【编译原理】LL(1)分析方法 生成语法树(c++实现)
基本流程
输入文法
消除左递归
提取左公共因子
求FIRST集
求FOLLOW集
LL分析表
输入串
语法分析程序
LL分析表
语法树
算法
从龙书上截的,个人认为描述的还是挺清楚的
- 消除左递归:

- 提取左公共因子

- LL(1)文法的判断:

- 求FIRST集合:

- 求FOLLOW集合:

- 求LL(1)分析表

- 表驱动的预测语法分析过程:

C++实现
构建语法树部分参照了这位大佬
#include
//遍历left的其他产生式
for(int i=1; i<P.size(); i++)
{
string right=P[i];
right+=" ";
string cmp=right.substr(0,right.find(" "));
//cout<<"后面产生式中第一个token:"<
if(cmp!=temp)
{
break;
}
else
{
prefix+=temp+" ";
}
P[i]=right.substr(right.find(" ")+1);
}
firstP=firstP.substr(firstP.find(" ")+1);
}
//去除末尾空格
if(prefix.size()>0)
prefix.pop_back();
return prefix;
}
//消除直接左递归
void immediateLeftRecursionRemoval(string Ai)
{
string newNT=Ai+"'";//新的非终结符号
NT.insert(find(NT.begin(),NT.end(),Ai)+1,newNT);
vector<string>newFirstRight;//新的产生式右部
vector<string>newSecondRight;
for(auto it=production[Ai].begin(); it<production[Ai].end(); it++)
{
string right=*it;
string temp=right;
temp+="#";
//含有直接左递归:Ai'->aAi'|@
if(strcmp(const_cast<char*>(Ai.c_str()),strtok(const_cast<char*>(temp.c_str())," #"))==0)
{
right=right.substr(right.find(" ")+1)+" "+newNT;
newSecondRight.push_back(right);
}
//不含:Ai->BAi'
else
{
right+=" "+newNT;
newFirstRight.push_back(right);
}
}
newSecondRight.push_back("@");
production[newNT]=newSecondRight;
production[Ai]=newFirstRight;
}
public:
AST ast;//语法树
//构造函数,读入所需的四元组
Grammar(string fileName)
{
readGrammar(fileName);
}
//填产生式
void addP(string left,string right)
{
right+="#";//'#'作为每句文法结尾标志
string pRight="";
for(int i=0; i<right.size(); i++)
{
if(right[i]=='|'||right[i]=='#')
{
production[left].push_back(pRight);
pRight="";
}
else
{
pRight+=right[i];
}
}
}
//填终结符
void addT()
{
string temp="";
for(string left:NT)
{
for(string right:production[left])
{
right+="#";
for(int i=0; i<right.size(); i++)
{
if(right[i]=='|'||right[i]==' '||right[i]=='#')
{
//不是非终结,且不是空,则加入终结符号
if((find(NT.begin(),NT.end(),temp)==NT.end())&&temp!="@")
{
T.push_back(temp);
}
temp="";
}
else
{
temp+=right[i];
}
}
}
}//end left
//终结符去重
sort(T.begin(),T.end());
T.erase(unique(T.begin(), T.end()), T.end());
}
//读取文法规则
void readGrammar(string fileName)
{
ifstream input(fileName);
if(!input)
{
cout<<fileName<<" Failed"<<endl;
}
//读取文法规则
string line;//读入的每一行
while(getline(input,line))
{
int i;
//读取左部
string left="";
for(i=0; line[i]!='-'&&i<line.size(); i++)
{
left+=line[i];
}
NT.push_back(left);//左部加入非终结符号集
//读取右部
string right=line.substr(i+2,line.size()-i);//获取产生式右部
