Tensorflow进行POS词性标注NER实体识别 - 构建LSTM网络进行序列化标注
Github下载完整代码
https://github.com/rockingdingo/deepnlp/tree/master/deepnlp/pos
简介
这篇文章中我们将基于Tensorflow的LSTM模型来实现序列化标注的任务,以NLP中的POS词性标注为例实现一个深度学习的POS Tagger。文中具体介绍如何基于Tensorflow的LSTM cell单元来构建多层LSTM、双向Bi-LSTM模型,以及模型的训练和预测过程。对LSTM模型的基本结构和算法不熟悉的可以参考拓展阅读里的一些资料。 完整版代码可以在Github上找到:https://github.com/rockingdingo/deepnlp/tree/master/deepnlp/pos
数据和预处理
我们使用的词性标注POS的训练集来源是url [人民日报1998年的新闻语料],格式为”充满/v 希望/n 的/u 新/a 世纪/n ——/w 一九九八年/t”。具体的预处理过程包含以下步骤:
- 读取训练集数据:得到两个列表word和tag,其中word保存分词,Tag保存对应的标签;
- 构建词典:对词进行Count并且按照出现频率倒叙排列,建立字典表:word_to_id和tag_to_id 保存词和标签的id,未知词的标签即为UNKNOWN = "*";
- 分别读取训练集train, dev和test数据集,将数据集的word列表和tag列表分别转化为其对应的id列表。
- 构建一个迭代器iterator, 每次返回读取batch_size个词和标签的Pair对 (x,y)作为LSTM模型的输入。 x代表词ID的矩阵,y代表标签ID的矩阵,形状均为[batch_size, num_steps],代表batch_size组长度为num_steps的序列;矩阵中元素代表第x[i,j] 代表第i个batch下第j个词的ID,如“132”(面条),y[i,j] 为其对应标签的ID,如”3 ”(NN-名词)。
模型
图1 LSTM链式展开
图2 LSTM内部结构LSTM前向传播公式
input 门forget 门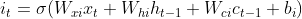
cell 状态更新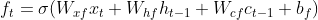
output 门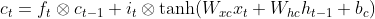
ht 隐藏层更新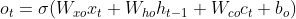
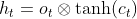
实现
1. 定义类和初始化函数init我们首先定义一个POSTagger类,通过初始化函数init,根据超参数构建tensorflow的一个graph模型。 所有LSTM模型的超参数保存在config这个类中,传入init函数。
代码1
class LargeConfigChinese(object):
"""Large config."""
init_scale = 0.04
learning_rate = 0.5
max_grad_norm = 10
num_layers = 2
num_steps = 30
hidden_size = 128
max_epoch = 5
max_max_epoch = 55
keep_prob = 1.0
lr_decay = 1 / 1.15
batch_size = 1 # single sample batch
vocab_size = 50000
target_num = 44 # POS tagging for Chinese
# 定义类和初始化函数init
class POSTagger(object):
"""The pos tagger model"""
def __init__(self, is_training, config):
self.batch_size = batch_size = config.batch_size
self.num_steps = num_steps = config.num_steps
size = config.hidden_size
vocab_size = config.vocab_size
target_num = config.target_num # target output number
# define model
# To Do- Init函数的输入参数config为一个包含超参数的类,具体输入包括:
- init_scale: 初始化参数的范围[-init_scale, init_scale]
- num_layers: LSTM模型的层数,默认为2层;
- hidden_size: LSTM模型每层节点数,默认128;
- num_steps: LSTM模型的步长T,代表共计算T个timestep,默认30;
- keep_prob: Dropout层留存的概率,为避免过拟合设置, 当数据集小的时候可以设置为1;
- vocab_size: 词典的单词个数,默认值50000;
- target_num:标签的个数,默认值 44,针对人民日报的标签体系下的44个词性标签;
- 其他
定义占位符Placeholder 在Tensorflow的图模型的Placeholder占位符,每次接受一组训练数据的字典表feed_dict,字典表中包含了我们在上一章节预处理中构建的迭代器iterator,每次返回(x,y)的Pair会被Feed进入占位符中: _input_data 和_targets的形状均为 [batch_size, num_steps],每个元素为词或者是标签的ID,保存为整数形tf.int32。 代码2
self._input_data = tf.placeholder(tf.int32, [batch_size, num_steps])
self._targets = tf.placeholder(tf.int32, [batch_size, num_steps])词向量Word Embedding层
现在我们将输入到占位符_input_data和_targets的ID数据,转化为对应的词向量。 在Tensorflow定义了简单方法:首先随机生成一个embedding矩阵,形状为[vocab_size, size],即词典大小vocab_size 乘以定义的词向量的维度 size。 然后利用tf.nn.embedding_lookup() 方法来查找每个ID对应的向量。这个过程就是将长度为vocab_size的One-Hot输入向量Xi转化为一个固定长度size的词向量。 在后向传播过程,词向量也同时得到训练。
