Prometheus_Paas
Prometheus_Paas
一、概览
二、架构
2.1 基础架构
2.2 可用性
三、部署
3.1 Prometheus部署
3.2 数据导入导出
3.3 报警配置
3.4 监控升级
四、服务接入
Relabeling
五、监控/告警指标
5.0 监控数据采集周期
5.1 核心组件
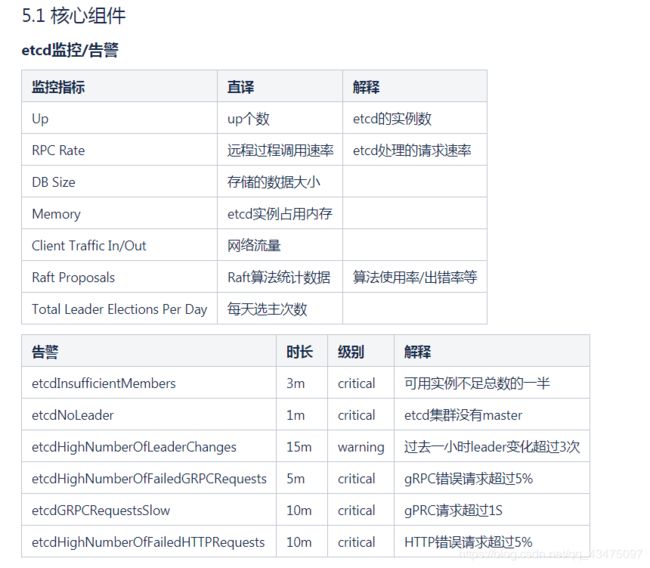
etcd监控/告警
apiserver监控/告警
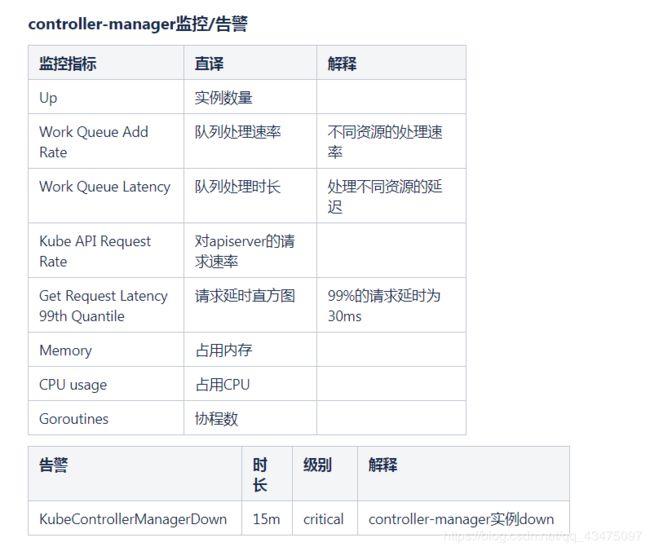
controller-manager监控/告警
scheduler监控/告警
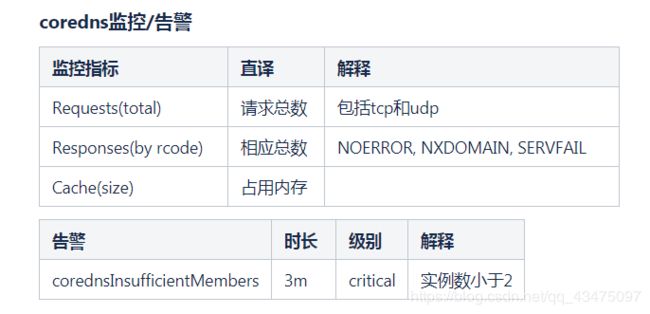
coredns监控/告警
5.2 集群监控告警
5.3 中间件监控
mongodb-replicaset监控
mongosharding监控
kafka监控
5.4 业务监控
六、面板
6.1 面板接入
一、概览
二、架构
2.1 基础架构
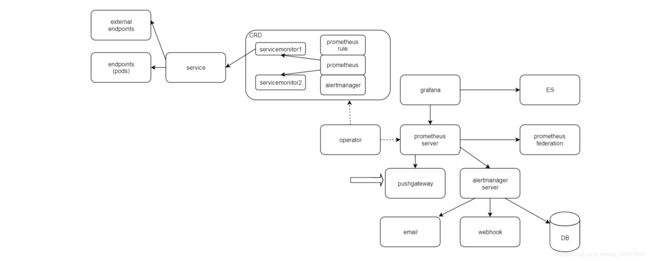
operator: 核心组件,动态加载管理资源和配置;
CRD:kubernetes自定义资源;
servicemonitor: 连接service与Prometheus, 自动把metrics打入prometheus;
service: kubernetes资源;
endpoints:kubernetes资源,与pod对应,可以连接外部IP;
alertmanager/promtheus/rule: CRD;
prometheus server: 核心组件,处理监控核心业务;
grafana: metrics可视化工具,可连接各种数据库,比如prometheus, ES等;
pushgataway: 用于网络单连通场景;
alertmanager server: 核心组件,处理告警核心业务;
webhook: 接收并处理告警的各种程序;
email: 告警通知email服务器;
DB:保存告警数据,用于后续的数据分析处理;
federation: prometheus集联,用于扩展监控规模;
2.2 可用性
单实例的可用性,可通过kubernetes的机制保证。
本地存储
存储路径,存储大小均可配置
支持snapshot
API支持筛选过滤metrics
存储高可用

