泰坦尼克号生存预测 数据分析+挖掘建模
数据集来源:Kaggle https://www.kaggle.com/vikichocolate/titanic-machine-learning-from-disaster
数据集各字段的含义
PassengerId 乘客编号
Survived 是否幸存
Pclass 船票等级
Name 乘客姓名
Sex 乘客性别
SibSp 亲戚数量(兄妹、配偶数)
Parch 亲戚数量(父母、子女数)
Ticket 船票号码
Fare 船票价格
Cabin 船舱
Embarked 登录港口
数据分析
导入数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
train_data = pd.read_csv('./train.csv')
test_data = pd.read_csv('./test.csv')
sub_data = pd.read_csv('./gender_submission.csv')
# 合并测试集合另外给的一个测试集生还与否的csv
test_data = pd.merge(test_data, sub_data)
train_data.discribe()
看一下总体情况
print(train_data.head())
print('*'*60)
print(train_data.sample(5))
print('*'*60)
print(train_data.tail())
print('*'*60)
print(train_data.describe())
print('*'*60)
print(train_data.dtypes)
此处选了describe看一哈
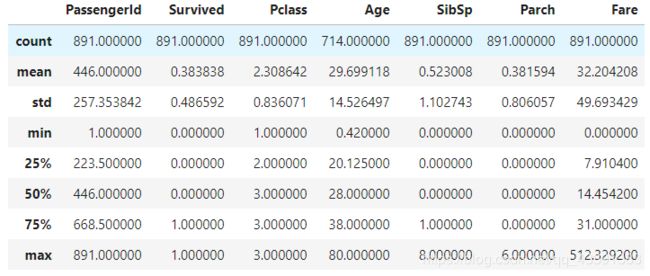
- 生还的肯定是少于死亡的
- 大部分人的船票等级都是2级
- Age属性有很多确实值,乘客的平均年龄是30岁左右,并且年龄的标准差比较大,可能年龄的分布不太均匀
- 大部分人没有带亲属出行,带了最多亲属的同质居然有8个
- 船票最大值是512,很可能是异常值
此处先把异常值和缺失值处理了,在进行可视化
异常值处理
由于检测到的离群点实在太多,173个,所以选择去除有两个属性为离群点的行。
# 检测异常值并处理
from collections import Counter
# 用上四分位数+d和下四分位数-d进行异常值检测
def outRangeFind(df, col_name_list) -> list:
err_indexes = []
for col_name in col_name_list:
temp_s = df[col_name]
QL = temp_s.quantile(0.25)
QU = temp_s.quantile(0.75)
IQR = QU - QL
err_sample_indexes = temp_s[(temp_s > (QU + 1.5*IQR)) | (temp_s < (QL - 1.5*IQR))].index
err_indexes = [*err_indexes, *err_sample_indexes]
err_dict = Counter(err_indexes)
temp = list(key for key, value in err_dict.items() if value > 2)
return temp
err_indexes = outRangeFind(train_data, ['Age', 'SibSp','Parch', 'Fare'])
print(len(err_indexes))# 异常值数量
print(train_data.loc[err_indexes]) # 查看异常的对象
train_data.drop(index=err_indexes, inplace=True) # 去除异常的对象
err_indexes = outRangeFind(test_data, ['Age', 'SibSp','Parch', 'Fare'])
print(len(err_indexes))# 异常值数量
print(test_data.loc[err_indexes]) # 查看异常的对象
test_data.drop(index=err_indexes, inplace=True) # 去除异常的对象
被检测为异常值的行

