神经网络可视化(Visualization of Neural Network )
神经网络可视化和可解释性(Visualization and Explanation of Neural Network )
相对于传统的ML模型,Deep NN由于其自身所特有的多层非线性的结构而导致难以对其工作原理进行透彻的理解。比如,我们很难理解网络将一个输入x判断为某一类别c时,其输入向量x中的每一个特征分别对这个结果贡献了多大,找出哪些输入特征起到了关键作用,这对判断网络是否正常工作是很重要的。尤其在NLP领域,由于现在大多数模型的输入都是稠密的Embedding向量,而每一个维度上的值并没有一个显式的含义,这就使得我们很难像图像领域那样,直接可视化CNN中的filters,分析网络所学习到的特征。
文章目录
- 神经网络可视化和可解释性(Visualization and Explanation of Neural Network )
- 1.现有的方法
- 1.1 Interpreting Models
- 1.2 Explaining decisions
- 2. SA & Decomposition
- 2.1 SA
- 2.2 Decomposition
- 2.2.1 LRP Framework
- 2.2.2 Deep Taylor Decomposition
- 3.如何评估
- 4. NLP中的应用
- 5. Keras 开源框架innvestigate分析
- 5.1 框架执行流程图
- 5.2 Z-Rule
- 5.3 $W^2$-rule
- 5.4 alpha-beta rule
- 5.5 Embedding pooling
- 6.更进一步的思考
1.现有的方法
现有的网络解释思路大致可以分为两大类:模型解释(Interpreting Models)和决策解释(Explaining Decision)
1.1 Interpreting Models
这类方法的主要解释手段是:
a. find prototypical example of a category
找到一个类别的典型样本,比如1-10的手写字体图片分类,对于类别1, 我们的目的就是找到最能代表数字1的样本,即找到使分类函数f(x)输出值最大的x。
b. find pattern maximizing activity of a neuron
找到能够最大化激活神经元的pattern,以上边的例子来说,即找到能够最大化激活网络的pixel空间组合方式(比如在手写数字识别任务中,CNN模型的高层filter里边,通常每个pattern对应于一个模糊的数字,如:“1”)
这一类的方法倾向于得到一个整体上的(ensemble)的结论,即找出某个数字(比如“1”)最常见的图片模式应该是怎样
1.2 Explaining decisions
a.“why” does the model arrive at this particular prediction
试图解释为什么模型能够做出这样的预测,比如,为啥将一张图片分类为数字“1”而不是其它
b.verify that model behaves as expected
验证模型是否按期望运行,以上边的例子来说,当模型将一个输入x预测为“1”时,起主要作用的特征(pixels)应该是组成数字“1”的附近的pixels
在这一思路下,大致有两类方法:Sensitivity Analysis(SA)和Decomposition。
2. SA & Decomposition
为了说明方便,我们先定义几个符号:
神经网络分类函数: f ( x ) f(x) f(x)
输入向量: x x x
对于最终生成的heatmapping R ( x ) = { R p ( x ) } \boldsymbol{R(x)}=\{R_p(x)\} R(x)={Rp(x)},
接下来,再定义如下性质:
- 1. Conservative, 即 ∀ x : f ( x ) = ∑ p R p ( x ) \forall x: f(x)=\sum_p R_p(x) ∀x:f(x)=∑pRp(x)
这里粗体的 R ( x ) \boldsymbol{R(x)} R(x)表示整个heatmapping的元素集合(可以看做一个向量, 其对应的输入 x \boldsymbol{x} x也是一个向量), R p ( x ) R_p(x) Rp(x)表示heatmapping上的第 p p p个元素, 也称为Relevance, 对应输入向量中的一个分量 x p x_p xp. Conservative 确保在向后传播时, 每层所有神经元对应的Relevance之和能够始终等于最终分类的预测值. 最终 R ( x ) \boldsymbol{R(x)} R(x)将以图片的形式展示出来,这就是所谓的Visualization了。
- 2. Positive, 即 ∀ x , p : R p ( x ) ≥ 0 \forall x, p: R_p(x)≥0 ∀x,p:Rp(x)≥0
这个性质确保heatmapping中的元素不存在相互矛盾的对象, 即某些元素是与最终结果正相关, 某些元素是负相关.这样做的好处是可以简化最终的relevance分布.