代码3embedding = tf.get_variable("embedding", [vocab_size, size], dtype=data_type())
inputs = tf.nn.embedding_lookup(embedding, self._input_data)LSTM模型
基本LSTM单元:通过tf.nn.rnn_cell.BasicLSTMCell() 函数构建,size为LSTM的每层节点个数,forget_bias为偏移量,state_is_tuple=True为内部实现的一种结构,在tensorflow 0.10.0 后的版本为了提升计算速度已经建议均设置为TRUE,FALSE版本会被去除掉。
Dropout Wrapper层: 通过tf.nn.rnn_cell.DropoutWrapper() 函数可以在LSTM层加上Dropout避免训练过程的过拟合,通过设置 output_keep_prob 的概率来调节;
多层LSTM的cell单元:通过函数tf.nn.rnn_cell.MultiRNNCell() 构建,层数的参数是config.num_layers,第一层LSTM的输出会作为下一层LSTM的输入,将多层LSTM叠加在一起获得更好的模型Capacity;
代码4-1lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(size, forget_bias=0.0, state_is_tuple=True)
if is_training and config.keep_prob < 1:
lstm_cell = tf.nn.rnn_cell.DropoutWrapper(
lstm_cell, output_keep_prob=config.keep_prob)
cell = tf.nn.rnn_cell.MultiRNNCell([lstm_cell] * config.num_layers, state_is_tuple=True)双向LSTM模型 Bi-LSTM双向LSTM模型的传播过程与单向LSTM模型稍有区别:
- 分别定义两个LSTM基本单元,一个前向的lstm_fw_cell,一个后向的lstm_bw_cell
- 基于基本单元分别构建:多层前向LSTM单元cell_fw和多层后向LSTM的单元cell_bw:
- 定义两个前向LSTM和后向LSTM的初始状态:initial_state_fw和initial_state_bw
- 利用tf.nn.bidirectional_rnn() 函数完成传播过程:具体的两个LSTM分别得到隐含层的状态 hj_forward 和hj_backward,将[hj_forward,hj_backward]合并成为一个长度为2倍隐含层节点数的向量;
- 最后返回的参数有:outputs, state_fw, state_bw
lstm_fw_cell = tf.nn.rnn_cell.BasicLSTMCell(size, forget_bias=0.0, state_is_tuple=True)
lstm_bw_cell = tf.nn.rnn_cell.BasicLSTMCell(size, forget_bias=0.0, state_is_tuple=True)
cell_fw = tf.nn.rnn_cell.MultiRNNCell([lstm_fw_cell] * num_layers, state_is_tuple=True)
cell_bw = tf.nn.rnn_cell.MultiRNNCell([lstm_bw_cell] * num_layers, state_is_tuple=True)
initial_state_fw = cell_fw.zero_state(batch_size, data_type())
initial_state_bw = cell_bw.zero_state(batch_size, data_type())
# Split to get a list of 'n_steps' tensors of shape (batch_size, n_input)
inputs_list = [tf.squeeze(s, squeeze_dims=[1]) for s in tf.split(1, num_steps, inputs)]
with tf.variable_scope("pos_bilstm"):
outputs, state_fw, state_bw = tf.nn.bidirectional_rnn(
cell_fw, cell_bw, inputs_list, initial_state_fw = initial_state_fw,
initial_state_bw = initial_state_bw)前向传播
LSTM模型每次读取当前步t的输入Xt 和上一步的隐含层的向量h(t-1),通过LSTM内部结构的一系列计算得到相应的输出。定义前向过程,通过for循环,每次输入一个步t对应的词向量 inputs[:, time_step, :],是一个3D的Tensor [batch_size, time_step, size] 。其中size为词向量的维度。之后会将每一步的结果添加到outputs这个list中。
最后的全连接层:将output这个向量乘以softmax_w再加上偏移softmax_b,得到输出部分的logits,最后利用tf.nn.sparse_softmax_cross_entropy_with_logits 比较真实值的向量_targets和预测值的向量 logits,计算交叉熵cross-entropy的损失函数loss;
代码5state = self._initial_state
with tf.variable_scope("pos_lstm"):
for time_step in range(num_steps):
if time_step > 0: tf.get_variable_scope().reuse_variables()
(cell_output, state) = cell(inputs[:, time_step, :], state)
outputs.append(cell_output)
output = tf.reshape(tf.concat(1, outputs), [-1, size])