addP(left,right);//添加产生式
}
addT();//添加终极符
S=*NT.begin();
input.close();
}
//消除左递归
void leftRecursionRemoval()
{
//遍历每一个NT
for(int i=0; i<NT.size(); i++)
{
string Ai=NT[i];
//cout<<"Ai:"<
vector<string>newRight;//新的产生式右部
//遍历NT的每一个产生式
for(auto it=production[Ai].begin(); it<production[Ai].end(); it++)
{
string right=*it;
//cout<<"right:"<
int flag=0;//判断是不是左递归
//遍历改变过的产生式
for(int j=0; j<i; j++)
{
string Aj=NT[j];
//cout<<"Aj:"<
string temp=right+"#";
//如果有Ai->AjB,替换Aj为Aj的产生式
if(strcmp(const_cast<char*>(Aj.c_str()),strtok(const_cast<char*>(temp.c_str())," #"))==0)
{
flag=1;
cout<<Aj<<" ";
cout<<temp<<endl;
for(auto jt=production[Aj].begin(); jt<production[Aj].end(); jt++)
{
string s=*jt+" "+right.substr(right.find(" ")+1);//substr(1)是从空格位置往后的子串
//cout<<"s:"<
newRight.push_back(s);
}
}
}
//没有可替换的产生式
if(flag==0)
newRight.push_back(right);
}
if(i!=0)
production[Ai]=newRight;
//去除包含Ai的直接左递归
for(int k=0; k<production[Ai].size(); k++)
{
string right=production[Ai][k];
string temp=right;
temp+="#";
if(strcmp(const_cast<char*>(Ai.c_str()),strtok(const_cast<char*>(temp.c_str())," #"))==0)
immediateLeftRecursionRemoval(Ai);
}
}
}
//提取左因子
void leftFactoring()
{
//printV();
for(int i=0; i<NT.size(); i++)
{
string left=NT[i];
string a=maxPrefix(left);
//cout<<"left:"<
if(a!="")
{
string newNT=left+"'";
NT.insert(find(NT.begin(),NT.end(),left),newNT);
vector<string>newRight1;//A的产生式
vector<string>newRight2;//A'的产生式
for(auto it=production[left].begin(); it<production[left].end(); it++)
{
string right=*it;
string newRight;
//产生式不含a,直接放进A的产生式中
if(right.find(a)==string::npos)
newRight1.push_back(right);
//产生式含a
else
{
if(right.find(a)+a.size()!=right.size())
{
newRight=right.substr(right.find(a)+a.size()+1);
}
//a后面是空的
else
{
newRight="@";
}
newRight2.push_back(newRight);
}
}
//A->aA'
newRight1.push_back(a+" "+newNT);
production[left]=newRight1;
production[newNT]=newRight2;
}
}
}
//获得FIRST集合
void getFirst()
{
FIRST.clear();
//终结符号或@
FIRST["@"].insert("@");
for(string X:T)
{
FIRST[X].insert(X);
}
//非终结符号
int j=0;
while(j<4)
{
for(int i=0; i<NT.size(); i++)
{
string A=NT[i];
//遍历A的每个产生式
for(int k=0; k<production[A].size(); k++)
{
int Continue=1;//是否添加@
string right=production[A][k];
//X是每条产生式第一个token
string X;
if(right.find(" ")==string::npos)
X=right;
else
X=right.substr(0,right.find(" "));
//cout<
//FIRST[A]=FIRST[X]-@
if(!FIRST[X].empty())
{
for(string firstX:FIRST[X])
{
if(firstX=="@")
