python+MobileNetSSD实现视频中的车辆识别
文章目录
- 1.序言
- 2.实现目标
- 3.代码
- 4.各函数的返回值及作用
- 5.测试结果
- 6.存在的问题
- 7.最后
1.序言
本文代码参考来自 一只稚嫩的小金毛
https://blog.csdn.net/qq_39071739/article/details/103728046
特此说明
由于刚刚才学习opencv的DNN模块,对于模型建立和运用的概念不是很熟悉,在这里就这些代码的实现给出解释
2.实现目标
本人的毕业设计涉及到图像追踪和计数,上文中的检测虽然能简单实现车辆检测,但细节调整起来不是太完美,于是想到了图像识别的办法来解决,在网上学写了相关文章后找到了训练好的SSD模型,具体模型下载及参考请看序言链接。
3.代码
import cv2 as cv
count = 0
# 模型路径
model_bin = r"C:\Users\zn\Desktop\ssd\MobileNetSSD_deploy.caffemodel"
config_text = r"C:\Users\zn\Desktop\ssd\MobileNetSSD_deploy.prototxt"
# 类别信息
objName = ["background",
"aeroplane", "bicycle", "bird", "boat",
"bottle", "bus", "car", "cat", "chair",
"cow", "diningtable", "dog", "horse",
"motorbike", "person", "pottedplant",
"sheep", "sofa", "train", "tvmonitor"]
# 加载模型
net = cv.dnn.readNetFromCaffe(config_text, model_bin)
# 读取测试图片
vc = cv.VideoCapture("监控录像.mp4")
while True:
ret,frame = vc.read()
image = frame
h = image.shape[0]
w = image.shape[1]
# 获得所有层名称与索引
layerNames = net.getLayerNames()
lastLayerId = net.getLayerId(layerNames[-1])
lastLayer = net.getLayer(lastLayerId)
print(lastLayer.type)
# 检测
blobImage = cv.dnn.blobFromImage(image, 0.007843, (300, 300), (127.5, 127.5, 127.5), True, False)
net.setInput(blobImage)
cvOut = net.forward()
print(cvOut)
cv.line(frame, (0, 600), (19200, 600), (0, 255, 0), 2, 4)
cv.putText(frame, "Count:" + str(count), (500, 500), cv.FONT_HERSHEY_COMPLEX, 2, (255, 0, 0))
for detection in cvOut[0,0,:,:]:
score = float(detection[2])
objIndex = int(detection[1])
if score > 0.1 and (objName[objIndex] =='car' or objName[objIndex] =='bus'):
left = detection[3]*w
top = detection[4]*h
right = detection[5]*w
bottom = detection[6]*h
# 绘制
cv.rectangle(image, (int(left), int(top)), (int(right), int(bottom)), (255, 0, 0), thickness=2)
cv.putText(image, "score:%.2f, %s"%(score, objName[objIndex]),
(int(left) - 10, int(top) - 5), cv.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2, 8);
if int(bottom) == 600:
count += 1
# 显示
cv.imshow('mobilenet-ssd-demo', image)
k = cv.waitKey(30) & 0xff
if k == 27:
break
# cv.imwrite("D:/Pedestrian.png", image)
cv.waitKey(0)
cv.destroyAllWindows()
4.各函数的返回值及作用
-
cv.dnn.readNetFromCaffe(prototxt, model)
作用:读取SSD模型
返回值:Net object -
cv.dnn.blobFromImage(frame, 0.007843, (w, h), 127.5)
作用:减均值,缩放 ,具体可以参考 https://www.pyimagesearch.com/2017/11/06/deep-learning-opencvs-blobfromimage-works/
返回值:API上的说明为 4-dimensional Mat with NCHW dimensions order,即带着NCHW的4维图层,而NCHW的意义如下:
N 表示这批图像有几张,H 表示图像在竖直方向有多少像素,W 表示水平方向像素数,C 表示通道数 -
net.forward()
作用 :运行网络
返回值:输出结果,在最后一维,第二个开始依次是:标签、置信度、目标位置的4个坐标信息[xmin ymin xmax ymax]
倒数第二维是识别的标签的数量,具体可以参考https://blog.csdn.net/cvnlixiao/article/details/85163611
5.测试结果
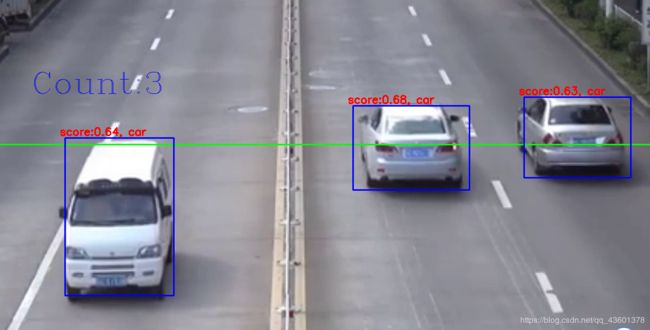
6.存在的问题
- 最主要的问题是虽然实现了车辆识别,但是计数的问题依然没有解决,在上述代码中我自认为这种检测办法没有问题,但事实是车辆有时会在检测线附件突然检测不到,或者碰到检测线了依然没有反应。目前我还没有想出好的办法来解决计数的问题,如果有同学能很好的解决这个问题,跪求您指点指点。
- 有可能是视频清晰度不太好,测试所表现出来的精度不太高,有些车辆必须与摄像头隔的非常近才会被检测到,而且中途会出现检测框一闪一闪的情况,不太稳定,可能这个模型针对的检测范围比较广,下一步我打算学习训练模型。专门针对车辆进行训练,看看精度能否上升。
7.最后
纯新手,发言有不严谨之处或者代码有不正确的地方欢迎指正。上述代码能完成车辆识别但未能很好的去计数,欢迎有经验的朋友给出宝贵的意见,谢谢您的阅读。
如有意见,欢迎与我联系:
1759412770@qq.com
zn1759412770@163.com