Graph DataBase介绍
前言
分析社会关系这类复杂图壮结构的海量数据,使用图形数据库(Graph DataBase)是最好的选择。– 作者:李祎
《程序员》介绍各种NoSQL 数据库的文章已经很多,不过大部分都是基于文档存储 (例如mongo DB)或键值(key-value) 存储(例如Redis 和Hbase)的。 本文介绍NoSQL 数据库中大家不是很熟悉的图形数据库(Graph DataBase),它拥有什么特性,以及它适合那些项目。希望开发者阅读本文后,能从中获得一些启发,在今后实施类似项目时多一种技术选择。
作为NoSQL数据库的一个类型,图形数据库(Graph Database)很长时间都局限在图理论相关的学术圈子里,在业界使用得并不广泛。直到近十年电子商务业务模式逐步成熟,电商们需要对用户在他们网站的购买行为进行分析、发掘用户潜在喜好的商品,开始大量使用到了图理论相关的数据挖掘算法,图形数据库才从实验室慢慢走进实际的软件工程项目中。特别是随着Facebook为代表的SNS网站兴起,对上千万的用户行为和关系数据进行挖掘,发掘其商业价值越发成为迫切的需求和工程难题。 工程师们发现使用图形数据库来存储和计算这些海量数据会更为高效和方便, 这极大推动了图形数据库的发展和它在NoSQL世界的知名度。 现在业内比较著名的图形数据库有Twitter网站的FlockDB , 以及开源项目中的Neo4j 和Infogrid。
Graph Database 的基础概念
- 点(Node)表示一个实体,例如人,商品,或是一个账户。
- 边 (Edge)也称做关系(relation),表示点和点之间的连接关系,例如用户A买了商品B。通常边是有方向性的,例如用户A购买了商品B,就表示为A->B;如果是用户A和用户C互相都认识,这种关系就是双向的,表示为A<->B。
- 属性(propertis)表示点(Node)和边(Edge)所附带的信息,例如一个用户,他带有的属性可能是年龄30岁,爱好篮球等等。需要注意的是,每个点的属性(properties)是动态的,例如同样是用户A和C,A有属性“年龄30岁”,C却没有。但是它却包含属性“职业工程师”。
把点(Node),边(Edge),属性(properties) 概念融合在一起,就可描述出一个图(graph)。图1描述了模拟《黑客帝国》的小型社会图(social graph)。

(图1)
其中每个头像都代表了一个点(Node), 注意Morpheus有的属性(propertis) rank:Captain, 在其他点都没有这个属性。 边(Edge)用蓝色箭头表示,箭头方向表明两者的关系,边也可拥有属性(properties),例如Morpheus 认识Trinity 包含属性 age:12 years。当千万个点和边被关联起来,这张Social Graph就被无限放大,构成了一张描述了整个虚拟社区的人际关系图。图形数据库就是用来存储这张海量数据关系图的最优工具,没有之一。
传统的关系型数据库和其他NoSQL数据库不能最优化的存储上述社会关系数据。 一方面,每个点包含的属性是不同的。 如果是在关系型数据库中建立的表结构,则需要有许多列的大型表,其中很多行的许多列是空的(稀疏表), 查询时需要联结大量表、使用深度嵌套的SQL。这导致了拙劣的性能,不适合高性能查询。另一方面,图形数据库针对图算法,提供了很多高效的操作特性,这也是它在图计算中优于关系数据库和其他类型NoSQL数据库的地方。例如:
- 遍历(Traversal): 不同于其他NoSQL数据库,图形数据库支持一系列图遍历的操作。例如图1中,找到Thomas和Architect之间的最短路径。 通常遍历(Traversal)操作需要传入两个参数,一个是启始点(star Node),一个是使用何种遍历规则(traversal specification)。遍历返回的结果,可能是零个,一个或多个点Node的集合。
- 事件(Events):这个和关系型数据库中的触发器比较类似,当某个事件发生触发某个操作。不同之处在于,关系数据库不能将事件通知到数据库外的应用程序。而对于图形数据库来说,它有可编程的监听接口来供外部程序监听各类事件。例如图1中,外部程序可以注册事件监听器(Event Listener),当 Smith 的version 属性从1.0变到5.0时,图形数据库将这个事件通知事件监听器。事件的支持对于管理和维护图形数据库非常有用,后面会介绍如何通过事件来解决NoSQL数据库中常见的数据老化问题。
- 索引(index):在关系型数据库中,对某张表进行过多的索引,当数据量大增时,效率就及其地下。而在graph Database中,对所有点的属性都可以建立索引,即使是千万级别的数据量,也能提供高效的查询。
图形数据库在数据结构,存储,遍历,以及查询方面都有别于其他NoSQL数据库。所以,对于社会关系这种复杂图壮结构的海量数据进行分析,使用图形数据库是最好的选择。不过现在的图形数据库都是雾里看花,在业界还没有一个称得上成熟的产品级应用,国内实际使用过图形数据库的项目更是少之又少。以其苦苦等待它的逐渐成熟,还不如我们自己动手搭建一个可用的图形数据库。下面以139说客(现在的移动微博)开发的图形数据库Skull DB为例,介绍在实际项目中如何实现和使用图形数据库。
Skull DB介绍
Skull DB实现了上述图形数据库的所有特性,不过在具体实现的数据结构上和上文略有差别。在Skull DB 的数据结构定义中(见图2)。

