3 个相见恨晚的 Google Colaboratory 奇技淫巧!
点击上方“AI有道”,选择“星标”公众号
重磅干货,第一时间送达

原文出处:
https://www.kdnuggets.com/2018/02/essential-google-colaboratory-tips-tricks.html
试想一下,如果有个免费的在线云端平台,既可以不用安装 TensorFlow 直接使用,又可以实现 GPU 加速训练,那该是多好的一件事情。你没听错,这种好事确实存在!今天我就重磅介绍一个谷歌推出的免费的云端工具:Colaboratory。
Colaboratory 是一个 Google 研究项目,旨在帮助传播机器学习培训和研究成果。它是一个 Jupyter 笔记本环境,不需要进行任何设置就可以使用,并且完全在云端运行。Colaboratory 笔记本存储在 Google 云端硬盘中,并且可以共享,就如同您使用 Google 文档或表格一样。Colaboratory 可免费使用。
也就是说,Colaboratory 存储在 Google 云端硬盘中,我们可以在 Google 云端硬盘里直接编写 Jupyter Notebook,在线使用深度学习框架 TensorFlow 并训练我们的神经网络了。超炫!

这里有 3 个令人相见恨晚的奇技淫巧来简化它的使用,分别是:使用免费的 GPU、安装库、上传并使用数据文件。
下面分别介绍:
1. 使用免费的 GPU
在打开的 Jupyter Notebook 中,选择菜单栏“代码执行程序(Runtime)”,“更改运行类型(Change runtime type)”,这时将看到以下弹出窗口:
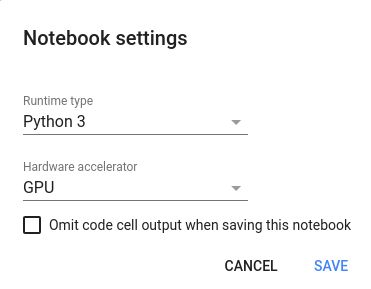
确保“硬件加速器(Hardware accelerator)”设置为 GPU(默认为 CPU)。设置完毕后点击保存。
值得注意的是确认笔记本处于已连接的状态:
![]()
检查是否真的开启了 GPU(即当前连接到了GPU实例),可以直接在 Jupyter Notebook 中运行以下命令:
import tensorflow as tf
device_name = tf.test.gpu_device_name()
if device_name != '/device:GPU:0':
raise SystemError('GPU device not found')
print('Found GPU at: {}'.format(device_name))
若输出以下语句,则表明已经使用了 GPU 实例。
Found GPU at: /device:GPU:0
但是,由于在线 GPU 资源有限,有时候可能会出现下面的问题提示:
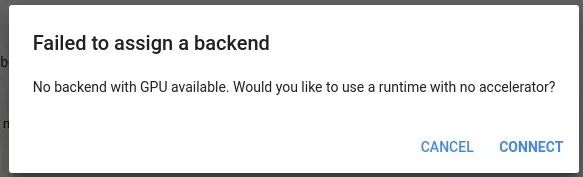
就这样,谷歌允许你一次最多持续使用 12 小时的免费 GPU。
2. 安装库
目前,在 Google Colaboratory 中安装的软件并不是持久的,意味着每次重新连接实例时都需要重新安装。但是,Colab 已经默认安装了需要有用的库,安装新的库也并非难事,方法也有好几种。
但需要注意的是,安装任何需要从源代码构建的软件可能需要很长的时间。
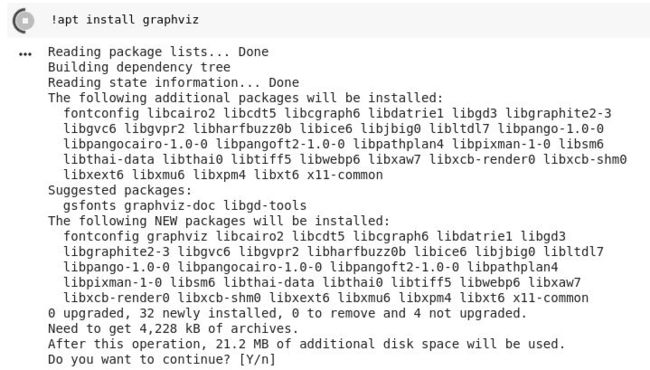
Colab 同时支持 pip 和 apt 包管理器。无论您使用的是哪一个,记住要在命令前面加上符号 “!”。
# Install Keras with pip
!pip install -q keras
import keras
>>> Using TensorFlow backend.
# Install GraphViz with apt
!apt-get install graphviz -y
3. 上传并使用数据文件
我们一般都需要在 Colab 笔记本中使用数据,对吧?你可以使用 wget 之类的工具从网络上获取数据,但是如果你有一些本地文件,想上传到你的谷歌硬盘中的 Colab 环境里并使用它们,该怎么做呢?
很简单,只需 3 步即可实现!
首先使用以下命令调用笔记本中的文件选择器:
from google.colab import files
uploaded = files.upload()
运行之后,我们就会发现单元 cell 下出现了“选择文件”按钮:

这样就可以直接选择你想上传的文件啦!
选择文件后,使用以下迭代方法上传文件以查找其键名,命令如下:
for fn in uploaded.keys():
print('User uploaded file "{name}" with length {length} bytes'.format(name=fn, length=len(uploaded[fn])))
例如待上传的是 iris.csv 文件,若运行没有问题的话,应该出现类似下面的提示语句:
User uploaded file "iris.csv" with length 3716 bytes
最后,就使用以下命令将文件的内容加载到 Pandas 的 DataFrame 中了:
import pandas as pd
import io
df = pd.read_csv(io.StringIO(uploaded['iris.csv'].decode('utf-8')))
print(df)
这种上传文件的方法是不是很简单呢?当然,上传和使用数据文件还有其它的方法,但是我发现这一方法最简单明了。
以上就是关于 Google Calaboratory 的 3 个非常实用的技巧,赶紧尝试一下吧!
最后,可能有的读者朋友对 Google Calaboratory 不太了解的,可以查看我之前写的一篇文章:如何在免费云端运行 Python 深度学习框架?链接如下:
https://redstonewill.com/1493/
也可以点击阅读原文查看!

【推荐阅读】
干货 | 公众号历史文章精选(附资源)
我的深度学习入门路线
我的机器学习入门路线图

麻烦点一下「好看」 ?