Word2Vec词嵌入方法总结
前言
GCN最大的优势是可以处理非欧氏空间结构的数据,可以同时考虑图结构中节点的特征表示和节点间存在逻辑关系(包括有向图和无向图),因此基于其的高包容性可以跟许多方法相结合。其中词嵌入方法可以跟GCN结合起来解决实际应用问题。因此此篇文章在于介绍词嵌入方法(word embedding)
1.什么是词嵌入(word embedding)
词嵌入是NLP工作中标配一部分。原始语料是符号集合,计算机是无法处理符号集合的,因此如何将符集合中的字或者词或者句子甚至更粗粒度映射为向量至关重要。不严谨的讲,词嵌入(Word Embedding)是用一堆向量来表示语言中字或者词的意思。
简单来说,word embedding就是用一个低维的向量表示一个词。在词向量提出之前,人们经常采用one hot encoding对词语进行编码。但由于one hot encoding的维度等于词语的总数,比如阿里的商品one hot encoding的维度就至少是千万量级的。这样的编码方式对于商品来说是极端稀疏的,而深度学习的特点以及工程方面的原因使其不利于稀疏特征向量的处理,因此,如果能把物体编码为一个低维稠密向量再喂给神经网络,自然是一个高效的基本操作,词嵌入应运而生。
总结:词嵌入(Word Embedding)是一种将文本中的词转换成数字向量的方法,为了使用标准机器学习算法来对它们进行分析,就需要把这些被转换成数字的向量以数字形式作为输入。词嵌入过程就是把一个维数为所有词数量的高维空间嵌入到一个维数低得多的连续向量空间中,每个单词或词组被映射为实数域上的向量,词嵌入的结果就生成了词向量。
2.词嵌入的应用
词向量是各种NLP任务中文本向量化的首选技术,如词性标注、命名实体识别、文本分类、文档聚类、情感分析、文档生成、问答系统等。
3.词嵌入方法
3.1One-hot编码
One-hot编码(被称为独热码或独热编码)的词向量。One-hot编码是最基本的向量方法。One-hot编码通过词汇大小的向量表示文本中的词,其中只有对应于该词的项是1而所有其他的项都是零。
One-hot编码的主要问题是不能表示词之间的相似性。在任何给定的语料库中,我们会期望诸如(猫、狗)之类的词具有一些相似性,使用点积计算向量之间的相似性。点积是向量元素乘法的总和。在One-hot编码中,语料库中任何两个词之间的点积总是为零。
3.2信息检索(IR)技术
为了克服One-hot编码的局限性,NLP领域借用了信心检索 (IR)技术,使用文档作为上下文来对文本进行矢量化。比如TF-IDF,LSA和主题建模。
3.3分布式表示