adaptor:处理数据转换,json到第三方存储支持的数据格式;
第三方存储:支持ES, InfluxDB, Kafka等;
https://prometheus.io/docs/operating/integrations/#remote-endpoints-and-storage
prometheus高可用
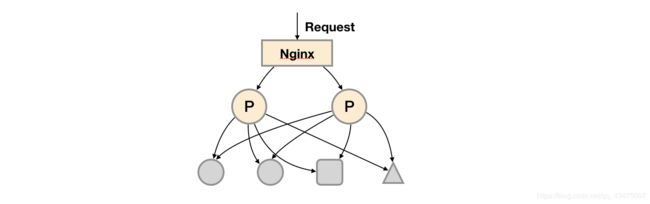
通过nginx负载均衡,但无法保证数据一致性和持久性问题,用于promtheus server不会频繁切换,且保存短周期监控数据的场景;
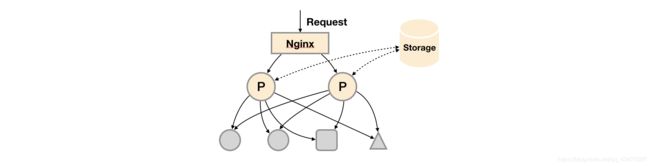
连接外部存储,解决数据一致性和持久性问题;

通过集联,支持大规模/超大规模采集场景;
根据需求和场景自行选择高可用方案。
alertmanager高可用
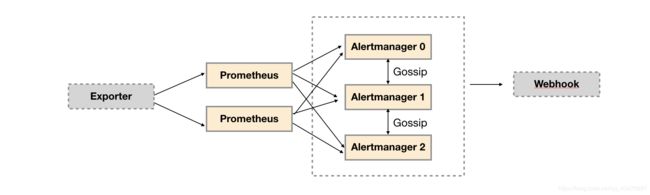
通过gossip协议,保证告警数据一致性;
三、部署
3.1 Prometheus部署
operator功能
声明式创建和管理Prometheus Server实例;
负责声明式的管理监控配置;
负责声明式的管理告警配置;
声明式的创建和管理Alertmanager实例;
简言之,Prometheus Operator能够帮助用户自动化的创建以及管理Prometheus Server以及其相应的配置。
修改监控配置
charts更新
注意:直接修改 资源(比如configmap, deployment)会导致被 operator覆盖
主要配置项


3.2 数据导入导出
数据导出:监控方案#监控方案-数据处理
数据导入:监控 - 单机版
3.3 报警配置
钉钉告警配置:钉钉告警
3.4 监控升级
升级版本步骤
下载最新的官方charts:https://github.com/helm/charts/tree/master/stable/prometheus-operator;
更新所有镜像到私有镜像仓库;
value.yaml的值同步更新到新版本;
定制化dashboard同步更新到新版本;
其他定制化内容(比如alert-rule, webhook)同步更新到新版本;
四、服务接入
服务指k8s上的业务系统,本章介绍业务如何接入监控系统,将监控数据上报到Prometheus
准备部署文件
说明,pod需要提供监控数据获取的http接口,访问uri为/metrics
kind: Service
apiVersion: v1
metadata:
name: example-app
labels:
app: example-app
spec:
selector:
app: example-app
ports:
- name: web
port: 8080
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: example-app
spec:
replicas: 1
template:
metadata:
labels:
app: example-app
spec:
containers:
- name: example-app
image: fabxc/instrumented_app
ports:
- name: web
containerPort: 8080
准备servicemonitor(监控配置)
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: example-app
labels:
prometheus: kube-prometheus # 注意,不能改变,固定
spec:
selector:
matchLabels:
app: example-app # 同service的调度配置
endpoints:
- port: web # 同service的port name
path: "/metrics" #metrics获取路径,默认为/metrics
servicemonitor支持https&高级配置
准备secret
示例,创建一个secret,名字为kube-etcd-client-certs,key为etcd-client-ca.crt,从文件etcd-client.ca.crt获取内容
kubectl -n monitor create secret kube-etcd-client-certs --from-file=etcd-client-ca.crt=etcd-client.ca.crt --from-file=etcd-client.crt=etcd-client.crt --from-file=etcd-client.key=etcd-client.key
更新prometheus配置
secrets:
- kube-etcd-client-certs
证书文件路径
/etc/prometheus/secrets/<secret name>/<key name>
示例配置
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: example-app
labels:
prometheus: kube-prometheus # 注意,不能改变,固定
spec:
selector:
matchLabels:
app: example-app # 同deployment的调度配置
endpoints:
- port: web # 同service里的port name
interval: 30s # 获取数据间隔,默认30s
scrapeTimeout: 10s #超时时间,默认10s
path: "/metrics" #metrics获取路径,默认为/metrics
scheme: https
tlsConfig:
caFile: /etc/prometheus/secrets/kube-etcd-client-certs/etcd-client-ca.crt
certFile: /etc/prometheus/secrets/kube-etcd-client-certs/etcd-client.crt
keyFile: /etc/prometheus/secrets/kube-etcd-client-certs/etcd-client.key
检查
本地绑定host,ip为集群内任意节点的ip,域名为monitor.yitu-inc.com
http://monitor.yitu-inc.com/prometheus/targets
准备报警配置
prometheusrule.yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
app: prometheus-operator # 注意,不能改变,固定
name: demo-rules
spec:
groups:
- name: demo-alive
rules:
- alert: DemoAlert
expr: kube_pod_container_status_running{container="example-app"} == 0 # running状态到pod数量为0
运维平台采集规范
Metrics规范
Relabeling
Prometheus读取service/pod/endpoint的label并映射出来的方法
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app: prometheus-operator-alertmanager
chart: prometheus-operator-5.7.0
heritage: Tiller
prometheus: kube-prometheus
release: prometheus
name: prometheus-prometheus-oper-alertmanager
namespace: monitor
spec:
endpoints:
- path: /alertmanager/metrics
port: web
relabelings:
- action: replace
regex: (.*)
replacement: $1
separator: ;
sourceLabels:
- __meta_kubernetes_service_label_appname
targetLabel: appname
namespaceSelector:
matchNames:
- monitor
selector:
matchLabels:
app: prometheus-operator-alertmanager
release: prometheus
五、监控/告警指标
5.0 监控数据采集周期
总体采集周期:30s
告警规则定期计算:30s
servicemonitor: 可配置,目前都采用默认(总体周期)
5.1 核心组件
etcd监控/告警