缺失值处理
替换的时候一定要注意当前的是Series对象,还是DataFrame对象,如果替换的时候用了DateFrame对象,全部数据都变了。。。很可怕
# 检测Age字段数值是否服从正态分布
# 如果符合正太分布,就用 mean +- 1*std 来 random 选出随机数填充
import scipy.stats as ss
print(ss.normaltest(train_data['Age'].dropna()))
print(ss.normaltest(train_data['Age'].fillna(train_data['Age'].mean())))
p值 < 0.05,不服从正态分布
NormaltestResult(statistic=18.105032952089758, pvalue=0.00011709599657350757)
NormaltestResult(statistic=43.858965850515766, pvalue=2.9932746976104566e-10)
此处直接用均值填充缺失值
print(len(train_data['Age'][train_data['Age'].isnull()])) # 年龄缺失值的数量
print(train_data['Age'].mean()) # 查看年龄的均值
# train_data[train_data['Age'].isnull()] = train_data['Age'].mean() 危险
# 填充年龄的缺失值为均值
train_data['Age'][train_data['Age'].isnull()] = train_data['Age'].mean()
test_data['Age'][test_data['Age'].isnull()] = test_data['Age'].mean()
去除多余的属性

- 姓名应该和生还率没有什么关系,所以去掉
- Ticket的数据很混乱,唯一值非常很多,也不适合拿去建模,去掉
train_data['Ticket'].value_counts()

- 乘客ID也没啥用
- 所在船舱的缺失值十分多,没啥建设性,也去掉
train_data.drop(['Name', 'PassengerId', 'Ticket', 'Cabin'], axis=1, inplace=True)
test_data.drop(['Name', 'PassengerId', 'Ticket', 'Cabin'], axis=1, inplace=True)
看一下登陆港口有没有缺失值或者奇怪的值
不知为啥有的数据集此处会出现两个异常值29.6
train_data['Embarked'].value_counts()
test_data['Embarked'].value_counts()
# 都没有别的奇怪值,我看过其他的数据集好像此处会有两个29
S 270
C 102
Q 46
Name: Embarked, dtype: int64
train_data.head()

现在数据处理得差不多了,就差连续值数据的离散化了
可视化
# 看一下此时各部分的情况
%matplotlib inline
sns.pairplot(train_data, hue='Survived',palette="husl")

里面离散值非常多,只有两个连续值
因为主要分析生还率和其他属性的关系,所以不会涉及太多除了生存率以外的其他属性的复合分析
性别,船票等级和生还
g = sns.catplot(x="Pclass", y="Survived", hue="Sex", data=train_data,
height=6, kind="bar", palette="muted")
g.despine(left=True)

可以发现,女性的生还率明显高于男性,并且船票等级越高,生还率越高
年龄,船票等级,生还
%matplotlib inline
sns.set(style="whitegrid", palette="pastel", color_codes=True)
sns.violinplot(x="Pclass", y="Age", hue="Survived",
split=True,
palette={1: "y", 0: "b"},
data=pd.read_csv('./train.csv').drop(['Name', 'PassengerId', 'Ticket', 'Cabin'], axis=1).dropna())
sns.despine(left=True)

可以发现,每个年龄段都有不同船票的分布,船票等级为1的死亡者的年龄集中在40-60岁,另外俩个等级死亡者集中在20-40岁,船票等级越低,死亡者的年龄也越低,同时生还者的年龄也越低,生还者主要集中在20-40岁
船票费用,年龄,生还
sns.set(style="white")
# 散点图
sns.relplot(x="Fare", y="Age",hue='Survived',
sizes=(40, 400), alpha=.5, palette="muted",
height=6, data=pd.read_csv('./train.csv').drop(['Name', 'PassengerId', 'Ticket', 'Cabin'], axis=1).dropna())
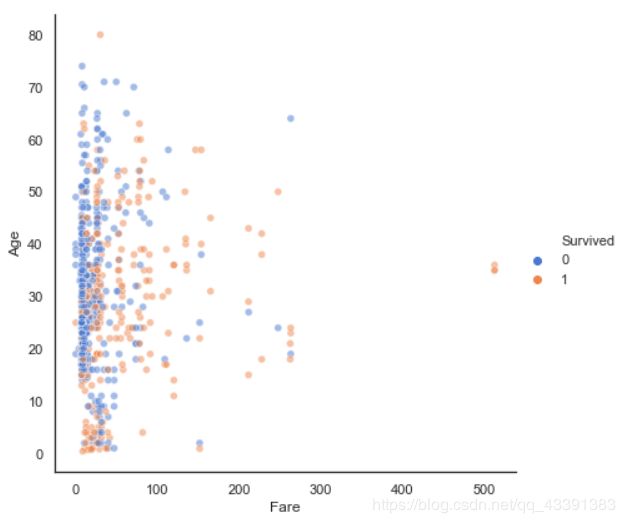
不是年龄越大买的船票价格越高,他们之间其实关系不太大,点的分布太散
性别,年龄,生还
%matplotlib inline
sns.set(style="darkgrid")
pal = dict(male="r", female="b")
# 刻上逻辑回归的曲线
g = sns.lmplot(x="Age", y="Survived", col="Sex", hue="Sex", data=pd.read_csv('./train.csv').drop(['Name', 'PassengerId', 'Ticket', 'Cabin'], axis=1).dropna(),
palette=pal, y_jitter=.02, logistic=True)
g.set(xlim=(0, 80), ylim=(-.05, 1.05))