最后,同时具备1和2的, 我们就称之为"一致的"( c o n s i s t e n t consistent consistent), 需要注意的是, c o n s i s t e n t consistent consistent对于heatmapping虽然不是一个硬性的要求, 但满足一致性条件的heatmapping将具备一系列优良的性质,因此我们的方法要尽可能的符合 c o n s i s t e n t consistent consistent约束。
2.1 SA
SA方法,主要原理是通过输入x对输出y的影响程度来对x的每一个特征(分量)进行打分, 通过对打分进行可视化,最终将形成一张heatmapping.而打分的方法, 使用非常符合直觉的梯度, 即:
R p ( x ) = ( ∂ f / ∂ x p ) 2 R_p(x)= (\partial f / \partial x_p )^2 Rp(x)=(∂f/∂xp)2
∴ R ( x ) = ∥ ∇ x f ( x ) ∥ 2 ∴\boldsymbol{R(x)}=\|\nabla_{\!\boldsymbol{x}} f (\boldsymbol{x})\|^2 ∴R(x)=∥∇xf(x)∥2
有时,为了区分出positive和negative的影响,可以去掉平方运算:
R p ( x ) = ( ∂ f / ∂ x p ) R_p(x)= (\partial f / \partial x_p ) Rp(x)=(∂f/∂xp)
SA方法的优点是实现容易, 很符合直观感受,但缺点也很明显:输出的heatmap只是反映了增加(或减小)对应输入位置的值对预测结果的影响,并未直接反映出该点输入值本身对结果的影响。e.g. 当前位置梯度 R p > 0 R_p>0 Rp>0,而对应的输入 x p < 0 x_p<0 xp<0
2.2 Decomposition
2.2.1 LRP Framework
从字面上看,Decomposition就是分解,这种方法的本质也是将最终输出的Relevance进行分解再向上传递。该怎么分解呢?我们先看下图的DNN网络结构:
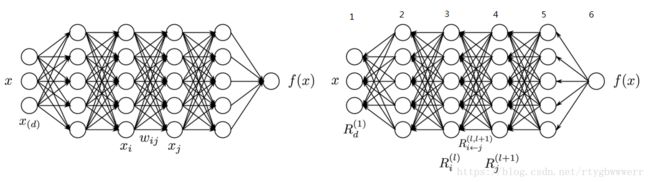
在上图所示的网络中,最终输出出值为 f ( x ) f(x) f(x), 显然,对于输出层而言,其Relevance就为: R f = f ( x ) R_f=f(x) Rf=f(x)
那么第 l l l层的第 i i i个节点的Relevance R i ( l ) R_i^{(l)} Ri(l)应该为什么呢?首先根据性质2, 每层所有节点的Relevance之和应该相等:
∑ d R d ( 1 ) = ∑ k R k ( 2 ) = . . . = ∑ i R i ( l ) = ∑ j R j ( l + 1 ) = . . . = R f \sum_d R_d^{(1)} = \sum_k R_k^{(2)} =...=\sum_i R_i^{(l)}=\sum_j R_j^{(l+1)}=...=R_f d∑Rd(1)=k∑Rk(2)=...=i∑Ri(l)=j∑Rj(l+1)=...=Rf
我们可以把Relevance看做一种沿着网络连线流动的信息,其流动方向为输出节点到输入节点,其值总和为 R f R_f Rf. 那么我们可以参考反向传播的思想,将网络结构倒过来(上图右), 沿着节点间的子路径将Relevance逐层分解, 比如从层 6 → 5 6 \rightarrow 5 6→5 , 这里我们始终假设 i i i代表低层神经元的序号, j j j代表高层神经元的序号:
R i ← j ( 5 , 6 ) = f a c t o r i j ( 5 , 6 ) ⋅ R j ( 6 ) R^{(5, 6)}_{i \leftarrow j} = factor_{ij}^{(5,6)} \cdot R^{(6)}_j Ri←j(5,6)=factorij(5,6)⋅Rj(6)
其中 f a c t o r i j factor_{ij} factorij表示分配因子,是一个介于[0,1]之间的数, 并满足:
∑ i f a c t o r i j ( 5 , 6 ) = 1 \sum_i factor_{ij}^{(5,6)} = 1 i∑factorij(5,6)=1
对于任意一个上层神经元, 其输入 z j ( l ) = W j ( l ) a ( l − 1 ) z^{(l)}_j = W^{(l)}_j a^{(l-1)} zj(l)=Wj(l)a(l−1), 其中 a ( l − 1 ) a^{(l-1)} a(l−1)为低层神经元的激活输出向量. 上层单元j的最终输出为 σ ( z j ( l ) ) \sigma(z^{(l)}_j) σ(zj(l)). 由于神经元的激活函数通常为单调递增函数,所以, 输入值越大,那么对应的激活值也就越大。因此 z j ( l ) z^{(l)}_j zj(l)的每个分量 z i j ( l ) z^{(l)}_{ij} zij(l)可以看做是每个下层单元 i i i与上层单元 j j j之间的Relevance分配因子, 由于还需要满足归一化的约束, 我们可以对其除以一个归一化参数 z j ( l ) z^{(l)}_j zj(l):
