2012年]使用完全相同的数据进行培训。我们定性地使用动画评估模型,并使用未用于训练的网格进行定量评估。我们将SMPL和BlendSCAPE拟合到这些网格,然后比较顶点误差。探索了SMPL的两个主要变体,一个使用线性混合蒙皮(LBS),另一个使用双四元数混合蒙皮(DQBS);令人惊讶的是,基于顶点的蒙皮模型(如SMPL)实际上比基于变形的模型(如BlendSCAPE)在相同数据上训练更准确。测试网格可用于研究目的,因此其他人可以与SMPL进行定量比较。
我们通过调整Dyna模型扩展SMPL模型以捕获软组织动力学[Pons-Moll等2015年]生成的Dynamic-SMPL或DMPL模型是从与Dyna相同的4D网格数据集中训练的。但是,DMPL基于顶点而不是三角形变形。我们计算SMPL和Dyna训练网格之间的顶点误差,转换为静止姿势,并使用PCA来减少维数,产生动态混合形状。然后,我们根据角速度和部件的加速度以及动态变形的历史来训练软组织模型,如[Pons-Moll等人2015年]。由于软组织动力学强烈依赖于体形,我们使用不同体重指数的身体训练DMPL,并学习依赖于体形的动态变形模型。在标准渲染引擎中动画化软组织动力学仅需要根据姿势序列计算动态线性混合形状系数。 Dyna和DMPL的并排动画显示DMPL更加真实。 SMPL的这一扩展说明了我们的加性混合形状方法的一般性,显示了变形如何依赖于身体形状,并演示了该方法如何为体形建模提供可扩展的基础。
在使用标准渲染引擎的CPU上,SMPL模型的动画效果明显快于实时。因此,SMPL解决了该领域的一个开放问题;它使动画师可以访问一个真实的学习模型。 SMPL基础模板在设计时考虑了动画;它有一个低多边形数,一个简单的顶点拓扑,干净的四边形结构,一个标准的装备,以及合理的面部和手部细节(虽然我们没有在这里装备手或面)。 SMPL可以表示为可以导入动画系统的Autodesk Filmbox(FBX)文件。我们将SMPL模型用于研究目的,并提供脚本以在Maya,Blender,虚幻引擎和Unity中驱动我们的模型。
- 2 Related Work
线性混合蒙皮和混合形状广泛用于整个动画行业。虽然研究界提出了许多新颖的铰接体形状模型,可以产生高质量的结果,但它们与行业惯例不相容。正如我们在下面总结的那样,许多作者试图将这些世界与不同程度的成功结合在一起。
混合蒙皮。骨架子空间变形方法(也称为混合蒙皮)将网格的表面附着到下面的骨架结构。网格表面中的每个顶点使用其相邻骨骼的加权影响进行变换。这种影响可以线性定义,如线性混合蒙皮(LBS)。 LBS的问题已被广泛发表,并且文献密集,试图解决这些问题的通用方法,如四元数或双四元数蒙皮,球形蒙皮等(例如[Wang和Phillips 2002; Kavan和Z ara 2005; Kavan 2008; Le and Deng 2012; Wang 2007])。然而,通用方法通常会产生不自然的结果,在这里我们专注于学习如何纠正混合皮肤的限制,无论具体的配方如何。
自动装备。自动装配LBS模型有很多工作(例如[De Aguiar等人2008; Baran和Popovic’2007; Corazza和Gambaretto 2014; Schaefer和Yuksel 2007])并且存在商业解决方案。这里最相关的是采用网格集合并推断骨骼以及关节和混合权重的方法(例如[Le and Deng 2014])。这些方法没有解决LBS模型的常见问题,因为它们没有学习校正混合形状。从网格序列创建的模型(例如[De Aguiar2008])可能无法很好地推广到新的姿势和运动。在这里,我们假设运动结构是已知的,尽管可以扩展该方法以使用上述方法来学习。上述方法的关键限制是模型不跨越体形空间。米勒等人[2010]部分通过使用预先装配模型的数据库进行自动装配来解决这个问题。他们将装配和蒙皮配置为将已知模型的蒙皮重量转换和调整到新模型的过程。他们的方法不会生成混合形状,产生标准LBS伪像,并且不会最小化明确的目标函数。
上述方法的关键限制是模型不跨越体形空间。米勒等人[2010]部分通过使用预先装配模型的数据库进行自动装配来解决这个问题。他们将装配和蒙皮配置为将已知模型的蒙皮重量转换和调整到新模型的过程。他们的方法不会生成混合形状,产生标准LBS伪像,并且不会最小化明确的目标函数。