continue;
else
{
FIRST[A].insert(firstX);
Continue=0;
}
}
if(Continue)
FIRST[A].insert("@");
}
}
}
j++;
}
}
//获得FOLLOW集合
void getFollow()
{
//将界符加入开始符号的follow集
FOLLOW[S].insert("#");
int j=0;
while(j<4)
{
//遍历非终结符号
for(string A:NT)
{
for(string right:production[A])
{
for(string B:NT)
{
//A->Bb
if(right.find(B)!=string::npos)
{
/*找B后的字符b*/
string b;
int flag=0;
//识别到E'
if(right[right.find(B)+B.size()]!=' '&&right[right.find(B)+B.size()]!='\0')
{
string s=right.substr(right.find(B));//E'b
string temp=right.substr(right.find(B)+B.size());//' b
//A->E'
if(temp.find(" ")==string::npos)
{
B=s;//B:E->E'
FOLLOW[B].insert(FOLLOW[A].begin(),FOLLOW[A].end());//左部的FOLLOW赋给B
flag=1;
}
//A->E'b
else
{
B=s.substr(0,s.find(" "));
temp=temp.substr(temp.find(" ")+1);//b
//b后无字符
if(temp.find(" ")==string::npos)
b=temp;
//b后有字符
else
b=temp.substr(0,temp.find(" "));
}
}
//A->aEb
else if(right[right.find(B)+B.size()]==' ')
{
string temp=right.substr(right.find(B)+B.size()+1);//B后的子串
//b后无字符
if(temp.find(" ")==string::npos)
b=temp;
//b后有字符
else
b=temp.substr(0,temp.find(" "));
}
//A->aE
else
{
FOLLOW[B].insert(FOLLOW[A].begin(),FOLLOW[A].end());
flag=1;
}
//FOLLOW[B]还没求到
if(flag==0)
{
//FIRST[b]中不包含@
if(FIRST[b].find("@")==FIRST[b].end())
{
FOLLOW[B].insert(FIRST[b].begin(),FIRST[b].end());
}
else
{
for(string follow:FIRST[b])
{
if(follow=="@")
continue;
else
FOLLOW[B].insert(follow);
}
FOLLOW[B].insert(FOLLOW[A].begin(),FOLLOW[A].end());
}
}
}
}
}
}
j++;
}
}
//判断两集合是否相交
int hasIntersection(set<string>first,set<string>second)
{
for(string b:second)
{
//如果first和second有重复元素,则相交
if(first.find(b)!=first.end())
return 1;
}
return 0;
}
//判断是否是LL(1)文法
int judgeLL1()
{
getFirst();
getFollow();
printFIRST();
printFOLLOW();
for(string A:NT)
{
for(string apro:production[A])
{
apro+=" ";
for(string bpro:production[A])
{
bpro+=" ";
if(apro!=bpro)
{
string a=apro.substr(0,apro.find(" "));
string b=bpro.substr(0,bpro.find(" "));
//FIRST有交集,不是LL(1)
if(hasIntersection(FIRST[a],FIRST[b]))
return 0;
//如果FIRST[a]中有@,FIRST[b]和FOLLOW[A]相交,则不是LL(1)文法
if(FIRST[a].find("@")!=FIRST[a].end())
{
if(hasIntersection(FIRST[b],FOLLOW[A]))
return 0;
}
if(FIRST[b].find("@")!=FIRST[b].end())
{
if(hasIntersection(FIRST[a],FOLLOW[A]))
return 0;
}
}
}
}
}
return 1;
}
//获得分析表
void getTable()
{
for(string A:NT)
{
for(string right:production[A])
{
string first;//right里第一个token
if(right.find(" ")==string::npos)
first=right;
