图像的超分辨率重建SRGAN与ESRGAN
SRGAN
传统的图像超分辨率重建方法一般都是放大较小的倍数,当放大倍数在4倍以上时就会出现过度平滑的现象,使得图像出现一些非真实感。SRGAN借助于GAN的网络架构生成图像中的细节。
训练网络使用均方误差(MSE)能够获得较高的峰值信噪比(PSNR),但是恢复出来的图像会丢失图像的高频细节信息,在视觉上有不好的体验感。SRGAN利用感知损失(perceptual loss)和对抗损失(adversarial loss)来提升输出图像的真实感。
MSE损失的计算:
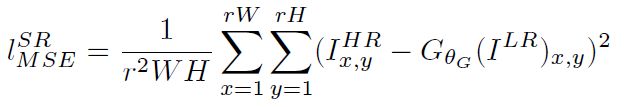 (1)
(1)
感知损失(perceptual loss):利用CNN提取的特征,通过比较生成图片经过CNN后的特征和目标图片经过CNN后的特征差别,使得生成的图片和目标图片在语义上更加相似。感知损失优化的是超分辨率模型的特征空间而不是像素空间。
文章中的代价函数改进为:
 (2)
(2)
第一部分是content loss 基于内容的代价函数,第二部分值基于对抗学习的代价函数。
基于内容的代价函数除了使用基于上述逐个像素空间的最小均方误差(MSE)以外,还使用了一个基于特征空间的最小均方误差,这个特征空间是利用VGG网络提取图像的高层次特征,具体方法如下:
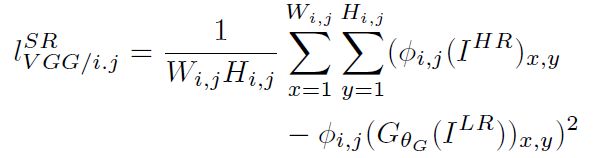 (3)
(3)
其中i和j表示VGG19网络中第i个最大池化层(maxpooling)后的第j个卷积层得到的特征。
也就是说内容损失可以二选一:可以是均方误差损失MSE (公式1),也可以是基于训练好的以ReLu为激活函数的损失函数(公式3)
第二部分 是对抗损失,其计算公式如下:
 (4)
(4)
其中是一个图像属于真实的高分辨率图像的概率。是重建的高分辨率图像
训练参数和细节
采用大数据进行训练,LR是HR图像进行下采样获得的(下采样因子r=4的双三次核)
使用Adam优化,其beta=0.9,lr=0.0001,迭代次数为100000.
生成器网络中的残差块为16个。
最后,对内容损失分别设置成基于均方误差、基于VGG模型低层特征和基于VGG模型高层特征三种情况作了比较
结论:在基于均方误差的时候表现最差,基于VGG模型高层特征比基于VGG模型低层特征的内容损失能生成更好的纹理细节。
pytorch代码实现:https://github.com/aitorzip/PyTorch-SRGAN
训练方法: 构建网络----》 找个一个较为清晰的数据集-------》对每张图片处理得到低分辨率图片---------》低分辨率数据集
用这两个数据集(HR database + LR database)来训练网络,实现从LR到HR的转化。
附:训练好的模型 https://github.com/brade31919/SRGAN-tensorflow (只能输入.png格式的图片)
参考博客:(https://blog.csdn.net/gavinmiaoc/article/details/80016051 )
ESRGAN
增强型的SRGAN
一、改进点与创新点:
1、引入残差密集块,并且将残差密集块(RRDB)中的残差作为基本的网络构建单元而不进行批量归一化(有助于训练更深的网络)。
使用残差缩放(residual scaling)
2、借用相对GAN的思想,让判别器判断的是相对真实性而不是绝对真实度 (RaGAN)。
3、利用VGG的激活前的特征值改善感知损失,会使得生成的图像有更加清晰的边缘(为亮度的一致性和纹理恢复提供更强的监控)
二 、算法的提出