混合形状。为了解决基本混合蒙皮的缺点,姿态空间变形模型(PSD)[Lewis等人2000]定义相对于基本形状的变形(作为顶点位移),其中这些变形是关节姿势的函数。这是后来的方法主要遵循的关键公式,也被称为“散乱数据插值”和“纠正包络”[Rouet and Lewis 1999]。我们采用更类似于加权姿态空间变形(WPSD)的方法[Kurihara和Miyata 2004; Rhee2006],其定义静止姿势中的校正,然后应用标准蒙皮方程(例如LBS)。我们的想法是为特定的关键姿势定义修正形状(雕刻),以便在添加到基本形状并通过混合蒙皮转换时,生成正确的形状。通常,人们找到示例姿势的距离(在姿势空间中)并使用一个函数,例如,径向基(RBF)核[Lewis等人2000],根据距离非线性地对样本进行加权。然后对雕刻的混合形状进行加权和线性组合。
这些方法都基于计算到样本形状的加权距离。因此,这些方法需要在运行时计算距离和权重以获得校正混合形状。对于给定动画(例如,在视频游戏中),通常基于姿势预先定义这些权重并将其“烘焙”到模型中。游戏引擎将烘焙重量应用于混合形状。雕刻过程通常由艺术家完成,然后仅用于将在动画中使用的姿势。
学习姿势模型。艾伦等人[2002]使用这种PSD方法,而不是手工雕刻校正,从注册的3D扫描中学习它们。他们的工作主要集中在对个体的躯干和手臂进行建模,而不是对整个人群进行建模。它们存储关键姿势的变形并在它们之间进行插值。当处于或接近存储的形状时,这些方法实际上是完美的。它们不倾向于很好地概括为新的姿势,需要密集的训练数据。目前尚不清楚需要多少这样的形状来模拟全方位的人体姿势。随着模型复杂性的增加,控制所有这些形状以及它们如何相互作用的复杂性也随之增加。
为了解决这个问题,Kry等人[2002]学习每个关节变形的低维PCA基础。依赖于姿势的变形是根据基矢量的系数来描述的。Kavan等人[2009]使用非线性蒙皮方法生成的示例网格来构造线性近似。 James和Twigg [2005]结合了直接从已注册的网格学习骨骼(非刚性,仿射骨骼)和蒙皮权重的想法。对于混合形状,他们使用类似于[Kry等人2002]。
解决混合剥皮限制的另一种方法是通过“多重包裹”(MWE)[Wang and Phillips 2002]。 MWE不是通过骨转换矩阵的加权组合对每个顶点进行加权,而是学习这些矩阵元素的权重。这增加了模型的容量(更多参数)。就像[James and Twigg 2005]一样,他们过度参数化骨骼转换以提供更具表现力的力量,然后使用PCA来消除不必要的自由度。他们的实验通常涉及用户交互,当前的游戏引擎不支持MWE方法。
Merry等人[2006]发现MWE过度参数化,因为它允许顶点根据全局坐标系中的旋转而变形。他们的动画空间模型以最小的代表功率损失减少参数化,同时还显示出与LBS相当的计算效率。
Mohr和Gleicher [2003]提出了另一种选择,他从示例网格中学习了一种有效的线性和真实模型。然而,为了解决LBS的问题,他们引入了额外的“骨头”来捕捉肌肉膨胀等效果。这些额外的骨骼增加了复杂性,非物理性,并且对于艺术家来说是不直观的。我们的混合形状更简单,更直观,更实用,并提供更大的真实感。同样,Wang等人[2007]引入与表面变形有关的关节。它们的旋转回归方法使用变形梯度,然后必须将其转换为顶点表示。
学习姿势和形状模型。上述方法着重于学习可摆动的单形模型。然而,我们的目标是拥有覆盖人体形状变化空间的逼真的姿势模型。早期的方法使用PCA来表征人体形状的空间[Allen2003; Seo等人]但是不要模拟身体形状如何随姿势变化。最成功的模型类基于SCAPE [Anguelov et al。根据三角形变形而不是顶点位移来表示体形和姿态相关的形状[Chen2013; Freifeld和Black 2012; Hasler等人2009年; Hirshberg等2012; PonsMoll等2015年]。这些方法从包含不同体形和姿势的训练扫描中学习形状变化的统计模型。三角形变形提供了不同变换的组合,例如体形变化,刚性部分旋转和姿势相关变形。韦伯等人[2007]提出了一种具有SCAPE属性的方法,但将其与示例形状相混合。这些模型与现有的动画软件不一致。