分布式表示的目的是找到一个变换函数,以便将每个词转换为其相关的向量。换句话说,分布是表示就是将词转化成向量,其中向量之间的相似性与词之间的语义相似性相关。
分布式假说。上下文中相似的词其语义也相似,这样一来,我们可以把信息分布式存储在向量的各个维度中,这种分布式表示方法具有紧密低维、句法和语义信息容易获取的特点。
基于分布式假说,根据建模不同,大体可以分为三类:基于矩阵分布表示,基于聚类的分布表示和基于神经网络的分布表示。他们的核心思想由两部分组成:1.选择一种方法描述该词的下上文;2.选择一种模式刻画某个词(“目标词”)与其上下文的关系。
(a)基于矩阵的分布表示
基于矩阵的分布表示主要是构建“词-上下文”矩阵,通过某种技术从该矩阵中获取词的分布表示,矩阵的行表示打词,列表示上下文,每个元素表示某个词和上下文共现的次数。这样矩阵的一行就描述了该词的上下文分布情况。
常见的上下文有:1.文档:即“词-文档“矩阵;2.上下文的每个词:即“词-词”矩阵;3.n-元词组,即“词-n-元组”矩阵。矩阵中每个元素为词和上下文共现次数,通常会采用TF-IDF、取对数等方法进行加权平滑。另外,矩阵的维度教高并且非常稀疏的话,可以通过SVD等手段进行姜维,变为较低稠密矩阵。
(b)基于聚类的分布表示
通过聚类手段构建词语上下文之间的关系,代表模型为布朗聚类(Brown Clustering)
©基于神经网络的分布表示
- 基于神经网络语言模型
- 循环神经网络语言模型
- C&W模型
- 著名的Word2Vec‘’
(1). skip-gram
(2). CBOW(continuous Bags-of-Words)
4.词嵌入算法Word2Vec
4.1介绍
根据已有的语料库将他们的one-hot向量作为word2vec的输入,通过word2vec训练低维词向量(word embedding),Wordk2Vec目前有两种训练模型(CBOW和Skip-gram),两种加速算法(Negative Sample与Hierarchical Softmax)。word2vec整个过程中可以分为两个部分,其一如何将corpus的one-hot向量(模型的输入)转换成低维词向量(模型的中间产物,更具体来说是输入权重矩阵),其二根据低维词向量根据两种加速算法输出预测词概率
根据介绍中Word2Vec的两种训练模型和两种加速算法,可知Word2Vec共存在2*2四种模式
4.2Word2Vec的两种训练模型(CBOW和Skip-gram)
CBOW模型根据中心词W(t)周围的词来预测中心词
Skip-gram模型则根据**中心词W(t)**来预测周围词
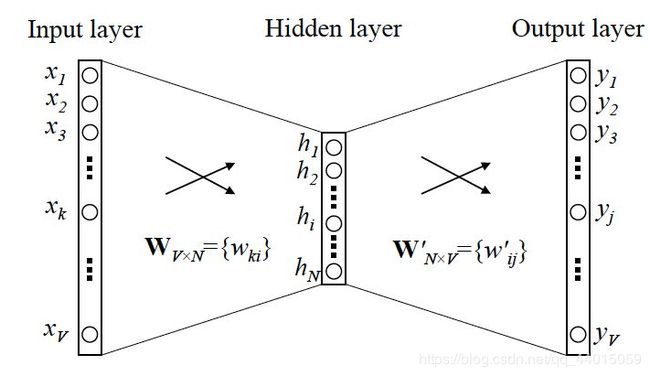
4.2.1CBOW模型

