前言:
此文为大家入门爬虫来做一次简单的例子,让大家更直观的来了解爬虫。
本次我们利用 Requests 和正则表达式来抓取豆瓣电影的相关内容。
一、本次目标:
我们要提取出豆瓣电影-正在上映电影名称、评分、图片的信息,提取的站点 URL 为:https://movie.douban.com/cinema/nowplaying/beijing/,提取的结果我们以文件形式保存下来。
二、准备工作
确保已经正确安装 Requests 库,无论是 Windows、Linux 还是 Mac,都可以通过 Pip 这个包管理工具来安装。
安装命令:pip3 install requests
正则表达式相关教程见:正则表达式总结版、正则表达式
三、抓取分析
抓取的目标站点为:https://movie.douban.com/cinema/nowplaying/beijing/,打开之后便可以查看到正在上映的电影信息,如图所示:
四、抓取页面源代码
接下来我们用代码实现抓取页面源代码过程,首先实现一个 get_page() 方法,传入 url 参数,然后将抓取的页面结果返回,然后再实现一个 main() 方法调用一下,初步代码实现如下:
def get_page(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def main():
url = "https://movie.douban.com/cinema/nowplaying/beijing/"
html = get_page(url)
五、正则提取电影信息
接下来我们回到网页看一下页面的真实源码,在开发者工具中 Network 监听,然后查看一下源代码,如图所示: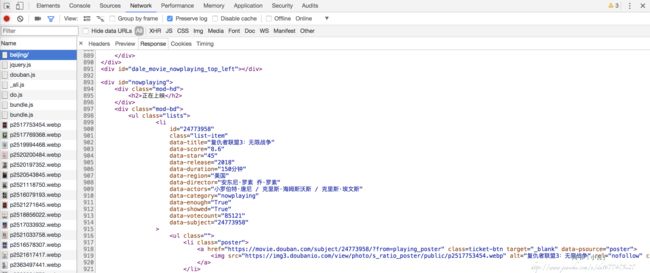
注意这里不要在 Elements 选项卡直接查看源码,此处的源码可能经过 JavaScript 的操作而和原始请求的不同,我们需要从 Network 选项卡部分查看原始请求得到的源码。

使用相同判断方法来提取data-score属性的信息,正则表达式写为:
随后我们需要提取电影的图片,可以看到在a节点内部有img节点,该节点的src属性是图片的链接,所以在这里提取img节点的src属性,所以正则可以改写如下:
.*? 这样我们一个正则表达式可以匹配一个电影的结果,里面匹配了3个信息,接下来我们通过调用 findall() 方法提取出所有的内容,实现一个 parse_page() 方法如下:
def parse_page(html):
pattern = re.compile('.*? 这样我们就可以成功提取出电影的图片、标题、评分内容了,并把它赋值为一个个的字典,形成结构化数据,运行结果如下:
{'image': 'https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2517753454.jpg', 'title': '复仇者联盟3:无限战争', 'score': '8.6'}
{'image': 'https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2517769368.jpg', 'title': '小公主艾薇拉与神秘王国', 'score': '0'}
{'image': 'https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2519994468.jpg', 'title': '后来的我们', 'score': '5.8'}
{'image': 'https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2520200484.jpg', 'title': '我是你妈', 'score': '5.1'}
{'image': 'https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2520197352.jpg', 'title': '战犬瑞克斯', 'score': '7.0'}
到此为止我们就成功提取了此页的电影信息。
六、写入文件
随后我们将提取的结果写入文件,在这里直接写入到一个文本文件中,通过 json 库的 dumps() 方法实现字典的序列化,并指定 ensure_ascii 参数为 False,这样可以保证输出的结果是中文形式而不是 Unicode 编码,代码实现如下:
def write_to_file(content):
with open('xiaoxi.txt', 'a', encoding='utf-8')as f:
print(type(json.dumps(content)))
f.write(json.dumps(content,ensure_ascii=False))
通过调用 write_to_json() 方法即可实现将字典写入到文本文件的过程,此处的 content 参数就是一部电影的提取结果,是一个字典。
七、整合代码
到此为止,我们 的爬虫就全部完成了,再稍微整理一下,完整的代码如下:源码见git
# -*- coding: utf-8 -*-
# @Time : 2018/5/12 上午11:37
# @Author : xiaoxi
# @File : test.py
import json
import re
import requests
from requests import RequestException
def get_page(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def parse_page(html):
pattern = re.compile('.*? 运行之后,可以看到电影信息也已全部保存到了文本文件中,大功告成!
八、运行结果
最后我们运行一下代码,类似的输出结果如下:
{'image': 'https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2517753454.jpg', 'title': '复仇者联盟3:无限战争', 'score': '8.6'}
{'image': 'https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2517769368.jpg', 'title': '小公主艾薇拉与神秘王国', 'score': '0'}
...
{'image': 'https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2519994468.jpg', 'title': '后来的我们', 'score': '5.8'}
中间的部分输出结果已省略,可以看到这样就成功把电影信息爬取下来了。

以上~~你对爬虫有进一步的了解了么? 请继续关注我的爬虫系列~~~