Hasler等人[2010]学习两个线性混合装备:一个用于姿势,一个用于体形。为了表示形状变化,它们引入了控制顶点形状变化的抽象“骨骼”。动画特定形状的角色涉及操纵形状和姿势骨骼。他们学习基础网格和混合权重,但不是混合形状。因此,该模型缺乏现实性。
我们想要的是一个基于顶点的模型,它具有三角形变形模型的表现力,因此它可以捕捉一系列自然形状和姿势。艾伦等人[2006]制定这样一个模型:对于给定的基体形状,它们定义具有分散/示例PSD的标准LBS模型以模拟姿势变形(使用RBF)。他们贪婪地定义“关键角度”来表示修正的混合形状,并将它们固定在所有的身体形状上。给定的体形由静止姿势的顶点,校正混合形状(在关键角度)和骨骼长度参数化;它们包含一个“字符向量”。给定不同身体的不同角色向量,他们学习一个低维潜在空间,让他们将角色向量推广到新的身体形状;他们从数据中学习这些参数。他们的模型比我们的模型更复杂,参数更少,并且从更少的数据中学习。有关此方法与SMPL的比较的更详细分析,请参见第7节。
- 3 Model Formulation
我们的皮肤多人线性模型(SMPL)如图3所示。与SCAPE一样,SMPL模型将体形分解为依赖于身份的形状和非刚性的姿势依赖形状; 与SCAPE不同,我们采用基于顶点的蒙皮方法,使用校正混合形状。单个混合形状表示为级联顶点偏移的矢量。我们从一个艺术家创建的网格开始,N = 6890个顶点和K = 23个关节。网格具有相同的男性和女性拓扑,空间变化的分辨率,干净的四边形结构,分割成部分,初始混合权重和骨架装备。零件分割和初始混合权重如图6所示。

![]()
下面我们将使用LBS和DQBS皮肤方法。 通常,蒙皮方法可以被认为是通用的黑盒子。 给定一种特定的蒙皮方法,我们的目标是学习纠正方法的局限性,以便对训练网格进行建模。 注意,学习的姿势混合形成由混合蒙皮函数引起的正确误差和由姿势变化引起的静态软组织变形。
下面我们描述模型中的每个术语。为方便起见,附录中的表1中提供了符号摘要。
混合皮肤 LBS版本和DQBS版本的SMPL区别在于结皮等式。大写加粗字母X 顶点向量代表着网格和混合形状。小写加粗字母代表特殊的顶点。顶点有时用齐次坐标表示,对于齐次坐标和标准坐标我们都用同样的注释。
身体的姿势被定义为标准骨骼rig。wk表示轴角,表示部件k的相对旋度。rig有k=23个关节,所以一个pose θ={w0,,,wk},共有 233+3=72个参数,每个部件有3个,加上root orientation 3个参数。w的单位向量表示单位标准旋转轴。因此每个关节j的轴角可以通过Rodrigues公式来转换成旋转矩阵。标准线性磨皮函数W(T,J,θ,w)公式,输入T静止姿势顶点,J关节坐标,θ姿势,w混合权重,输出姿势的顶点。T向量中的每个顶点t被转化成t’(每个列向量都是齐次坐标),使用2,3,4公式。其中w(k,i)是混合权重矩阵w的中的元素,表示部件k的旋度有多影响顶点i,exp(θ)表示当地关节j处的33旋度矩阵。G表示关节k的全局转化,G’表示移除静止姿态θ*后转化的转化。。。。

为了保证兼容性,我们保留了基本磨皮函数,更改了预测关节位置的函数。我们的模型M(β,θ,φ),其中Bs(β)Bp(θ)表示关节的偏移量的向量。我们将这些分别称为形状和姿势混合形状。
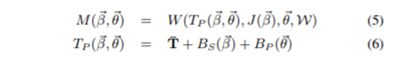
t顶点根据下式来变换

其中,bsi bpi是Bs Bp的向量,表示顶点t的shape和pose的混合型状偏移量。接下来我们将详细讨论这两项。
形状混合形状 不同人的身体形状被一个线性函数Bs描述

其中 ,β的模表示线性形状系数的数量。Sn表示形状位移的正交主成分。 是这些形状位移的矩阵。于是线性函数bs全都由矩阵S定义,S由训练网得到,详见4部分。
在符号上,分号右边的值表示学习参数,而左边的值表示动画师设置的参数。 为了方便标记,当在训练中没有明确优化时,我们经常省略这个参数。