else
first=right.substr(0,right.find(" "));
right=right.insert(0,A+"->");
pair<string,string>symbol;
//FIRST集里不含@:a来自FIRST[first]
if(FIRST[first].find("@")==FIRST[first].end())
{
for(string a:FIRST[first])
{
symbol=make_pair(A,a);
Table[symbol]=right;
//cout<
}
}
//FIRST集里含@:a来自FOLLOW[a]
else
{
for(string a:FOLLOW[A])
{
symbol=make_pair(A,a);
Table[symbol]=right;
//cout<
}
}
}
}
printTable();
}
//语法分析过程
int parsing(string input)
{
stack<string>Analysis;
input+=" #";
//文法开始符号入栈
Analysis.push("#");
Analysis.push(S);
ast.root=new node;//语法树根节点
auto cur_node=ast.root;
cur_node->name=S;
vector<vector<void *>>ast_stack;//语法分析栈(递归栈)
int stack_deep=0;
//进入语法树的下一层
ast_stack.push_back(vector<void*>());
//语法栈中两个局部变量
ast_stack.back().push_back(0);
ast_stack.back().push_back(cur_node);
string nextInput=input.substr(0,input.find(" "));//下一个读入的token
while(Analysis.top()!="#"&&input!="#")
{
string top=Analysis.top();
nextInput=input.substr(0,input.find(" "));//下一个读入的token
//cout<
//匹配
if(find(T.begin(),T.end(),top)!=T.end()&&nextInput==top)
{
//cout<<"匹配"<
Analysis.pop();
input=input.substr(input.find(" ")+1);//input去掉读过的一个token
//索引右移动
while(ast_stack.size()>1)
{
ast_stack.back()[0]=(void*)((int)ast_stack.back()[0]+1);
int index=(int)ast_stack.back()[0];
int parent_idx=(int)ast_stack[ast_stack.size()-2][0];
TreeNode Node=(TreeNode)ast_stack[ast_stack.size()-2][parent_idx+1];
if(Node->child.size()==index)
{
ast_stack.pop_back();
continue;
}
break;
}
}
//推导
else if(find(NT.begin(),NT.end(),top)!=NT.end()&&find(T.begin(),T.end(),nextInput)!=T.end())
{
pair<string,string>symbol;
symbol=make_pair(top,nextInput);
if(!Table[symbol].empty())
{
Analysis.pop();
string pro=Table[symbol];//产生式
//产生式右部入栈
while(pro.find(" ")!=string::npos)
{
string lastToken=pro.substr(pro.rfind(" ")+1);
Analysis.push(lastToken);
pro=pro.substr(0,pro.rfind(" "));
}
//如果右部是@,就不用入栈了
if(pro.substr(pro.find("->")+2)!="@")
Analysis.push(pro.substr(pro.find("->")+2));
int index=(int)ast_stack.back()[0];
TreeNode Node=(TreeNode)ast_stack.back()[index+1];
//进入语法树下一层
ast_stack.push_back(vector<void*>());
ast_stack.back().push_back(0);
//产生式右部
string pdc=Table[symbol].substr(Table[symbol].find("->")+2);
while(1)
{
TreeNode newNode=new node;
if(pdc.find(" ")!=string::npos)
{
string firstToken=pdc.substr(0,pdc.find(" "));
newNode->name=firstToken;
Node->child.push_back(newNode);
ast_stack.back().push_back(newNode);