目的:提高SR的总体感知质量
网络中的G的改进:
1)去掉BN层 2)使用残差密集块(RRDB)代替原始基础块,其结合了多残差网格和密集连接。
去掉BN层有助于增强性能和减少计算复杂度,并且当测试数据和训练数据存在差异很大时,BN有可能会引入伪影,从而限制网络的泛化能力。
仍然使用SRGAN的高级设计架构,但是会引入基本块RRDB。由于更多的层和更多的连接总会提高网络性能。RRDB比residual block拥有更深更复杂的结构。RRDB拥有residual-in-residual结构,残差学习应用于不同的层。但是本次是在多残差中使用了密集块
同时探索了新的方式来训练网络。1)使用残差缩放 2)使用较小的初始化 (????这一块不懂)

2)相对判别器RaD
相对判别器判断真实比假图更加真实的概率。
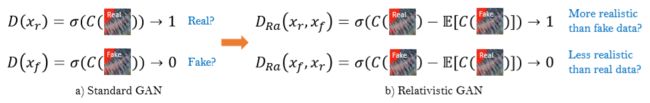
我们用相对论平均判别器RaD代替标准判别器,表示为![]() 。标准判别器在SRGAN可以表示为
。标准判别器在SRGAN可以表示为![]() ,其中
,其中![]() 是sigmoid函数,
是sigmoid函数,![]() 是非变换判别器输出。RaD可以用公式表示为,其中
是非变换判别器输出。RaD可以用公式表示为,其中![]() 表示在mini批处理中对所有假数据取平均值的操作。
表示在mini批处理中对所有假数据取平均值的操作。
判别器的损失可以定义为:

其中![]() 和
和![]() 代表LR图像输入。生成器的对抗损失包含了
代表LR图像输入。生成器的对抗损失包含了 和
和![]() 。
。
因此,我们的生成器优势适合于对抗训练中生成的数据和实际数据的渐变
3)感知损失
一种更有效的感知损失![]() ,在SRGAN通过激活前约束特征而不是激活后。
,在SRGAN通过激活前约束特征而不是激活后。
感知损失首先是Johnson et al提出的,并且在SRGAN中扩展,感知损失先前定义在预先训练好的网络的激活层上,其中,两个激活特征之间的距离被最小化。
本文提出使用的是激活层前的特性,优点在于:a、被激活的特征是非常稀疏的,如baboon的激活神经元的百分率在VGG19-54层后仅为11.17%。其中54表示最大池化层之前通过第4个卷积所获得的特征,表示高级特征,,类似地,22表示低维特征。
稀疏激活提供的弱监督会使得性能变差;;使用激活后的特征也会使得图像的亮度和真实图像不一样。
完整的损失函数表示:
![]()
其中![]() 是评估恢复图像
是评估恢复图像![]() 和真实图像
和真实图像![]() 之间的1-范数距离内容损失,
之间的1-范数距离内容损失,![]() 、
、![]() 是平衡不同损失项的系数。
是平衡不同损失项的系数。
4)网络插值 (不懂)
目的:去掉GAN-based中的不愉快的噪声,保证生成图片的质量更好。
先训练一个基于PSNR值的网络G_snr ,然后通过微调基于GAN的网络获得G_gan,然后对这两个网络进行插值计算,得到一个插值模型G_interp,其参数可以表示为:
其中![]() ,
,![]() 和
和![]() 是
是![]() ,
,![]() 和
和![]() 的参数;
的参数;![]() 是插值参数。
是插值参数。
优点:
a) 在不引入伪影的情况下对任何可行的![]() 产生有意义的结果。
产生有意义的结果。
b) 在不重新训练模型的情况下,持续地平衡感知质量和感觉。
代码地址:https://github.com/xinntao/ESRGAN
论文地址:https://arxiv.org/abs/1809.00219