(图2)
Node类代表点,id用来标识Node在图中的唯一性,size表示该Node包含的边总数。Relationship类代表另一个点和另一点的边, 表示两个点的唯一关系。rel_id表示另一点的id。rel_value字段用于存储和边相关的任何属性(例如收听关系中被重复收听了多少次等信息)。modify_time表示边建立和修改的时间。RelationshipList代表一个Node和它所有的Relationship集合,它内部包含一个按Relationship的modify_time字段倒序排列的指针链表(LinkArray)组成。
以下图3中的收听关系为例,Thomas 表示为一个点:
Node thomas_node = new Node(“Thomas”);Thomas收听了Trinity 和Morpheus,其收听关系可表示为:
RelationshipList followingList = new RelationshipList(“Thomas”);
Relationship following_trinity = new Relationship(“trinity”, “1”); // “1” 代表Relationship 的value字段,在这里用“1”表示收听了1次。
followingList.add(following_trinity);
Relationship following_morpheus = new Relationship(“morpheus”, “1”);
followingList.add(following_ morpheus);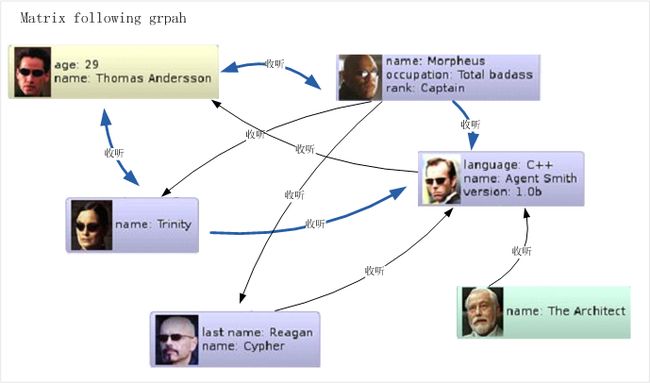
图3
下面以图3的收听数据为例,详细介绍如何用Skull DB建立和进行你收听的人间接收听了谁的推荐。
第一步是将用户收听的行为数据导入Skull DB。 一般我们拿到的数据是从生产环境导出的txt文件,使用skull DB提供的命令行工具txt2skull,将其导入到Skull DB中。
命令行:
txt2skull.sh family txtfile
- 第一个参数family,类似于BigTable中的column family,指定数据存储到那类数据集中。由于是用户收听关系,family我们用following表示
- 第二个参数txtfile,指明需要导入的用户好友关系文件位置。这里文件名是 user_following.txt
命令行:
txt2skull.sh following user_following.txt接下来就可以我们使用Skullclient对SkullDB进行访问,获取Thomas的收听关系:
RelationshipList thomasRelations = SkullClient.getRelationships(“following”, “thomas”, Direction.POSITIVE);
for(Relationship relation : thomasRelations) {
printRelation (relation)
}结果是: Trinity, Morpheus
这里Direction.POSITIVE 指定了查询Thomas收听的人,如果想查询都有谁收听了Thomas,使用Direction.REVERSE:
RelationshipList thomasRelations = SkullClient.getRelationships(“following”, “thomas”, Direction.REVERSE);
for(Relationship relation : thomasRelations) {
printRelation (relation)
}结果是: Agent Smith
第二步我们通过skull client查询,编写一个在微博应用中常见的推荐算法,查询Thomas 收听的人还间接收听了谁。
//allMap中包含了Thomas收听的人所有的收听列表。
Map allMap = SkullClient.getMultiRelationships(“following”, aRelations.getIds(), Direction.POSITIVE);
//对所有列表进行遍历,累计重复次数最高的Relationship.
SortedMap topMap = new TreeMap();
for(RelationshipList relationList : allMap.values()) {
for(Relationship relation : relationList) {
if (topMap.get(relation.getId()) != null) {
int repeats = topMap.get(relation.getId()).intValue() + 1; //累计重复被收听ID的出现次数
topMap.put(relation.getId(), new Integer(repeats));
} else {
topMap.put(relation.getId(), new Integer(1));
}
}
}
System.out.print(“你关注的人间接关注了 :” + topMap.lastKey()) ; // 打印重复次数最高的 ID 结果是 Agent Smith.
第三步,为了阻止数据库中的数据无限制增长,需要删除收听时间大于1年的过期数据。这里需要实现RelationEventListener 接口。当发现Node添加了新的Relationship时,遍历RelationhipList,删除收听时间大于1年的Relationship。
public class OldRelationCleaner implements RelationEventListener {
private fina long one_year = 365 * 24 * 60 * 60 * 1000;
public boolean EventReceived( Event event, EventData data ) {
String node_id = event.getNode().getId();
String family = event.getFamily();
RelationshipList relationships = skullclient.getRelationships(family, node_id, Direction.POSITIVE);
for (Relationship relation : relationships) {
if (System. currentTimeMillis() - relation.getModifyTime() > one_year ) {
skullclient.removeRelationship(family, node_id, relation);
}
}
}
}在程序中注册收听事件.
EventManager manager = EventManager.getInstance();
manager.registerRelationEventListener(“following”,new OldRelationCleaner());当Thomas收听了Architect后,在EventManager上注册的RelationEventListener被触发,遍历代表Thomas所有收听关系的RelationshipList实例relationships,找到收听时间大于1年的Relationship并删除。
Skull DB实现
简单的说Skull DB 是一个用Memcache做为数据缓存, Solr和Lucene负责数据物理存储和索引,用MemcacheQ来保存事件(Event)的集成系统。由于Solr和Memcache都有很好的横向扩展性, Skull DB很适合做为用户行为和关系等的数据仓库,提供高效率的查询和运算。

