基于卷积神经网络的多目标图像检测研究(一)
摘 要
目标检测任务简单来说是在图片或视频中指出多个特定目标并以方框形式给出这些物体在图片中的位置和大小。它与我们的生活密切相关,它被广泛应用于安全识别、无人驾驶、医疗诊断、图像检索等领域,并且未来将愈发重要。因此目标检测也是近年来机器学习、图像处理领域的热门研究内容。目前来说,深度学习发展迅速,在目标检测方面涌现出了很多优秀的算法。
到现在为止,已有的基于深度学习的目标检测与识别算法大致可以分为以下三大类:
① 基于区域建议的目标检测与识别算法,如R-CNN, Fast-R-CNN, Faster-R-CNN;
② 基于回归的目标检测与识别算法,如YOLO, SSD;
③ 基于搜索的目标检测与识别算法,如基于视觉注意的AttentionNet,基于强化学习的算法。
这些新的算法有很大的普适性,但是由于具体使用过程中的复杂性,出现的目标大小、清晰度等问题,使得目标检测的准确性面临考验,这也是目标检测算法领域需要解决和攻克的问题。
本文对深度卷积神经网络进行了初步的原理研究和探索,首先本文对公开数据集VOC2007进行了扩充,通过拍摄照片和模型训练的途径,对生活常见目标人、车、椅子和杯子这四类物体目标进行增强。之后对于流行深度学习框架进行简单测评,得出了TensorFlow综合表现良好的结论。
本文采用VGG16作为Faster RCNN的基础特征提取网络,在深度学习框架Caffe下进行网络训练,微调超参数类型和数值,并介绍了在ImageNet上预训练模型的流程。最后得出本文所训练的Faster RCNN模型在日常生活物体检测中有较为准确的识别率和较高的识别速度的结论。
关键词:Faster-R-CNN;卷积神经网络;多目标检测;深度学习
Abstract
The target detection task is simply to point out a plurality of specific objects in a picture or video and give the position and size of the objects in the picture in a block form. It is closely related to our lives, and it is widely used in the fields of safety identification, driverless, medical diagnosis, image retrieval and the like, and will become more and more important in the future. Therefore, the target detection is also a popular research content in the field of machine learning and image processing in recent years. At present, the depth study has developed rapidly, and many excellent algorithms have emerged in the aspect of target detection.
By now, the existing object detection and recognition algorithm based on depth learning can be roughly divided into the following three main categories:
(1) Target detection and recognition algorithms based on regional recommendations, such as R-CNN, Fast-R-CNN, Faster-R-CNN;
(2) Target detection and recognition algorithm based on regression, such as YOLO, SSD;
(3)The target detection and recognition algorithm based on the search, such as the visual attention-based AttentionNet, is based on the enhanced learning algorithm.
These new algorithms are very universal, but because of the complexity of the specific use process, the size and clarity of the target, the accuracy of target detection is tested. This is also the problem that needs to be solved and solved in the field of target detection algorithm.
In this paper, the principle of deep convolution neural network is studied and explored. Firstly, the open dataset VOC2007 is extended, and the common target people and cars in life are trained by taking photos and models. Four types of objects, chairs and cups, are enhanced. After that, a simple evaluation of the popular depth learning framework is carried out, and the conclusion is drawn that the comprehensive performance of TensorFlow is good.
In this paper, VGG16 is used as the basic feature extraction network of Faster RCNN, and the network training is carried out under the deep learning framework Caffe, and the type and value of superparameters are fine-tuned, and the flow chart of pre-training model on ImageNet is introduced. Finally, it is concluded that the Faster RCNN model trained in this paper has a more accurate recognition rate and a higher recognition speed in the detection of daily life objects.