一般形式结构如下图所示

- 输入层:上下文单词的onehot. {假设单词向量空间dim为V,上下文单词个数为C}
- 所有onehot分别乘以共享的输入权重矩阵W. {V*N矩阵,N为自己设定的数,初始化权重矩阵W}
- 所得的向量 {因为是onehot所以为向量} 相加求平均作为隐层向量, size为1*N.
- 乘以输出权重矩阵W’ {N*V}
- 得到向量 {1*V} 激活函数处理得到V-dim概率分布 {PS: 因为是onehot嘛,其中的每一维斗代表着一个单词},概率最大的index所指示的单词为预测出的中间词(target word)
- 与true label的onehot做比较,误差越小越好
所以,需要定义loss function(一般为交叉熵代价函数),采用梯度下降算法更新W和W’。训练完毕后,输入层的每个单词与矩阵W相乘得到的向量的就是我们想要的词向量(word embedding),这个矩阵(所有单词的word embedding)也叫做look up table(其实聪明的你已经看出来了,其实这个look up table就是矩阵W自身),也就是说,任何一个单词的onehot乘以这个矩阵都将得到自己的词向量。有了look up table就可以免去训练过程直接查表得到单词的词向量了。
4.2.2CBOW模型流程举例
注意:
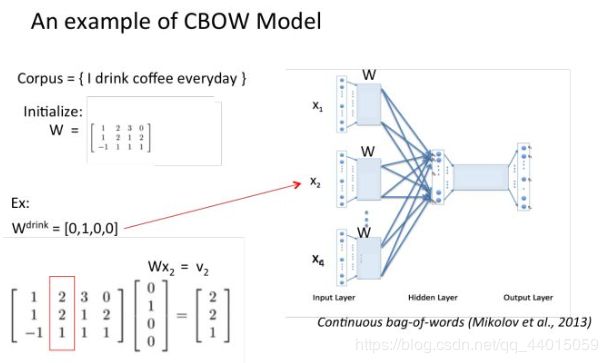
所有onehot分别乘以共享的输入权重矩阵W. {V*N矩阵,N为自己设定的数,初始化权重矩阵W}
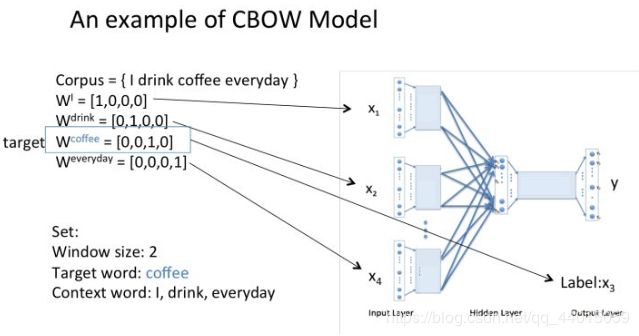
假设我们现在的Corpus是这一个简单的只有四个单词的document:
{I drink coffee everyday}
我们选coffee作为中心词,window size设为2
也就是说,我们要根据单词"I","drink"和"everyday"来预测一个单词,并且我们希望这个单词是coffee。
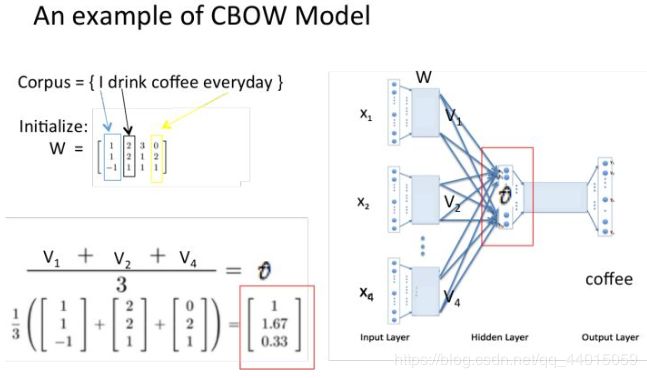


假设我们此时得到的概率分布已经达到了设定的迭代次数,那么现在我们训练出来的look up table应该为矩阵W。即,任何一个单词的one-hot表示乘以这个矩阵都将得到自己的word embedding。
之后的预测分类过程忽略,该过程在Skip-gram模型中说明
4.2.3Skip-gram模型

一般形式的结构如下图所示

4.2.4Skip-gram模型举例
Skip-gram模型类似于CBOW分为两步
- 根据初始化的嵌入矩阵生成词的低维(词向量)表示
- 之后的流程就是根据词的低维表示(词向量)训练系数矩阵输出预测的输出层向量。之后再经过一个softmax分类得到对应每个词的概率
那么为了产生模型的正样本,我们选一个长度为 2 c + 1 2c+1 2c+1(目标词前后各选c个词)的滑动窗口,从句子左边滑倒右边,每滑一次,窗口中的词就形成了我们的一个正样本。
有了训练样本之后我们就可以着手定义优化目标了,既然每个词 w t w_{t} wt都决定了相邻词 w t + j w_{t+j} wt+j基于极大似然,我们希望所有样本的条件
概率 P ( w t + j ∣ w t ) P(w_{t+j}|w_{t}) P(wt+j∣wt)之积最大,这里我们使用log probability。我们的目标函数有了:

接下来的问题是怎么定义 P ( w t + j ∣ w t ) P(w_{t+j}|w_{t}) P(wt+j∣wt),作为一个多分类问题,最简单最直接的方法当然是直接用Softmax函数,公式如下图所示:

