大话文本检测经典模型:SegLink

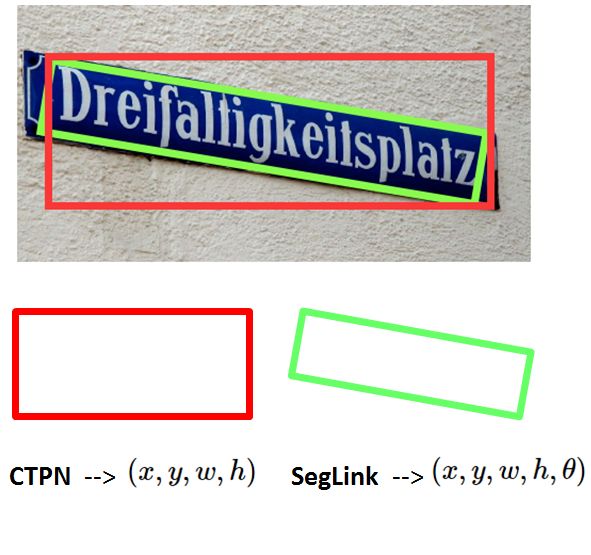
在自然场景中,例如灯箱广告牌、产品包装盒、商标等,要检测出其中的文字会面临着各种复杂的情况,例如角度倾斜、变形等情况,这时就需要使用基于深度学习的方法进行文字检测。在之前的文章中,介绍了基于卷积神经网络和循环神经网络的CTPN文本检测方法(见文章:大话文本检测经典模型 CTPN),该方法能在自然场景下较好地实现对文字的检测,但在CTPN中给出的文本检测效果是基于水平方向的,对于非水平的文本检测效果并不好,而在自然场景中,很多的文本信息都是带有一定的旋转角度的,例如用手机拍街道上的指示牌,如下图。如果文本检测的结果只有水平方向的,没有带角度信息,那么下图指示牌检测出来的就是红色框结果,而其实绿色框才是理想的检测目标,可见检测的结果误差太大。

那要怎样才能实现对各种角度的灵活检测呢?一个最直接的思路就是让模型不仅能学习和输出边框的位置(x, y, w, h),还要能输出一个文本框的旋转角度参数θ。本文要介绍的文本检测模型SegLink,便是采用了这个思路,也即SegLink检测模型能检测有旋转角度的文本,如下图:
一、SegLink模型的主要思想
SegLink模型的检测过程主要如下:

1、首先是检测生成一个一个的segment(切片),如上图黄色框,这些segment(切片)是文本行(或单词)的一部分,可能是一个字符,或者是一个单词,或者是几个字符
2、通过link(链接)将属于同一个文本行(或者单词)的segment(切片)连接起来,如上图绿色线条。link(链接)是在两个有重叠segment的中心点进行相连,如下图

3、通过合并算法,将这些segment(切片)、link(链接)合并成一个完整的文本行,得出完整文本行的检测框位置和旋转角度。
其中,segment(切片)、link(链接)是SegLink模型的创新之处,该模型不但学习了segment的位置信息,也学习了segment之间的link关系,以表示是否属于同一文本行(或者单词)。
二、SegLink模型的网络结构
SegLink模型的网络结构如下:

该模型以VGG16作为网络的主要骨干,将其中的全连接层(fc6, fc7)替换成卷积层(conv6, conv7),后面再接上4个卷积层(conv8, conv9, conv10, conv11),其中,将conv4_3,conv7,conv8_2,conv9_2,conv10_2,conv11这6个层的feature map(特征图)拿出来做卷积得到segments(切片)和links(链接)。这6个层的feature map(特征图)尺寸是不同的,每一层的尺寸只有前一层的一半,从这6个不同尺寸的层上得到segment和link,就可以实现对不同尺寸文本行的检测了(大的feature map擅长检测小物体,小的feature map擅长检测大物体)。
1、segment检测
整个架构采取了SSD的思路,在segment(切片)检测上,与SSD模型检测过程类似,通过“套框”的方式,对结果进行回归,每个feature map(特征图)经过卷积后输出的通道数为7,其中两个表示segment是否为文字的置信度值为(0, 1),剩下的五个为segment相对于对应位置的default box的五个偏移量。每个segment表示为:
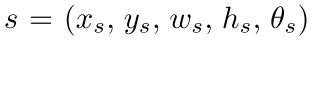
2、link检测
在segment与segment的link(链接)方面,主要存在两种情况,一种是层内链接检测、另一种是跨层链接检测。如下图:
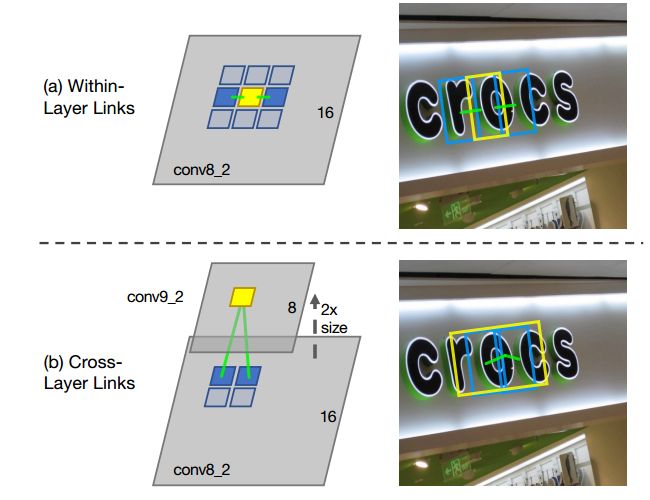
其中,层内链接检测表示同一特征层,每个segment与8邻域内的segment的连接状况,每个link有两个分数:正分、负分,正分表示二者属于同一个文本(应该连接);负分表示二者属于不同文本(应该断开连接)。而跨层链接检测,主要是为了解决同一文本的segment在不同层被检测到,造成重复检测、冗余的问题,在相邻两层的feature map上,后面那层的segment的邻居除了是本层的邻居外,在前一层也有它的邻居,但后一层却不是前一层的邻居,在后面的合并算法中会将这种冗余消除掉。
3、合并算法
合并算法的思想如下:
- 将同一行的segment取出来
- 对这些segment的中心点作最小二乘法线性回归,得到一条直线
- 每个segment的中心点往这条直线做垂直投影
- 从所有投影点中取出距离最远的两个点,记为(xp,yp)、(xq,yq)
- 那么最终合并的文本框,(1)中心点位置为( (xp+xq)/2 , (yp+yq)/2 ),(2)宽度为两个最远的点(xp,yp)、(xq,yq)的距离加上所在segment宽度的一半(Wp/2 + Wq/2),(3)高度为所有segment的高度平均值
如下图所示,中间橙色直线表示最小二乘法回归后的直线,红点表示segment的中心点,黄点表示红点在直线上的垂直投影,绿色边框就是经过以上合并算法处理后的完整本文框。

三、小结
SegLink增加了角度的检测,对于各种角度的文本检测具有很强的鲁棒性,而CTPN主要用于检测水平的文本行,如下图所示:

但该模型也存在不足之处,例如不能检测间隔很大的文本行,因为相邻segment之间主要是通过link来连接,文本相距太远时就会效果不好。另外,不能检测形变或者曲线文本,这是因为最后在做合并算法时采用的是线性回归的方式,只能拟合直线,无法拟合曲线,但也可以通过修改合并算法,来实现对变形、曲线文本的检测。
墙裂建议
2017年,Baoguang Shi 等人发表了关于SegLink的经典论文《 Detecting Oriented Text in Natural Images by Linking Segments 》,在论文中详细介绍了SegLink的技术原理,建议阅读该论文以进一步了解该模型。
关注本人公众号“大数据与人工智能Lab”(BigdataAILab),然后回复“论文”关键字可在线阅读经典论文的内容。

推荐相关阅读
- 【AI实战】手把手教你文字识别(入门篇:验证码识别)
- 【AI实战】快速掌握TensorFlow(一):基本操作
- 【AI实战】快速掌握TensorFlow(二):计算图、会话
- 【AI实战】快速掌握TensorFlow(三):激励函数
- 【AI实战】快速掌握TensorFlow(四):损失函数
- 【AI实战】搭建基础环境
- 【AI实战】训练第一个模型
- 【AI实战】编写人脸识别程序
- 【AI实战】动手训练目标检测模型(SSD篇)
- 【AI实战】动手训练目标检测模型(YOLO篇)
- 【精华整理】CNN进化史
- 大话文本识别经典模型(CRNN)
- 大话文本检测经典模型(CTPN)
- 大话文本检测经典模型(SegLink)
- 大话卷积神经网络(CNN)
- 大话循环神经网络(RNN)
- 大话深度残差网络(DRN)
- 大话深度信念网络(DBN)
- 大话CNN经典模型:LeNet
- 大话CNN经典模型:AlexNet
- 大话CNN经典模型:VGGNet
- 大话CNN经典模型:GoogLeNet
- 大话目标检测经典模型:RCNN、Fast RCNN、Faster RCNN
- 大话目标检测经典模型:Mask R-CNN
- 27种深度学习经典模型
- 浅说“迁移学习”
- 什么是“强化学习”
- AlphaGo算法原理浅析
- 大数据究竟有多少个V
- Apache Hadoop 2.8 完全分布式集群搭建超详细教程
- Apache Hive 2.1.1 安装配置超详细教程
- Apache HBase 1.2.6 完全分布式集群搭建超详细教程
- 离线安装Cloudera Manager 5和CDH5(最新版5.13.0)超详细教程