论文巧妙地基于one-stage目标检测算法提出实时实例分割算法YOLACT,整体的架构设计十分轻量,在速度和效果上面达到很好的trade-off。
来源:【晓飞的算法工程笔记】 公众号
论文: YOLACT: Real-time Instance Segmentation

- 论文地址:https://arxiv.org/abs/1904.02689
- 论文代码:https://github.com/dbolya/yolact
Introduction
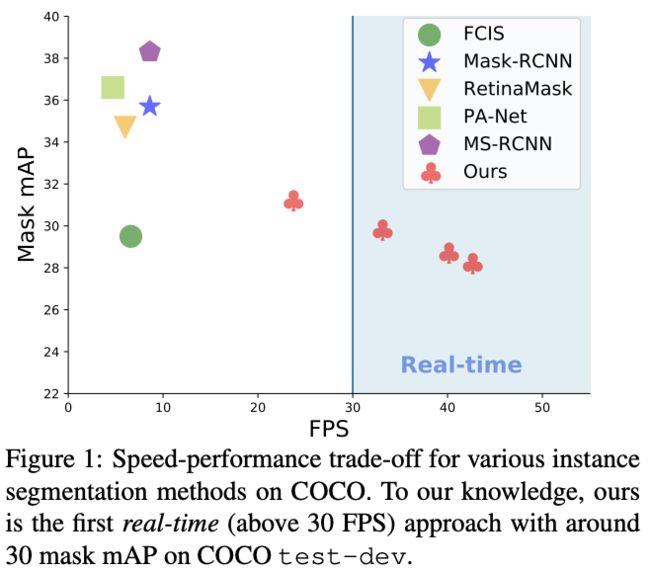
目前的实例分割方法虽然效果都有很大的提升,但是均缺乏实时性,为此论文的提出了首个实时($>30fps$)实例分割算法YOLACT,论文的主要贡献如下:
- 基于one-stage目标检测算法,提出实时实例分割算法YOLACT,整体的架构设计十分轻量,在速度和效果上面达到很好的trade-off。
- 提出加速版NMS算法Fast NMS,有12ms加速
YOLACT
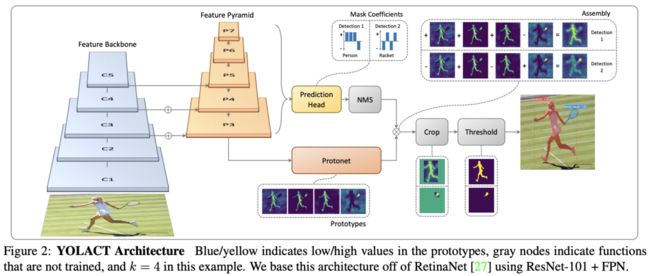
YOLACT的主要想法是直接在one-stage目标检测算法中加入Mask分支,而不添加任何的RoI池化的操作,将实例分割分成两个并行的分支:
- 使用FCN来生成分辨率较大的原型mask,原型mask不针对任何的实例。
- 目标检测分支添加额外的head来预测mask因子向量,用于对原型mask进行特定实例的加权编码。
这样做的原理在于,mask在空间上是连续的,卷积能很好地保持这种特性,因此原型mask通过全卷积生成的,而全连接层虽然不能保持空间连贯性,但能很好地预测语义向量,于是用来生成instance-wise的mask因子向量,结合两者进行预测,既能保持空间连贯性,也能加入语义信息并保持one-stage的快速性。最后取目标检测分支经过NMS后的实例,逐个将原型mask和mask因子向量相乘,再将相乘后的结果合并输出
Prototype Generation
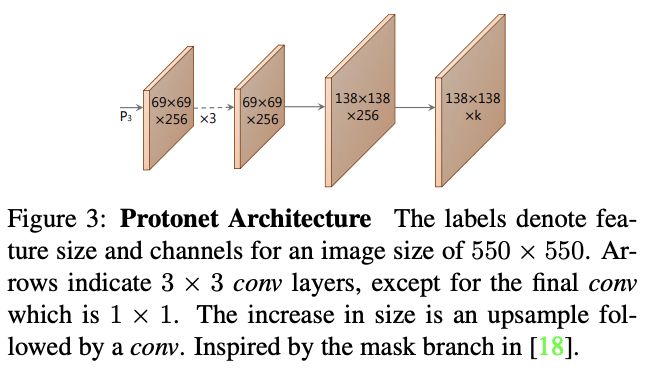
原型mask分支预测$k$个mask,protonet按如图3的FCN形式实现,最后的卷积输出channel为$k$,protonet接在主干网络上。整体的实现与大多数的语义分割模型类似,区别在于主干网络使用了FPN来增加网络的深度,并且保持较大的分辨率($P_3$, 原图1/4大小)来提高小物体的识别。另外,论文发现不限制protonet的输出是很重要的,能够让网络对十分确定的原型给予压倒性的响应(比如背景),可以选择对输出的原型mask进行ReLU激活或不接激活,论文最终选择了ReLU激活。