pdc=pdc.substr(pdc.find(" ")+1);
}
else
{
newNode->name=pdc;
Node->child.push_back(newNode);
ast_stack.back().push_back(newNode);
break;
}
}
stack_deep++;
}
else
{
input.pop_back();
cout<<endl<<"错误位置:"<<input<<endl;
return 1;//找不到对应产生式
}
}
else
{
input.pop_back();
cout<<endl<<"错误位置:"<<input<<endl;
return 2;//输入串含非法符号
}
}
//情况:Table[S2,"#"]=S2->@
while(find(NT.begin(),NT.end(),Analysis.top())!=NT.end()&&input=="#")
{
pair<string,string>symbol;
symbol=make_pair(Analysis.top(),"#");
if(!Table[symbol].empty())
{
Analysis.pop();
}
else
break;
}
//cout<
if(Analysis.top()=="#"&&input=="#")
return 0;
else
return 3;
}
void parser(string fileName)
{
ifstream input(fileName);
if(!input)
{
cout<<fileName<<" Failed"<<endl;
return;
}
getTable();//求LL(1)分析表
//读取token
char c;
string program="";
int line=1;
cout<<"源程序的token序列为"<<endl;
cout<<line<<" ";
while((c=input.get())!=EOF)
{
cout<<c;
if(c=='\n')
{
cout<<++line<<" ";
program+=" ";
}
else
program+=c;
}
cout<<endl;
//cout<
cout<<"分析结果:";
switch(parsing(program))
{
case 0:
cout<<"语法正确"<<endl;
cout<<endl<<"语法树如下"<<endl;
printTree(ast.root,0);
break;
case 1:
cout<<"无对应产生式"<<endl;
break;
case 2:
cout<<"错误原因:含有非法字符"<<endl;
break;
case 3:
cout<<"语法错误"<<endl;
break;
default:
cout<<"error"<<endl;
}
}
//打印NT和T
void printV()
{
cout<<"非终结符号集合:"<<endl;
for(int i=0; i<NT.size(); i++)
{
cout<<NT[i]<<" ";
}
cout<<endl;
cout<<"终结符号集合:"<<endl;
for(int i=0; i<T.size(); i++)
{
cout<<T[i]<<" ";
}
cout<<endl;
}
//打印FIRST集
void printFIRST()
{
cout<<"FIRST集合为"<<endl;
cout.setf(ios::left);
for(string non_terminal:NT)
{
cout<<setw(20)<<non_terminal;
for(string first:FIRST[non_terminal])
cout<<first<<" ";
cout<<endl;
}
cout<<endl;
}
//打印FOLLOW集
void printFOLLOW()
{
cout<<"FOLLOW集合为"<<endl;
cout.setf(ios::left);
for(string non_terminal:NT)
{
cout<<setw(20)<<non_terminal;
for(string follow:FOLLOW[non_terminal])
cout<<follow<<" ";
cout<<endl;
}
cout<<endl;
}
//打印分析表
void printTable()
{
cout<<"LL(1)分析表:"<<endl;
vector<string>x=T;//含界符的终结符号集合
x.push_back("#");
//输出表格横轴
cout.setf(ios::left);
for (auto it1 = x.begin(); it1 != x.end(); it1++)
{
if (it1==x.begin())
cout<<setw(10)<<" ";
cout<<setw(15)<<*it1;
}
cout<<endl;
for(string A:NT)
{
cout<<setw(10)<<A;
for(string a:x)
{
pair<string,string>symbol;
symbol=make_pair(A,a);
if(!Table[symbol].empty())
cout<<setw(15)<<Table[symbol];
else
cout<<setw(15)<<"----------";
}
cout<<endl;
}
cout<<endl<<"LL(1)分析表构建完成"<<endl<<endl;