可以发现,女性的生存率高于男性,并且年龄越大,男性生还率更低,女性生还率更高
带上兄妹、配偶的人和带上父母、子女的人和生还率的关系
# 看带上兄妹、配偶的人和带上父母、子女的人的关系
%matplotlib inline
# sns.set(style="whitegrid")
f, ax = plt.subplots(figsize=(10, 8))
sns.set_color_codes("pastel")
# errwidth=0 去除误差线
sns.barplot(x='Parch', y='Survived', data=train_data, color="b", label='Parch', errwidth=0)
sns.set_color_codes("muted")
sns.barplot(x='SibSp', y='Survived', data=train_data, color="b", label='SibSp', errwidth=0)
ax.legend(ncol=2, frameon=True)
sns.despine(left=True, bottom=True)

可以发现带上了兄妹配偶的,基本也带上了父母子女,生还率和SibSp或Parch没有明显的相关关系
费用,登陆港口,生还
# 费用,登陆港口,生还
sns.swarmplot(x='Embarked',y='Fare',hue='Survived',data=train_data)
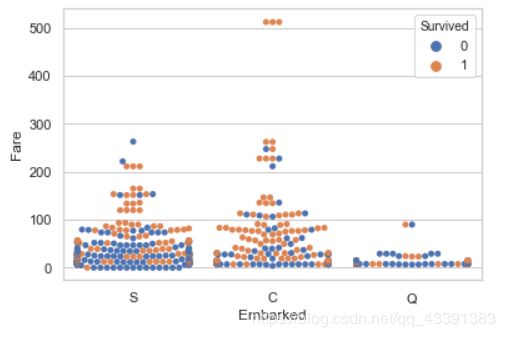
生还率占比最高的是C港口,S港口和C港口费用都差不多,Q港口费用最低,C港口出现了3个船票最大值的点,so画一个箱线图看一下它是否是离群点
# 箱线图
sns.boxplot(x="Embarked", y="Fare",
hue="Survived",
data=train_data)

费用确实是有不少离群点的,但是我们筛选异常数据的时候,是要有两项属性异常才去掉这一行的,因为离群点实在太多的缘故
那么Fare为何会出现辣么多离群点呢?看一下Fare属性的峰态系数
train_data['Fare'].skew()
5.063298813640095 挺高的哎,回一下图看一下
sns.distplot(train_data['Fare'],color = 'r')

因为Fare的数据大量的左偏,分布很不均匀,所以会出现很多离群点
特征处理
先看一下现在的数据情况
train_data.head(10)