Key Words:Faster-R-CNN; convolution neural network; multi-target detection; deep learning
第1章 绪论
1.1 研究背景及研究意义
很久以来,视觉信息都是人这个本体与外部环境交流信息最重要也是最不可或缺的部分。近年来人工智能和机器学习的发展迅速,普遍对于目标识别、检测的要求在迅速放大,而此时传统的机器学习算法已经在性能上无法达到人们的需求,伴随着卷积神经网络等深度学习算法的优良表现,越来越多的学者和科研人员开始对卷积神经网络进行研究和实验,卷积神经网络的识别效果甚至在某些领域都超过了人类的识别能力。
目标检测的任务是找出图像中所有感兴趣的目标(物体),并确定它们的位置和大小,是机器视觉领域的核心问题之一。由于各类物体有不同的外观,形状,姿态,加上成像时的光照条件不同,遮挡等因素的干扰,目标检测一直是机器领域最有挑战性的问题。人在处理图片或者动态视频时,会先锁定看到图像中的物体,找出它的位置,然后根据目标的特征,判断相应类别,然后对于特定物体目标进一步处理,最后再根据得到的信息来调整行动。
在人处理信息这个流程中:(1)往往由于个体的差异和自身当时心理以及生理上的影响,对于相同目标检测有一定的误差和不准确性;(2)由于个体的精力和兴趣差别,往往会造成信息采集的缺失;(3)人本身生理的缺陷,视野局限于双眼可视范围内。
而机器通过多种图像采集器,计算机处理和数据算法处理,可以解决上述中人在处理图片目标信息时的不足,在不久的将来,以优秀的深度学习算法为代表的机器学习会在各个领域中代替人类处理图像信息并且表现的更加完美。
传统手工提取特征技术在进行目标检测时存在以下问题:(1)目前不存在一种算法可以对图像中所有的目标类型进行检测;(2)传统算法较容易被外界因素干扰。
伴随科技的进步和发展,现代数据存储成本下降和计算机性能的几何倍提升,更加使得人工智能,机器学习近年来的突飞猛进。在这样的条件下,研究者们突破传统的手工设定,开始使用深度学习来对图像中的目标进行分割、识别。
在所有的深度学习模型中,卷积神经网络是最有应用潜力和发展空间的一种。尽管未来的模型能够在检测速度上有所提升,但是几乎没有模型的表现能显著超越Faster R-CNN。总的来说,Faster R-CNN也许不是目标检测最简单,最快的方法,但是它的表现还是自目前最佳的。例如,Tensorflow应用Inception ResNet打造的Faster R-CNN就是他们速度最慢,但却最精准的模型。相较于传统的图像处理,深度学习在给出了大量的带有标注划分的数据集训练后,不需要人工的选择特征,它在网络训练后可以从图像中学习到由标注带来的特征。由此可见,基于卷积神经网络的多目标检测模型必然是未来研究和发展的热门对象。
1.2 多目标图像检测的定义

目标检测的任务是找出图像中所有感兴趣的目标(物体),确定它们的位置和大小,是机器视觉领域的核心问题之一。计算机视觉中关于图像识别有四大类别的任务:
1)分类;2)定位:3)检测;4)分割。除了图像分类之外,目标检测要解决的核心问题是:目标可能出现在图像的任何位置、目标有各种不同的大小、目标可能有各种不同的形状。目标检测的流程是:图像或者视觉信息等被视觉传感器采集、整理,转化为书记矩阵储存在计算机中,作为数据输入到目标检测模型中,通过识别得到原始图像,输出标记后的目标本体、目标位置和目标类别。最后输出其所属类别,进行展示输出或者是进行细致优化处理。
对于整个目标检测模型来说最重要的两点就是准确性和检测速度。不同于人类,计算机在处理、理解图片时,不能根据纹理、外形等特征进行快速准确的判断。因为图片或视频等信息在二进制中是以0—255的数字存储在不同的颜色通道中的,想要让计算机进行识别,必须要通过算法,而不同的算法不能完全的覆盖所有的物体,很容易因为漏掉特征提取区域而出现遗漏,失误的现象。
所以,本文的研究目的就是初步的探索和讨论在多目标图像检测和识别过程中,通过深度学习和目标检测结合,能进行快速而且准确的图像多目标识别,判断和分类。