softmax_w = tf.get_variable(
"softmax_w", [size, target_num], dtype=data_type())
softmax_b = tf.get_variable("softmax_b", [target_num], dtype=data_type())
logits = tf.matmul(output, softmax_w) + softmax_b
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits, tf.reshape(targets, [-1]))关于损失函数
Tensorflow中定义损失函数有:tf.nn.sparse_softmax_cross_entropy_with_logits() 和 tf.nn.softmax_cross_entropy_with_logits()。 另外还有一个函数tf.nn.seq2seq.sequence_loss_by_example()接收参数和sparse_softmax_cross_entropy_with_logits类似。 二者输出结果一致,区别在于接收的输入不同:
- 函数tf.nn.sparse_softmax_cross_entropy_with_logits(logits, labels, name=None)
"sparse_softmax"这个函数输入参数labels表示待拟合的标签,形状为 [batch_size] ,每个值为一个整形数值,int32或者int64, 代表了待预测标签的ID,即每个样本的标签有且仅有一个。
- 函数tf.nn.softmax_cross_entropy_with_logits(logits, labels, dim=-1, name=None)
"softmax" 这个函数输入参数labels形状为[batch_size, num_classes],每个元素类型为float32或者 float64。每个样本对应的标签向量可以是One-Hot表示,即每个样本只属于一个类别;同时也可以是对应多个标签soft softmax,即每个样本的label不仅限于一个,而是给出符合每个类别的概率分布。这个函数支持一个样本在多个类别下都有分布情况。
- fetches:定义需要评估和取出的数值,这里我们要计算取出model.cost, model.final_state 和 eval_op三个参数,其中eval_op 为前向过程中定义的SGD梯度下降的操作符:self._train_op = optimizer.apply_gradients(zip(grads, tvars))
- feed_dict: 将每次迭代器返回的(x,y) Pair对的值,分别赋给input_data和target这两个占位符。
session.run() 函数每次将feed_dict的数据输入Graph模型,计算后返回fetches列表中定义的几个变量[cost, state, _ ]。_ 代表了评估的operator。
代码6def run_epoch(session, model, word_data, tag_data, eval_op, verbose=False):
"""Runs the model on the given data."""
epoch_size = ((len(word_data) // model.batch_size) - 1) // model.num_steps
start_time = time.time()
costs = 0.0
iters = 0
state = session.run(model.initial_state)
for step, (x, y) in enumerate(reader.iterator(word_data, tag_data, model.batch_size,
model.num_steps)):
fetches = [model.cost, model.final_state, eval_op]
feed_dict = {}
feed_dict[model.input_data] = x
feed_dict[model.targets] = y
for i, (c, h) in enumerate(model.initial_state):
feed_dict[c] = state[i].c
feed_dict[h] = state[i].h
cost, state, _ = session.run(fetches, feed_dict)
costs += cost
iters += model.num_steps
if verbose and step % (epoch_size // 10) == 10:
print("%.3f perplexity: %.3f speed: %.0f wps" %
(step * 1.0 / epoch_size, np.exp(costs / iters),
iters * model.batch_size / (time.time() - start_time)))
# Save Model to CheckPoint when is_training is True
if model.is_training:
if step % (epoch_size // 10) == 10:
checkpoint_path = os.path.join(FLAGS.pos_train_dir, "pos.ckpt")
model.saver.save(session, checkpoint_path)
print("Model Saved... at time step " + str(step))
return np.exp(costs / iters)延伸阅读
http://www.deepnlp.org/blog/tensorflow-lstm-pos/
Python Package Index - deepnlp: Deep Learning NLP Pipeline implemented on Tensorflow
https://pypi.python.org/pypi/deepnlp
- Understanding LSTM Networks
- Tensorflow:difference between sparse_softmax_cross_entropy_with_logits and softmax_cross_entropy_with_logits?
-