f a c t o r i j = z i j ( l ) z j ( l ) = w i j ( l ) a i ( l − 1 ) ∑ i w i j ( l ) a i ( l − 1 ) factor_{ij} = \frac {z^{(l)}_{ij}} {z^{(l)}_j} = \frac {w^{(l)}_{ij} a_i^{(l-1)}} {\sum_i w^{(l)}_{ij} a_i^{(l-1)}} factorij=zj(l)zij(l)=∑iwij(l)ai(l−1)wij(l)ai(l−1)
回到上边的例子:
R i ← j ( 5 , 6 ) = f a c t o r i j ( 5 , 6 ) ⋅ R j ( 6 ) = w i j ( 6 ) a i ( 5 ) ∑ i w i j ( 6 ) a i ( 5 ) ⋅ R j ( 6 ) R^{(5, 6)}_{i \leftarrow j} = factor_{ij}^{(5,6)} \cdot R^{(6)}_j =\frac {w^{(6)}_{ij} a_i^{(5)}} {\sum_i w^{(6)}_{ij} a_i^{(5)}} \cdot R^{(6)}_j Ri←j(5,6)=factorij(5,6)⋅Rj(6)=∑iwij(6)ai(5)wij(6)ai(5)⋅Rj(6)
写成更一般化的形式:
R i ← j ( l − 1 , l ) = f a c t o r i j ( l − 1 , l ) ⋅ R j ( l ) = w i j ( l ) a i ( l − 1 ) ∑ i ′ w i ′ j ( l ) a i ′ ( l − 1 ) ⋅ R j ( l ) R^{(l-1, l)}_{i \leftarrow j} = factor_{ij}^{(l-1, l)} \cdot R^{(l)}_j =\frac {w^{(l)}_{ij} a_i^{(l-1)}} {\sum_{i'} w^{(l)}_{i'j} a_{i'}^{(l-1)}} \cdot R^{(l)}_j Ri←j(l−1,l)=factorij(l−1,l)⋅Rj(l)=∑i′wi′j(l)ai′(l−1)wij(l)ai(l−1)⋅Rj(l)
将 l − 1 l-1 l−1替换成 l l l, l l l替换成 l + 1 l+1 l+1,并按下标 j j j求和,即得第 i i i个单元的Relevance:
R i ( l ) = ∑ j R i ← j ( l , l + 1 ) = ∑ j w i j ( l + 1 ) a i ( l ) ∑ i ′ w i ′ j ( l + 1 ) a i ′ ( l ) ⋅ R j ( l + 1 ) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ( 1 ) R^{(l)}_{i} =\sum_j R^{(l, l+1)}_{i \leftarrow j}=\sum_j \frac {w^{(l+1)}_{ij} a_i^{(l)}} {\sum_{i'} w^{(l+1)}_{i'j} a_{i'}^{(l)}} \cdot R^{(l+1)}_j..............................(1) Ri(l)=j∑Ri←j(l,l+1)=j∑∑i′wi′j(l+1)ai′(l)wij(l+1)ai(l)⋅Rj(l+1)..............................(1)
上边即为通用的LRP(Layer-Wise Relevance Propagation)框架的基本公式(z-rule), 注意到这个framework的公式中没有求导运算,所以它的适用范围很广, 并不需要分析对象可导。在LRP框架下派生出了多种规则,比如 α β − r u l e , z + \alpha \beta-rule, z^+ αβ−rule,z+,我们接下来再讲讲 α β − r u l e \alpha \beta-rule αβ−rule。
在很多情况下,我们需要知道Relevance的符号,即需要heatmap能够标识出input中哪些features对预测结果起促进作用,哪些起抑制作用。于是 α β − r u l e \alpha \beta-rule αβ−rule应运而生了, 我们首先要做的是将上边的(1)式进行拆解,重新写为大于0和小于0的两部分加权和的形式, α \alpha α即为大于0部分的权值, β \beta β为小于0部分的权值:
R i ( l ) = α ( R i ( l ) ) + + β ( R i ( l ) ) − = [ α ( z i j ( l ) ) + ( z j ( l ) ) + + β ( z i j ( l ) ) − ( z j ( l ) ) − ] ⋅ R j ( l + 1 ) R^{(l)}_{i} =\alpha (R^{(l)}_{i})^+ + \beta (R^{(l)}_{i})^-=[\alpha \frac {(z^{(l)}_{ij})^+} {(z^{(l)}_j)^+} + \beta \frac {(z^{(l)}_{ij})^-} {(z^{(l)}_j)^-}] \cdot R^{(l+1)}_j Ri(l)=α(Ri(l))++β(Ri(l))−=[α(zj(l))+(zij(l))++β(zj(l))−(zij(l))−]⋅Rj(l+1)