1.3 国内外研究现状
在目前计算机硬件和各种算法飞速发展的时代背景下,目标检测与深度学习的结合,使得多目标图像检测也得以迅速发展。本小节从深度学习和目标检测两个角度对国内外研究现状进行分析、总结。
1.3.1 目标检测研究现状
国内外的科研人员和实验室在目标检测与识别的研究过程中仍然面临很多的困难。真实世界的信息在转化为二进制信息的过程中,信息会在一定程度上或多或少的有所丢失和畸变,并且待测目标的运动,遮挡和光照还有真实场景中对于实时识别准确性的要求都是需要面对的方面。
传统的目标检测算法分为三个阶段,包括有生成目标建议框,提取每个建议框中的特征,最后根据特征进行分类。这三个阶段的具体过程:
1)生成目标建议框。在向计算机输入一张原始图像后,它只会识别每一个像素点,想要用方框框出目标的位置及大小,最先想到的方法就是进行穷举建议框,就是用滑动窗口扫描整个图像,通过缩放来进行多尺度滑窗。这种方法已经落伍被淘汰,因为它的计算量很大,效率极低,根本无法适用于如今要求的快速识别领域。
2)提取每个建议框中的特征。在传统的检测方法中,常见的HOG算法对物体边缘适用直方图统计来进行编码,有较好的表达能力。但是传统特征设计需要人工指定,达不到可靠性的要求。
3)分类器的设计,传统的分类器在机器学习领域非常多。
然而传统的算法在预测精度和速度上都很不理想,在图像处理领域陷入困难的时候,随着深度学习算法在计算机识别领域的迅速发展,传统算法已经逐渐退出历史的舞台。
1.3.2 深度学习研究现状
如今,人工智能已经成为一个非常火热的领域,这个领域的几何倍速度发展也使得人们希望可以借助人工智能来快速准确地自动处理一些主观的,非常规的失误,如识别、处理图像等。早期的研究项目有一些基于数据库的方法,这种方法的核心主要是利用数据库的量来近似于穷举所有可能的方式来将所有规则进行存储,然后设计相对应的指令来使得计算机能自主的理解,计算。但因为缺乏可以精确,快速地描述事物的算法规则,所以这个方法也是以失败告终。
近代的研究人员针对这些问题提出了改进的方案。这个方案是基于人类大脑思考问题时的层次来设计的,它让计算机从大量的经验中学习,并自主构架一个层次化的结构来拟合事物,通过各个层次之间的简单关联来定义事物。这就是最初的“深度学习”。
自从深度学习出现后,就有越来越多的个体和研究团体加入到这个领域。近几年来关于深度学习的著作和应用算法更是越来越多的出来,被广泛地应用于各个领域中。目前国际上以PASCAL视觉目标类VOC识别挑战赛作为目标检测领域的最高水准竞赛。PASCAL挑战赛由英国的牛津大学和利兹大学,瑞士苏黎世大学和微软剑桥研究院于2005年联合发起,其人要目的是识别真实场景中的一些识别的物体。该挑战赛在一定程度上极大的推动了计算机视觉研究领域的发展。世界上许多深度学习领先的团队或机构都派出了队伍参赛,其中包括有Google、百度、微软、Facebook等知名企业和实验室,并在目标检测领域取得了先进的研究成果和近战。在2012年Krizhevsky A等人在竞赛中利用深度卷积神经网络将ImageNet中1000类物体的分类识别错误率降到了37.5%和17.0%。
但是随着国内近年来在该领域的大力发展,我国在深度卷积神经网络上的研究也迅速发展,可以从2016年中国团队包揽了该比赛全部项目的冠军窥一二。虽然身为后起之秀,但是发展势头越来越盛。
自从深度神经网络算法首次在ImageNet数据集上大放异彩后,物体检测领域开始逐渐利用深度学习来做研究。随后各种结构的深度模型被提出,数据集的识别准确率被一再刷新。最早的R-CNN(Region-based CNN)首次使用深度模型提取图像特征,以49.6%的准确率开创了检测算法的新时代。[6]R-CNN的工作包含有三个步骤:1)借助一个可以生成大约2000个region proposal的选择性搜索算法,来获取可能出现的目标。2)在每个region proposal上运行一个卷积神经网络(CNN)。3)将每个CNN的输出都输入进一个支持向量机,以对上述区域进行分类,还有一个线性回归器,以收缩目标周围的边界框。换句话说,首先是给出建议区域,然后从中提取出特征,然后再根据这些特征来对这些区域进行分类。本质而言,R-CNN将目标检测转化为了图像分类的问题。虽然R-CNN模型很直观,但是它的速度很慢。