姿势混合形状 我们定义一个函数,将姿势向量θ映射为相对旋度矩阵exp(w)的组合部件。因为rig有23个关节,R(θ)是一个长度为239=207的向量。R函数的元素都是关节角度的正弦和余弦,因此是非线性函数。
我们的公式不同于先前的工作,我们定义姿势混合形状为线性的,R(θ)=R(θ)-R(θ*)。其中θ*表示静止姿势。与静止姿势的顶点偏差
![]()
其中混合形状,Pn是顶点位移, 是全部207个姿势混合形状矩阵。此时,Bp全都由p矩阵表示,第四部分可以学到。
请注意,减去静止姿势的旋转矢量可确保姿势混合形状的贡献在rest pose中为零,这对于动画很重要。
关节位置 不同的身体形状有不同的关节位置。每个关节用静止姿态的3D坐标来表示。3D坐标的准确性很重要,否则使用蒙皮方程提出模型时会出现伪影。因为这个原因,我们定义关节为身体姿势β的一个函数
![]()
其中J是一个转换静止顶点到静止关节的矩阵。我们学习回归矩阵J,从不同人多种姿势,作为我们网络的一部分。这个矩阵模型的网格顶点很重要,如何结合他们来估计关节位置。
SMPL模型 我们现在可以指定所有参数 ![]() ,第四部分将描述如何学习。一旦学会它们就会被固定,并且通过分别改变β和θ来创建新的身体形状和姿势并进行动画制作。
,第四部分将描述如何学习。一旦学会它们就会被固定,并且通过分别改变β和θ来创建新的身体形状和姿势并进行动画制作。
SMPL模型最终被定义为M(β,θ,φ) = ![]() ,每个顶点被转换为
,每个顶点被转换为

13式 代表顶点i在应用混合形状后,S(m,i) P(n,i)表示与模板顶点ti对应的形状和姿势的混合模型
下面我们试验LBS和DQBS并训练每个参数。 我们将这些模型称为SMPL-LBS和SMPL-DQBS; SMPL-DQBS是我们的默认模型,我们使用SMPL作为SMPL-DQBS的简写。
- 4.训练
我们训练SMPL模型参数来最小化重建误差在两个数据集上。每个数据集包含与我们的模板具有相同拓扑的网格,这些网格已使用xx方法与高分辨率3D扫描对齐;我们称为这些对齐的网格“registration”。这些多姿势数据集包括40个人(20个男性20个女性)的1786个registration,图4展示了部分实例。多形状数据集包括男性的1700个registration,女性的2100的registration,如图5部分实例。我们定义第j个网格在多姿势数据集里为V(p,j),多形状数据集里为V(S,j)。
我们的目标是训练一组参数 ![]() 来减少顶点重建误差。因为我们的模型可以分解为形状和姿势,他们单独训练,容易优化。我们首先训练{J , W, P},使用我们的多姿势数据集,然后训练{T,S}使用我们的多形状数据集。我们训练男女性两个身体模型。
来减少顶点重建误差。因为我们的模型可以分解为形状和姿势,他们单独训练,容易优化。我们首先训练{J , W, P},使用我们的多姿势数据集,然后训练{T,S}使用我们的多形状数据集。我们训练男女性两个身体模型。
- 4.1 姿势参数训练
我们首先需要计算每个对象的静止模板T和关节的位置J。我们在优化注册特定参数j,主题特定参数{T,J}和全局参数{W,P}之间交替。我们随后学习J矩阵,从特定主体顶点T位置回归到特定主体的关节位置J回归。我们最小化Ed和一些正则化的项Ej Ey Ep Ew,定义如下。
数据项惩罚了配准顶点和模型顶点之间的欧氏距离平方。 其中 ,
其中 ,![]() s(j)配准j对应的主体索引。Preg是姿势训练集中网格的数量。
s(j)配准j对应的主体索引。Preg是姿势训练集中网格的数量。 ![]() 是静止姿势和关节的集合,p(subj)是数据集里主体的数量。
是静止姿势和关节的集合,p(subj)是数据集里主体的数量。
我们估计20736890=4278690参数,用于姿势混合形状p,436890=82680参数用来磨皮权重,3689023*3=1426230参数用来关节矩阵J。为了使效果表现良好,我们做出结几个假设。一个对称的正则项Ey,惩罚左右不对称的Jp和Tp  其中λu=100,U(T)是顶点T的镜像,通过翻过矢状平面并交换对称顶点。该术语鼓励对称模板网格,更重要的是,对称关节位置。 关节是未观察到的变量,沿着脊柱,它们特别难以定位。 虽然没有对称项的训练模型会产生合理的结果,但强制对称会产生视觉上更直观的动画模型。