5.2 集群监控告警

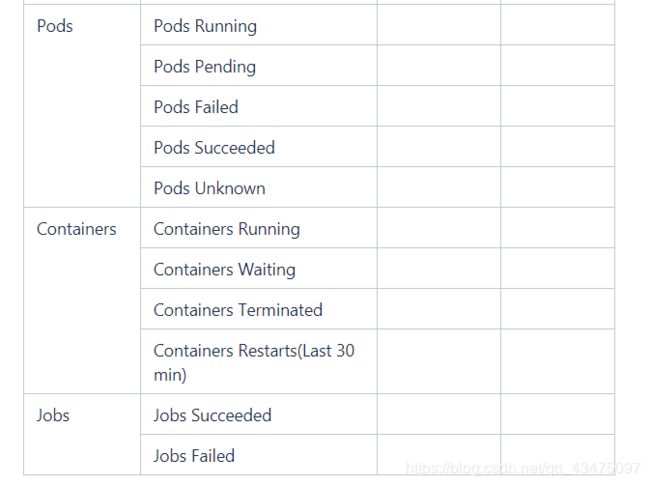
5.3 中间件监控
mongodb-replicaset监控


mongosharding监控



kafka监控
5.4 业务监控
如何配置监控指标
核心组件监控:ingress、tiller、flannel等
缺少文档和含义,其中 tiller不需要了,我们后面会升级 方鹏
六、面板
如何查看、查询监控
基础查询:prometheus web查询
dashboard:grafana如何认证,访问,有哪些基础的dashboard
6.1 面板接入
准备面板yaml
# Generated from 'nodes' from https://raw.githubusercontent.com/coreos/kube-prometheus/master/manifests/grafana-dashboardDefinitions.yaml
# Do not change in-place! In order to change this file first read following link:
# https://github.com/helm/charts/tree/master/stable/prometheus-operator/hack
{{- if .Values.grafana.defaultDashboardsEnabled }}
apiVersion: v1
kind: ConfigMap
metadata:
name: {{ printf "%s-%s" (include "prometheus-operator.fullname" $) "mysql" | trunc 63 | trimSuffix "-" }}
labels:
{{- if $.Values.grafana.sidecar.dashboards.label }}
{{ $.Values.grafana.sidecar.dashboards.label }}: "1"
{{- end }}
app: {{ template "prometheus-operator.name" $ }}-grafana
{{ include "prometheus-operator.labels" $ | indent 4 }}
data:
mysql.json: |-
## 注意空格
{
## 业务面板,json文件放这里
}
{{- end }}
更新面板
helm fetch prometheus-operator --repo http://172.16.160.172:8080
tar zxvf prometheus-operator-5.7.0.tgz
cp test.yaml ~/prometheus-operator/templates/grafana/dashboards
cd ~/prometheus-operator
helm upgrade prometheusoperator .
注意事项
json文件中,每行首空4个字符
json中datasource取值为$datasource
json中"{{“需要转义为”{{{{" json中"}}"需要转义为"}}}}"