Mask Coefficients
在经典的anchor-based目标检测算法中,检测head一般有两个分支,分别预测类别和bbox偏移。在此基础上添加第三个用于mask因子预测的分支,每个实例预测$k$个mask因子。
为了更好地控制和丰富原型mask的融合,对mask因子进行tanh激活,使得值更稳定且有正负,效果如图2的分支。
Mask Assembly
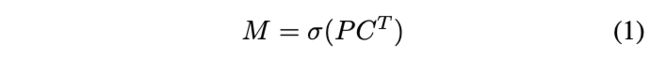
将原型mask和mask因子进行线性组合,然后对组合结果进行sigmoid激活输出最终的mask。$P$为$h\times w\times k$的原型mask,$C$为$n\times k$的原型因子,$n$为检测分支NMS和分数过滤后留下的实例数。
-
Losses
训练的损失函数包含3种:分类损失$L_{cls}$、box回归损失$L_{box}$以及mask损失$L_{mask}$,权重分别为1、1.5和6.125,分类损失和回归损失的计算与SSD一样,mask损失使用pixel-wise的二元交叉熵计算$L_{mask}=BCE(M, M_{gt})$
-
Cropping Masks
在推理阶段,使用预测的bbox在最终的mask截取出实例,再使用阈值(人工设置0.5)来过滤成二值的mask。在训练的时候,则使用GT来截取实例计算mask损失,$L_{mask}$会除以截取的实例大小,这样有助于保留原型中的小目标。
Emergent Behavior
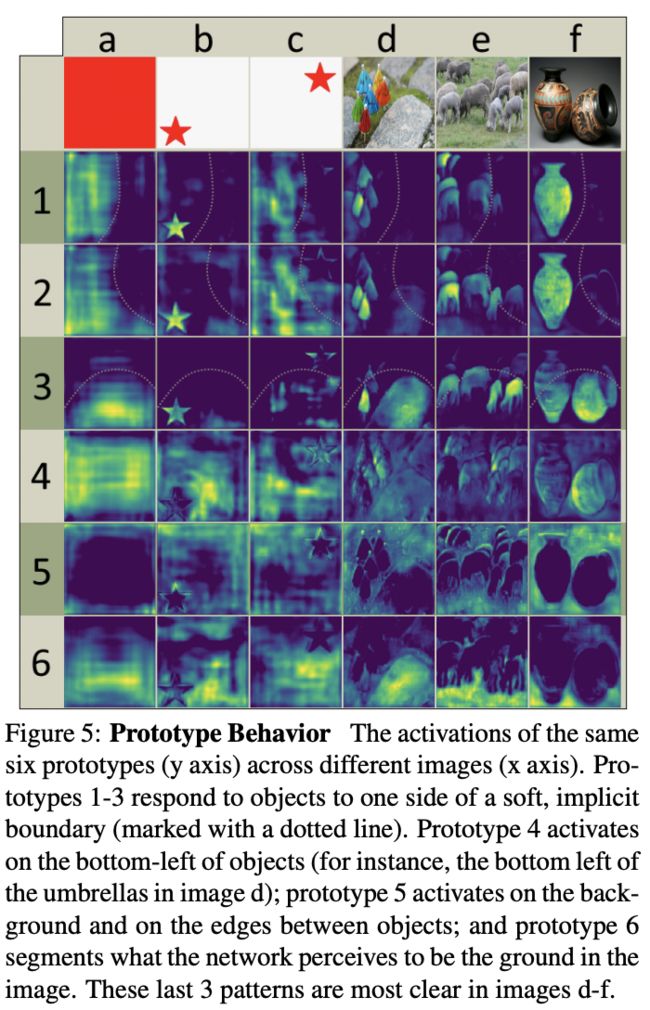
一般而言,FCN做分割都需要添加一些额外的trick来增加平移可变性,比如position-sensitive特征图,虽然YOLACT唯一增加平移可变形的措施是对最终的mask进行截取输出,但是论文发现对于中大物体不截取输出的效果也不错,这代表YOLACT的原型mask学到了对不同的实例进行不同的响应,如图5所示,适当地对原型mask进行组合就能得出实例。需要注意的是全红的输入图片,其原型mask特征是各不一样的,这是由于每次卷积都会padding,使得边界存在可区分性,所以主干网络本身就存在一定的平移可变形。
Backbone Detector
原型mask和mask因子的预测都需要丰富的特征,为了权衡速度和特征丰富性,主干网络采用类似与RetinaNet的结构,加入FPN,去掉$P_2$加入$P_6$和$P_7$,在多层中进行head预测,并用$P_3$特征进行原型mask预测。