4.2.5总结
两种模型的特点:
Skip-gram模型不利于大规模数据模型的训练,适用于较小规模的数据
CBOW模型适用于较大规模的数据
4.3Word2vec 的两种训练技巧(hierarchical softmax 和 negative sampling )
4.3.1分层softmax(hierarchical softmax)

4.3.2负采样(negative sampling)
负采样的具体步骤如下:
- 算法思想:在负采样中我们做的不再是Softmax而是一个二分类问题。给定两个词,其中一个词做Content判断另一个词是不是target,如果是则输出1,如果不是则输出0。
- 首要任务还是如何构造训练集,训练集同样取自文本,先找到一组正取样,再选取n组负取样,将这n+1组数据作为输入训练神经网络,如下图所示:

第一行从文本中选取了一个正取样,Content是orange这个单词,Target是juice这个单词。对于orange我们同时需要取n个负取样,分别是后面的四组并标记为0,在负取样中Target是从字典中随机选取的。
此外还需要注意n的选取,在论文中指出,如果在小数据集上nnn选取5−20比较好,如果数据集规模变大,n的取值随之减小,在大数据集上n取2−5 - 下面我们看看如何建立这个监督学习的模型(logistic回归模型),首先定义输出:
P ( y = 1 ∣ c , t ) = σ ( θ t T e c ) P(y=1|c,t)=\sigma (\theta _{t}^{T}e_{c}) P(y=1∣c,t)=σ(θtTec)和之前Softmax一样 θ t \theta _{t} θt是一个属于TargetTargetTarget的参数需要训练, e c e_{c} ec是词向量来自嵌入矩阵。 - 最后看一下模型,如下图:
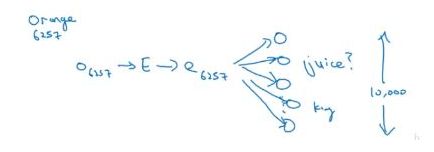 前面的过程和前一节是一样的,我们主要关注的是最后一步,词向量和字典中的每一个词都会进行一次二分类,来判断这个词是否是Content的Target。这样做的好处就是将一个ValueSize的多分类转化成了ValueSize个二分类问题,大大减少了计算提高了效率。此外我们每次迭代只需要更新k个负样本和 1个正样本涉及到的单元也就是k+1个单元。
前面的过程和前一节是一样的,我们主要关注的是最后一步,词向量和字典中的每一个词都会进行一次二分类,来判断这个词是否是Content的Target。这样做的好处就是将一个ValueSize的多分类转化成了ValueSize个二分类问题,大大减少了计算提高了效率。此外我们每次迭代只需要更新k个负样本和 1个正样本涉及到的单元也就是k+1个单元。

5.后续词向量模型
这里主要横向比较一下word2vec,ELMo,BERT这三个模型,着眼在模型亮点与差别处。
传统意义上来讲,词向量模型是一个工具,可以把真实世界抽象存在的文字转换成可以进行数学公式操作的向量,而对这些向量的操作,才是NLP真正要做的任务。因而某种意义上,NLP任务分成两部分,预训练产生词向量,对词向量操作(下游具体NLP任务)。
从word2vec到ELMo到BERT,做的其实主要是把下游具体NLP任务的活逐渐移到预训练产生词向量上。下面是一个大体概括,具体解释后面会写到。。
word2vec——>ELMo:
结果:上下文无关的static向量变成上下文相关的dynamic向量,比如苹果在不同语境vector不同。
操作:encoder操作转移到预训练产生词向量过程实现。
ELMo——>BERT:
结果:训练出的word-level向量变成sentence-level的向量,下游具体NLP任务调用更方便,修正了ELMo模型的潜在问题,。
操作:使用句子级负采样获得句子表示/句对关系,Transformer模型代替LSTM提升表达和时间上的效率,masked LM解决“自己看到自己”的问题。