Python爬取豆瓣电影 Top 250
一:准备工作
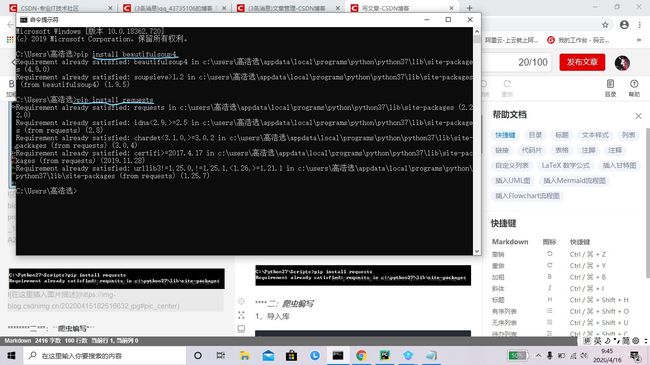
安装第三方库,cmd命令行安装
****二:爬虫编写
1,导入库
import requests
from bs4 import BeautifulSoup
2、解析目标网站
def getHTMLtext(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36'}
try:
response = requests.get(url,headers=headers)
response.raise_for_status()
response.encoding = response.apparent_encoding
data = response.text
soup = BeautifulSoup(data, 'html.parser')
return soup
except:
print('')
3、调用BeautifulSoup库中的find_all()函数寻找标签

#电影名所属标签
def fillUnivList(soup):
tag = soup.find_all('div', class_ = 'hd')
return tag
#导演所属标签
def getFigure(soup):
tag_1 = soup.find_all('div', class_ = 'bd')
return tag_1
4、主函数
def main():
page = 10
start_url = 'https://movie.douban.com/top250'
for i in range(page):#翻页
print('===正在打印第{:}页==='.format(int(i+1)))
url = start_url + '?start=' + str(i*25)
soup = getHTMLtext(url)
tag = fillUnivList(soup)
tag_1 = getFigure(soup)
for each in tag:#对电影名所属标签遍历
text_1 = each.a.span.text#电影名在div标签下的a标签下的span标签,其以文本形式存在;div——>a——>span
for each in tag_1:
text_2 = each.p.text
continue
print('电影名称:{},演员表:{:<}'.format(text_1,text_2))
完整代码如下
import requests
from bs4 import BeautifulSoup
def getHTMLtext(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36'}
try:
response = requests.get(url,headers=headers)
response.raise_for_status()
response.encoding = response.apparent_encoding
data = response.text
soup = BeautifulSoup(data, 'html.parser')
return soup
except:
print('')
def fillUnivList(soup):
tag = soup.find_all('div', class_ = 'hd')
return tag
def getFigure(soup):
tag_1 = soup.find_all('div', class_ = 'bd')
return tag_1
def main():
page = 10
start_url = 'https://movie.douban.com/top250'
for i in range(page):
print('===正在打印第{:}页==='.format(int(i+1)))
url = start_url + '?start=' + str(i*25)
soup = getHTMLtext(url)
tag = fillUnivList(soup)
tag_1 = getFigure(soup)
for each in tag:
text_1 = each.a.span.text
for each in tag_1:
text_2 = each.p.text
continue
print('电影名称:{},演员表:{:<}'.format(text_1,text_2))
main()