YOLACT head使用$P_2 \sim P_7$的特征,anchor的大小分别对应$[24, 48, 96, 192, 384]$,每个head共享一个$3\times 3$卷积,然后再分别通过独立的$3\times 3$卷积进行预测,比RetinaNet更轻量,如图4。使用smooth-$L1$训练bbox预测,使用带背景类的softmax交叉熵训练分类预测,OHEM正负比例为$1:3$。
Other Improvements
Fast NMS
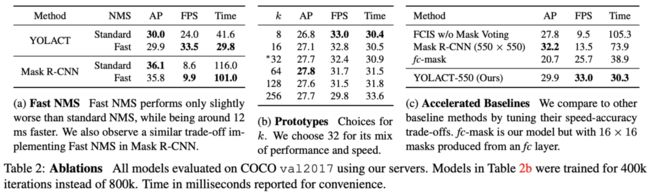
正常的NMS会串行地按类别将bbox逐个校验,这种效率对于5fps的算法是足够快的,但对于30fps的算法将是很大的瓶颈。为此,论文提出Fast NMS来加速。
首先根据类别分数对各检测结果进行排序,然后计算各自的IoU对,得到$c\times n\times n$的IoU矩阵$X$,$c$为类别数,$n$为bbox数量。假设与bbox的IoU高于阈值$t$的其它bbox的分数高于当前框,则去掉该bbox,计算逻辑如下:
- 将矩阵$X$的下三角和对角线置为0,$X_{kij}=0, \forall k, j, i \ge j$
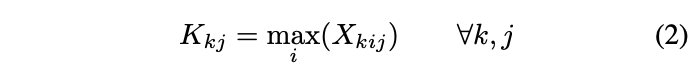
- 取每列的最大值,计算如公式2,得到最大IoU值矩阵$K$
- $K
通过实验,FastNMS大约能比原生的NMS快约11.8ms,mAP下降0.1
Semantic Segmentation Loss
为了提升准确率而不影响推理的速度,在训练阶段加入语义分割分支并计算语义分割损失辅助训练。在$P_3$输出上接一个c维的$1\times 1$卷积,由于一个像素可能属于多个类别,使用sigmoid激活输出而不是softmax激活,损失的权重为1,大约能提升0.4mAP。
Results
Mask Results
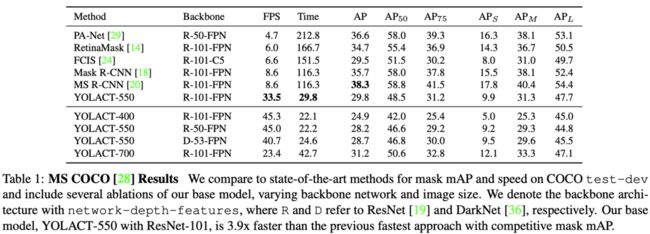
Mask Quality

Ablations
CONCLUSION
论文巧妙地基于one-stage目标检测算法提出实时实例分割算法YOLACT,整体的架构设计十分轻量,在速度和效果上面达到很好的trade-off。
写作不易,未经允许不得转载~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