要把Sex和Embarked进行数值化
Age和Fare进行离散化
Age和Fare进行离散化
# 因为要使用决策树算法建模,把连续值进行分箱处理,转化为离散值
# 因为费用最偏严重,此处使用等深分箱
print(pd.qcut(train_data['Fare'], q=5).value_counts())
print(pd.qcut(test_data['Fare'], q=5).value_counts())
S1 = pd.qcut(train_data['Fare'], q=5, labels=[0, 1, 2, 3, 4])
S2 = pd.qcut(test_data['Fare'], q=5, labels=[0, 1, 2, 3, 4])
# pd.cut(train_data['Fare'], bins=5, labels=[0,1,2,3,4])
train_data['Fare'] = S1
test_data['Fare'] = S2
train_data.head(10)
# 年龄值有很多缺失值,并且我们把确实值填为了均值,所以用等深
pd.qcut(train_data['Age'], q=5, labels=[0,1,2,3,4]).value_counts()
S3 = pd.qcut(train_data['Age'], q=5, labels=[0, 1, 2, 3, 4])
S4 = pd.qcut(test_data['Age'], q=5, labels=[0, 1, 2, 3, 4])
# pd.cut(train_data['Fare'], bins=5, labels=[0,1,2,3,4])
train_data['Age'] = S3
test_data['Age'] = S4
train_data.head(10)
要把Sex和Embarked进行数值化
train_data['Sex']=(train_data['Sex']=='male').astype(int)
labels = train_data['Embarked'].unique().tolist()
train_data['Embarked'] = train_data['Embarked'].apply(lambda s: labels.index(s))
test_data['Sex']=(test_data['Sex']=='male').astype(int)
labels = test_data['Embarked'].unique().tolist()
test_data['Embarked'] = test_data['Embarked'].apply(lambda s: labels.index(s))
train_data.head(10)
挖掘建模
此处是一个二分类问题,用决策树算法进行建模,来对测试数据进行分类预测。
特征选择
features = [feature for feature in train_data.columns if feature != 'Survived']
train_features = train_data[features]
train_labels = train_data['Survived']
test_labels = test_data['Survived']
test_features = test_data[features]
构建决策树模型
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier()
clf.fit(train_features, train_labels)
train_score = clf.score(train_features, train_labels)
test_score = clf.score(test_features, test_labels)
print(train_score)
print(test_score)
0.8693181818181818
0.8484107579462102
。。。预测的准确率很不错
画出决策树
# 画出决策树
feature_name = features
import graphviz
from sklearn.tree import export_graphviz
dot_data = export_graphviz(clf
,feature_names=feature_name
,filled=True
,rounded=True)
graph = graphviz.Source(dot_data)
graph
查看特征的重要性
# 查看特征的重要性
sorted([*zip(feature_name, clf.feature_importances_)], key=lambda x: x[1], reverse=True)
[('Sex', 0.4929149115476557),
('Pclass', 0.16501570592949835),
('Age', 0.11251192928288742),
('SibSp', 0.0787931844840506),
('Parch', 0.06048826718072025),
('Fare', 0.045992773296087905),
('Embarked', 0.04428322827909995)]
性别是影响模型最大的特征
调参
加大随机数生存的随机性看一下
# 调参
clf = DecisionTreeClassifier(random_state=30)
clf.fit(train_features, train_labels)
test_score = clf.score(test_features, test_labels)
print(test_score)
0.8459657701711492
调节树的最大深度,增大树分支时选取特征的随机性,限制最小的分割样本数
clf = DecisionTreeClassifier(random_state=30
,splitter='random'
,max_depth=3
,min_samples_leaf=10
,min_samples_split=10
)
clf.fit(train_features, train_labels)
test_score = clf.score(test_features, test_labels)
print(test_score)
0.9437652811735942
居然预测率异常的高
遍历寻找一下什么深度预测效果最好
test = []
for i in range(10):
clf = DecisionTreeClassifier(max_depth=i+1
,random_state=30
,splitter='random'
# ,min_samples_leaf=10
# ,min_samples_split=10
)
clf = clf.fit(train_features, train_labels)
score = clf.score(test_features, test_labels)
test.append(score)
plt.plot(list(range(1, 11)), test, color='r', label='max_depth')
plt.legend()
plt.show()
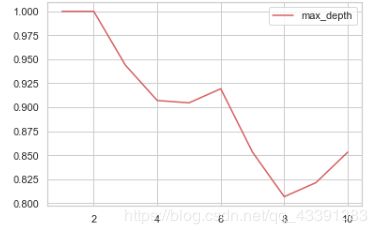
。。。为啥预测百分百预测的能力都出来了,感觉很奇怪,有大神能回答一下这个问题嘛
看一下这个预测率百分百的树的样子