而后出现的Fast R-CNN在很多方面与R-CNN类似,它在R-CNN的基础上 加上了两项主要的增强手段,使得其检测速度较R-CNN有所提高:1)在推荐区域之前,先对图像执行特征提取工作,通过这种方法,后面只用对整个图像使用一个CNN(之前的R-CNN网络需要在2000个重叠的区域上分别运行2000个CNN)。2)将支持向量机替换成了一个softmax层,这种变化并没有创建新的模型,而是将神经网络进行了扩展以用于预测工作。
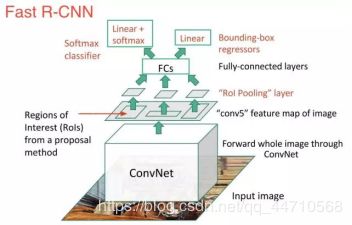
如图1.2所示,现在我们基于网络最后的特征图(而非原始图像)创建了region proposals。因此,我们对整个图像只用训练一个CNN就可以了。
此外,在使用了一个softmax层来直接输出类(class)的概率,而不是像之前一样训练很多不同的支持向量机对每个目标类进行分类。现在,只用训练一个神经网络,而之前我们需要训练一个神经网络以及很多的支持向量机。
但是Fast R-CNN的识别速度仍然达不到实时的要求,于是Faster R-CNN应运而生,它的主要创新是用一个快速神经网络代替了之前慢速的选择搜索算法。换句话说,就是直接利用了RPN(Region Proposal Networks)网络来生成目标候选框。RPN 的工作原理是:
在最后卷积得到的特征图上,使用一个 3x3 的窗口在特征图上滑动,然后将其映射到一个更低的维度上(如 256 维),
在每个滑动窗口的位置上,RPN 都可以基于 k 个固定比例的 anchor box(默认的边界框)生成多个可能的区域。
每个 region proposal 都由两部分组成:a)该区域的 objectness 分数。b)4 个表征该区域边界框的坐标。
换句话说,我们会观察我们最后特征图上的每个位置,然后关注围绕它的 k 个不同的 anchor box:一个高的框、一个宽的框、一个大的框等等。对于每个这些框,不管我们是否认为它包含一个目标,以及不管这个框里的坐标是什么,我们都会进行输出。在region proposal的基础上添加池化层,全连接层和softmax分类层和边界框回归器,就是Faster R-CNN模型。
总体而言,Faster R-CNN 较 Fast R-CNN 在速度上有了大幅提升,而且其精确性也达到了最尖端的水平。值得一提的是,尽管未来的模型能够在检测速度上有所提升,但是几乎没有模型的表现能显著超越 Faster R-CNN。换句话说,Faster R-CNN 也许不是目标检测最简单、最快的方法,但是其表现还是目前最佳的。例如,Tensorflow 应用 Inception ResNet 打造的 Faster R-CNN 就是他们速度最慢,但却最精准的模型。
也许 Faster R-CNN 看起来可能会非常复杂,但是它的核心设计还是与最初的 R-CNN 一致:先假设对象区域,然后对其进行分类。目前,这是很多目标检测模型使用的主要思路。
在2015年,YOLO算法被提出。YOLO算法的主要创新点在于放弃了原始的区域选择过程,将输入图片信息按一定比例划分出正方的方格,然后对每个方格产生大小不同的边界框,并进行回归处理。这样做的好处是极大的加速了整个检测过程,在高端GPU上甚至可以达到45fps的处理速度,但是缺点是对于形状小的物体或者是多个物体叠加在一起的情况处理能力较弱。
作为目前主流的算法,Faster R-CNN是一个很好的研究领域,未来在与目标检测领域结合的过程中,必然能诞生出更好更快的模型。因此,本文采用深度卷积神经网络的相关算法来完成对多目标图像的检测。
本文由作者原创,转载或引用请得到博主同意。