其中λu=100,U(T)是顶点T的镜像,通过翻过矢状平面并交换对称顶点。该术语鼓励对称模板网格,更重要的是,对称关节位置。 关节是未观察到的变量,沿着脊柱,它们特别难以定位。 虽然没有对称项的训练模型会产生合理的结果,但强制对称会产生视觉上更直观的动画模型。

我们的模型手工分割成24部分如图6。我们使用这个分割来计算初始化估计关节中心和回归器J从顶点到中心点。回归器通过计算连接两个部件的顶点环的平均值来计算初始关节。当估计每个主题的关节时,我们正则化它们让其接近初始的预测:
 为了防止过拟合基于姿势的混合型状,我们正则化它使得
为了防止过拟合基于姿势的混合型状,我们正则化它使得
![]() 接近0 其中,|| · ||表示Frobenius norm,并且不使用L1正则化,因为这会导致混合形状更大的稀疏性。
接近0 其中,|| · ||表示Frobenius norm,并且不使用L1正则化,因为这会导致混合形状更大的稀疏性。
我们也正则化混合权重来接近初始权重,
![]() 通过简单地扩散分割来计算初始权重。
通过简单地扩散分割来计算初始权重。
所有汇总在一起,
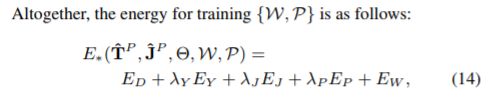 其中
其中
![]() 权重通过经验设置。我们的模型有大量的参数,正则化防止过拟合。当训练集增多时,数据项的表达能力也增强。我们的实验表没有过拟合。
权重通过经验设置。我们的模型有大量的参数,正则化防止过拟合。当训练集增多时,数据项的表达能力也增强。我们的实验表没有过拟合。
整个优化策略在4.3节里描述。
关节回归 调整上述的所有主体的模板网格和关节位置,但是我们希望预测关节位置当遇到新主题新形状时。为此,我们学习了一个回归矩阵J来预测训练的关节从训练的身体里。我们尝试了几种回归策略,最后发现非负最小二乘法包含一个鼓励权重增加的项数的效果最好。这个方法估计被使用预测关节的顶点的稀疏。使权重为正,加上一个不鼓励预测表面外的关节。 这些约束强制预测在表面点的凸包中。 图7显示了回归矩阵的非零元素,说明了稀疏的一组表面顶点线性组合以估计联合中心。

- 4.2 Shape Parameter Training
我们的形状空间被定义一个平均的主要的形状方向,{T, S}。它是通过在姿态归一化后从我们的多形状数据库中运行PCA进行形状配准来计算的。姿态归一化转化生的V为配准T,在静止姿态θ*里。归一化对确保姿势和形状分离是非常重要的。
我们首先估计姿势。我们称为 ![]() 为平均形状和平均关节位置,从对应的多姿势数据集。
为平均形状和平均关节位置,从对应的多姿势数据集。![]() 是模型和配准的边。边通过减去一对相邻顶点获得。为了估计姿态使用平均的生成的形状
是模型和配准的边。边通过减去一对相邻顶点获得。为了估计姿态使用平均的生成的形状 ![]() ,我们最小化下面的平方和项:
,我们最小化下面的平方和项:

其中对网格中所有的边进行求和。这允许我们获得一个更好的姿势估计而不需要知道主体具体的形状。
一旦姿势θj已知,我们可以最小化
![]()
这计算匹配姿势的形状,这个形状时姿势归一化的形状。
我们此时可以使用PCA来获得{T, S}。在给定有限数量的形状方向的情况下,该过程被设计为最大化所解释的静止姿势中的顶点偏移的方差。
请注意,从顶点构建形状基础时,姿势优化至关重要。 如果没有这一步骤,形状训练数据集中的主体的姿势变化将被捕获在形状混合形状中。 生成的模型不会被正确分解为形状和姿势。 另请注意,此方法与SCAPE或BlendSCAPE相关,其中PCA在每个三角形变形的空间中执行。 与顶点不同,三角形变形不存在于欧几里德空间[Freifeld and Black 2012]。 因此,顶点上的PCA更具原理性,并且与注册数据项一致,后者由平方顶点差异组成。
图8显示了前三个形状组件。 该图还显示了关节位置如何随着体形的变化而变化。 关节位置由球体显示,并使用学习的关节回归函数从表面网格计算。 在标准偏差上连接关节的线条说明了关节位置如何随形状线性变化。