图4
客户端SkullClient 封装了所有对Skull DB的访问。SkullClient使用多级缓存和多线程从Skull DB获取数据。所有对Skull DB 中Node和Relationship的创建、读、写、以及删除操作,都通过SkullClient完成。当调用读接口时,SkullClient先访问Memcache,如果找不到数据,再发送Http请求从Solr获取。当调用写接口时,SkullClient将被修改的Relationship调整到RelationshipList列表的第一位,更新Memcache中的数据,同时异步发送Http请求将修改后的Lucene文档发送给Solr。同时发送异步Tcp请求,将写事件通知Event Daemon 模块。
Skull-admin.war模块可部署在任何WEB容器内(例如Tomcat),提供REST接口对Skull DB进行读写操作。它还可以通过jmx控制台进行包括:实时获取Memcache状态(见图5),查询Solr 统计数据,管理Event Daemon内部队列,查询Skull DB内部数据,进行数据导入和导出的操作。

图5
Mind模块封装了对Skull DB 的遍历(Travel) 和事件(Events)监听等方法。 同时还包含了一些常用的推荐算法。这个模块对Skull DB的读写通过调用SkullClient来完成。当有Node和Relationship被创建或更新时,SkullClient 调用异步线程将事件发送到Event Deamon模块,事件被直接保存到MemcacheQ中。事件后台进程(Event Deamon Processor)负责处理保存在MemcacheQ中的事件,更新Memcache和Lucene索引中的Node和Relationship对象。 处理完成后,事件后台进程将事件再发送给Mind模块的EventManager,通知所有注册事件的订阅者。
性能分析
我们使用一个新搭建的Skull DB进行性能测试,用20个并发线程向其插入用户好友关系。结果见图6,Y轴代表响应时间, X轴是测试执行的时间间隔(精确到秒)。

图6
本次测试总共插入 109645条Relationship记录,共耗时6分28秒,每个线程平均85毫秒完成一次更新。其中有2个较陡的响应时间波峰,这是因为Lucene在进行索引写文件操作,在IO上会有一些影响。

图7
本次测试共查询了15211个用户的好友关系,共耗时12秒,每个线程平均15毫秒完成一次查询。由于Relationship数据都被缓存在Memcache中,所以响应时间的的趋势是前高后低。
总结
在移动微博网站(www.139.com), 我们用Skull DB 存储用户的关系数据,评论转发数据, 登陆IP等数据。 配合Hadoop的Map-Reduce并行框架来计算亲密度、关系度、热度等指标。 Skull DB还被用于BI分析统计,保存用户的标签信息用于用户标签分类,发掘潜在用户的商业价值。我们之所以实现自己的图形数据库,一方面是因为数据存储方案,无法胜任高并发计算,高的IO吞吐效率,同时要对用户关系进行两步以上的遍历的需求。同时,我们对数据一致性要求不高,即使有少数数据不一致也不影响整体结果。 在实际项目中,Skull DB 也还存在Lucene索引效率需要加强,以及数据安全不高等方面的问题。我们项目组也在随着项目深入,不断完善它。Skull DB的成功就在不远处,我们还在路上。