循环神经网络原理
循环神经网络(RNN)简介,循环神经网络是一种专门处理序列(sequences)的神经网络。它们通常用于自然语言处理(NLP)任务,因为它们在处理文本方面非常有效。在本文中,我们将探索什么是RNNs,了解它们是如何工作的,并在Python中从头构建一个真正的RNNs(仅使用numpy)。
这篇文章假设有神经网络的基本知识。我对神经网络的介绍涵盖了你需要知道的一切,所以我建议你先读一下。
本文更完整的内容请参考极客教程的深度学习专栏:https://geek-docs.com/deep-learning/rnn/rnn-introduction.html
让我们开始吧!
The Why
普通神经网络(以及CNNs)的一个问题是,它们只对预先确定的大小起作用:它们接受固定大小的输入并产生固定大小的输出。RNNs是有用的,因为它让我们有可变长度的序列作为输入和输出。下面是一些关于RNNs的例子:

*输入为红色,RNN本身为绿色,输出为蓝色。
这种处理序列的能力使RNNs非常有用。例如:
- 机器翻译(例如谷歌翻译)是通过“多对多”的RNNs来完成的。原始文本序列被输入一个RNN,然后RNN生成翻译文本作为输出。
- 情绪分析(例如,这是一个积极的还是消极的评论?)通常是用“多对一”的RNNs来完成的。要分析的文本被输入一个RNN,然后RNN生成一个输出分类(例如,这是一个积极的评论)。
在这篇文章的后面,我们将从头构建一个“多对一”的RNN来执行基本的情绪分析。
The How
让我们考虑一个“多对多”的RNN,它的输入 x 0 x_0 x0, x 1 x_1 x1,…, x n x_n xn,希望产生输出 y 0 y_0 y0, y 1 y_1 y1,…, y n y_n yn。这些 x i x_i xi和 y i y_i yi是向量,可以有任意的维数。
RNNs的工作方式是迭代地更新一个隐藏状态h,这是一个向量,也可以有任意的维数。在任意给定的步骤t,
- 下一个隐藏状态 h t h_t ht使用前一个隐藏状态 h t − 1 h_{t-1} ht−1和下一个输入 x t x_t xt计算来的
- 下一个输出 y t y_t yt是用 h t h_t ht计算得来的
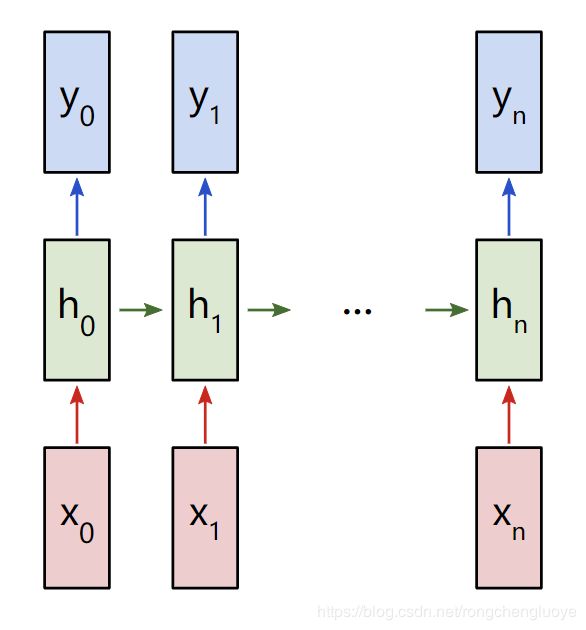
多对多RNN
这就是RNN的递归性:它对每个步骤使用相同的权重。更具体地说,一个典型的普通RNN只使用3组权重来进行计算:
- W x h W_{xh} Wxh 用于所有 x t x_t xt–> h t h_t ht的链接
- W h h W_{hh} Whh 用于所有 h t − 1 h_{t-1} ht−1–> h t h_t ht的链接
- W h y W_{hy} Why 用于所有 h t h_t ht–> y t y_t yt的链接
我们的RNN也会使用两个偏差:
- b h b_h bh,计算 h t h_t ht时相加
- b y b_y by,计算 y t y_t yt时相加
我们用矩阵表示权重,用向量表示偏差。这3个权重和2个偏差构成了整个RNN!
下面是把所有东西放在一起的方程式:

不要略过这些方程式。停下来,盯着这个看一分钟。另外,记住权重是矩阵,其他变量是向量。
所有的权值都使用矩阵乘法,并将偏差添加到结果乘积中。然后,我们使用tanh作为第一个方程的激活函数(但也可以使用sigmoid等其他激活函数)。
不知道什么是激活函数?阅读我之前提到的关于神经网络的介绍。认真对待。
The Problem
让我们动手干吧!我们将从头实现一个RNN来执行一个简单的情绪分析任务:确定给定的文本字符串是积极的还是负面的。
下面是我为这篇文章收集的小数据集中的一些例子:

The Plan
由于这是一个分类问题,我们将使用“多对一”RNN。这类似于我们前面讨论的“多对多”RNN,但它只使用最终的隐藏状态产生一个输出y:
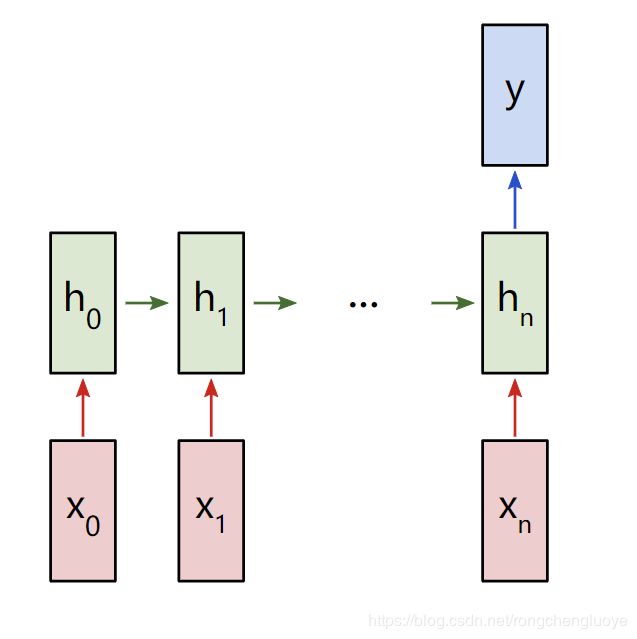
多对一RNN
每个 x i x_i xi都是一个向量,表示文本中的一个单词。输出y将是一个包含两个数字的向量,一个表示正数,另一个表示负数。我们将使用Softmax将这些值转换为概率,并最终在正/负之间做出决定。
让我们开始构建我们的RNN!
The Pre-Processing
我前面提到的数据集由两个Python字典组成:
data.py
train_data = {
'good': True,
'bad': False,
# ... more data
}
test_data = {
'this is happy': True,
'i am good': True,
# ... more data
}
True = Positive, False = Negative
我们必须做一些预处理才能把数据转换成可用的格式。首先,我们将构建一个包含数据中所有单词的词汇表:
main.py
from data import train_data, test_data
# Create the vocabulary.
vocab = list(set([w for text in train_data.keys() for w in text.split(' ')]))
vocab_size = len(vocab)
print('%d unique words found' % vocab_size) # 18 unique words found
vocab现在包含了至少一个训练文本中出现的所有单词的列表。接下来,我们将分配一个整数索引来表示vocab中的每个单词。
main.py
# Assign indices to each word.
word_to_idx = { w: i for i, w in enumerate(vocab) }
idx_to_word = { i: w for i, w in enumerate(vocab) }
print(word_to_idx['good']) # 16 (this may change)
print(idx_to_word[0]) # sad (this may change)
我们现在可以用对应的整数索引表示任意给定的单词!这是必要的,因为RNNs不能理解单词——我们必须给他们数字。
最后,回忆一下RNN的每个输入 x i x_i xi都是一个向量。我们将使用一个热向量(one-hot vectors),它包含一个元素为非零,而其他元素都是0。每个热向量中的“1”将位于单词对应的整数索引处。
由于我们的词汇表中有18个独特的单词,每个 x i x_i xi将是一个18维的一维热向量。
main.py
import numpy as np
def createInputs(text):
'''
Returns an array of one-hot vectors representing the words
in the input text string.
- text is a string
- Each one-hot vector has shape (vocab_size, 1)
'''
inputs = []
for w in text.split(' '):
v = np.zeros((vocab_size, 1))
v[word_to_idx[w]] = 1
inputs.append(v)
return inputs
稍后,我们将使用createInputs()创建向量输入,以传递到RNN。
The Forward Phase
是时候开始实现我们的RNN了!我们将从初始化RNN需要的3个权重和2个偏差开始:
rnn.py
import numpy as np
from numpy.random import randn
class RNN:
# A Vanilla Recurrent Neural Network.
def __init__(self, input_size, output_size, hidden_size=64):
# Weights
self.Whh = randn(hidden_size, hidden_size) / 1000
self.Wxh = randn(hidden_size, input_size) / 1000
self.Why = randn(output_size, hidden_size) / 1000
# Biases
self.bh = np.zeros((hidden_size, 1))
self.by = np.zeros((output_size, 1))
注意:我们除以1000是为了减小权重的初始方差。这不是初始化权重的最佳方法,但它很简单,适合本文。
我们使用np.random.randn()从标准正态分布初始化权重。
接下来,让我们实现RNN的正向传递(forward pass)。还记得我们之前看到的这两个方程吗?
文章整理自人工智能全套资料,分享下共计十多个附档下载地址给大家:
https://pan.baidu.com/s/19EBUWL_op9HxaZPe664eew
提取码: g4zq
余文请继续访问极客教程深度学习专栏:循环神经网络 https://geek-docs.com/deep-learning/rnn/rnn-introduction.html