}
//打印语法树
void printTree(TreeNode Node,int deep)
{
for(int i=0; i<=deep; i++)
{
cout<<"\t";
}
cout<<Node->name<<endl;
for(int i=0; i<Node->child.size(); i++)
{
printTree(Node->child[i],deep+1);
}
}
//打印产生式
void printP()
{
cout<<"语法的产生式为"<<endl;
for(string left:NT)
{
cout<<left<<"->";
for(auto it=production[left].begin(); it!=production[left].end(); it++)
{
if(it!=production[left].end()-1)
cout<<*it<<"|";
else
cout<<*it<<endl;
}
}
cout<<endl;
}
};
int main()
{
string filename="grammar-input.txt";
Grammar grammar(filename);
grammar.printP();
grammar.leftRecursionRemoval();//去除左递归
grammar.leftFactoring();//提取左公共因子
cout<<"消除左递归和提取左公共因子后,";
grammar.printP();//输出产生式
if(!grammar.judgeLL1())
{
cout<<"该文法不是LL(1)文法"<<endl;
return 0;
}
cout<<endl<<"--------------------------------该文法是LL(1)文法--------------------------------"<<endl<<endl;
grammar.parser("Tokens.txt");
return 0;
}
/*
测试文法(是LL(1)):
Program->Stmt_seq
Stmt_seq->Stmt_seq ; Statement|Statement
Statement->If_stmt|Repeat_stmt|Assign_stmt|Read_stmt|Write_stmt
If_stmt->if Exp then Stmt_seq end|if Exp then Stmt_seq else Stmt_seq end
Repeat_stmt->repeat Stmt_seq until Exp
Assign_stmt->id = Exp
Read_stmt->read id
Write_stmt->write Exp
Exp->Smp_exp Cmp_op Smp_exp|Smp_exp
Cmp_op-><|==
Smp_exp->Smp_exp Add Term|Term
Add->+|-
Term->Term MUL Factor|Factor
MUL->*|/
Factor->( Exp )|digit|id
*/
/*
测试文法(不是LL(1)):
statement->if_stmt|other
if_stmt->if ( E ) statement else_part
else_part->else statement|@
E->0|1
*/
/*
测试token序列:
if digit < id
then id = digit ;
repeat
id = id * id ;
id = id - digit
until id == digit ;
write id
end
*/
测试结果
输入1:
statement->if_stmt|other
if_stmt->if ( E ) statement else_part
else_part->else statement|@
E->0|1
输出1:
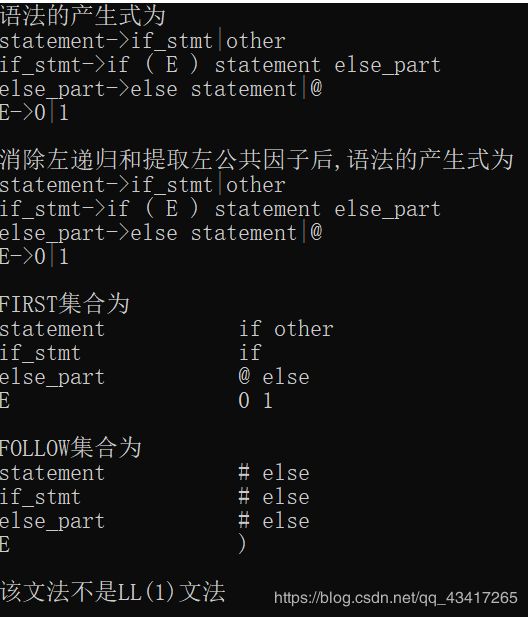
输入2:
Program->Stmt_seq
Stmt_seq->Stmt_seq ; Statement|Statement
Statement->If_stmt|Repeat_stmt|Assign_stmt|Read_stmt|Write_stmt
If_stmt->if Exp then Stmt_seq end|if Exp then Stmt_seq else Stmt_seq end
Repeat_stmt->repeat Stmt_seq until Exp
Assign_stmt->id = Exp
Read_stmt->read id
Write_stmt->write Exp
Exp->Smp_exp Cmp_op Smp_exp|Smp_exp
Cmp_op-><|==
Smp_exp->Smp_exp Add Term|Term
Add->+|-
Term->Term MUL Factor|Factor
MUL->*|/
Factor->( Exp )|digit|id
输出2:

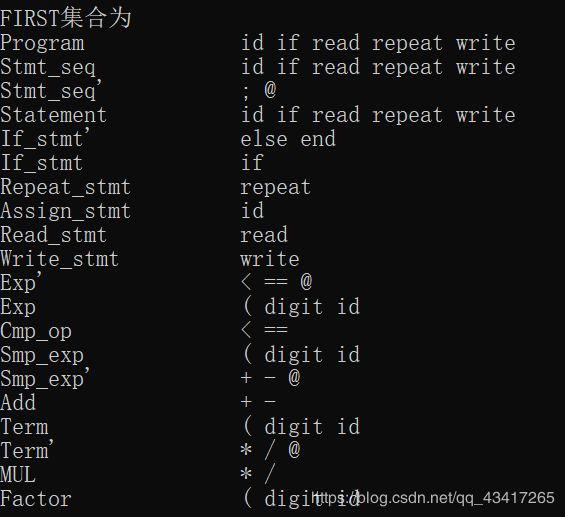
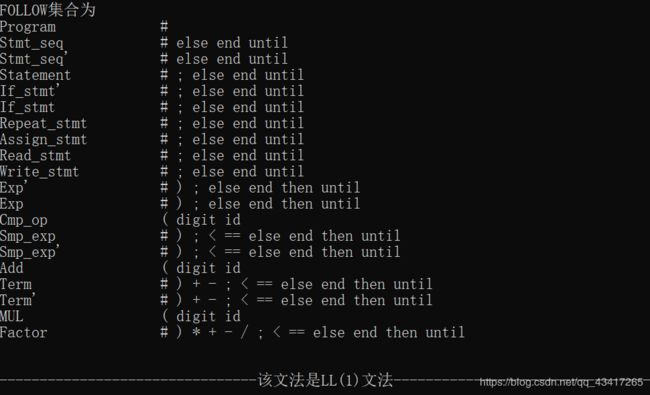


语法树中同一列中的元素属于同一层
其他相关博文
【编译原理】正则表达式转NFA
【编译原理】NFA转DFA(子集构造法)
【编译原理】最小化DFA
【编译原理】LR(0)分析方法(c++实现)
【编译原理】SLR(1)分析方法(c++实现)