通过调整 α β \alpha \beta αβ的值,我们可以灵活的指定正负Relevance显示的权重。比较常用的参数配置是 α = 1 , β = 0 \alpha=1,\beta=0 α=1,β=0此时heatmap中只显示正Relevance( z + − r u l e / / L R P − α 1 β 0 z^+-rule // LRP-α_1 \beta_0 z+−rule//LRP−α1β0)。
2.2.2 Deep Taylor Decomposition
除了这种方法之外,还有其它decomposition方法吗? 答案就是Deep Taylor Decomposition, 这其实是可以将Taylor Decomposition和LRP结合起来的一种方法,主要动机是使用逐层拆解的方式解决Deep network函数过于复杂,整体求导难的问题。如果我们把任意一个神经元看做是一个函数 f ( x ) f(x) f(x),其相邻的低层每个神经元的输出看做是函数 f ( x ) f(x) f(x)的输入向量即 x x x, 根据 T a y l o r Taylor Taylor公式:
f ( x ) = f ( x ~ ) + f ′ ( x ~ ) ( x − x ~ ) + ϵ ≈ f ( x ~ ) + f ′ ( x ~ ) ( x − x ~ ) f(x)= f(\tilde{x}) + f'(\tilde{x})(x-\tilde{x}) + \epsilon≈f(\tilde{x}) + f'(\tilde{x})(x-\tilde{x}) f(x)=f(x~)+f′(x~)(x−x~)+ϵ≈f(x~)+f′(x~)(x−x~)
其中, ϵ \epsilon ϵ 为高阶项。注意其中的x为多维的输入向量,那么f(x)其实就是一个多元函数,其在某一点上的导数值就为各个分量上的偏导值之和,因此我们就可以将Relevance从最后一层的 R f R_f Rf往上逐层分解。以最后一层为例上式可以写成如下形式:
R f = f ( x ~ ) + ∑ k ∂ f ( x ~ ) ∂ x k ( x k − x ~ k ) R_f=f(\tilde{x}) +\sum_k \frac{\partial f(\tilde{x})}{\partial x_k}(x_k - \tilde{x}_k) Rf=f(x~)+k∑∂xk∂f(x~)(xk−x~k)
令 R a = f ( x ~ ) , R d = ∑ k ∂ f ( x ~ ) ∂ x k ( x k − x ~ k ) R_a = f(\tilde{x}), R_d=\sum_k \frac{\partial f(\tilde{x})}{\partial x_k}(x_k - \tilde{x}_k) Ra=f(x~),Rd=∑k∂xk∂f(x~)(xk−x~k)有:
R f = R a ( 6 ) + R d ( 6 ) R_f=R^{(6)}_a + R^{(6)}_d Rf=Ra(6)+Rd(6)
显然 R d R_d Rd可以自然的分解为低层每个节点的relevance之和,即:
R d ( 6 ) = ∑ k R d k ( 5 ) R^{(6)}_d =\sum_k R^{(5)}_{dk} Rd(6)=k∑Rdk(5)
因此, 我们可以很自然的得出低层(第 5 5 5层)节点的relevance:
R k ( 5 ) = R a k ( 5 ) + R d k ( 5 ) = R a k ( 5 ) + ∂ f ( x ~ ) ∂ x k ( x k − x ~ k ) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ( 2 ) R^{(5)}_{k} =R^{(5)}_{ak} + R^{(5)}_{dk} =R^{(5)}_{ak} + \frac{\partial f(\tilde{x})}{\partial x_k}(x_k - \tilde{x}_k) ..............................(2) Rk(5)=Rak(5)+Rdk(5)=Rak(5)+∂xk∂f(x~)(xk−x~k)..............................(2)
看到这里,大家会想, R d R_d Rd的问题是解决了,那前边这个 R a R_a Ra怎么分解? 或者这个 R a = f ( x ~ ) = 0 R_a=f(\tilde{x}) =0 Ra=f(x~)=0就更好了,这样我们只需要计算导数和 x x x变化值的乘积即可。这里的关键在于,我需要找出这样的一个特殊的点 x ~ \tilde{x} x~, 即函数的0点。这里我们先把 f ( x ~ ) f(\tilde{x}) f(x~)展开, W的下标表示高层的神经元的序号,由于最后一层只有一个神经元,所以这里为1:
f ( x ~ ) = σ ( W 1 ( 6 ) x ~ ( 5 ) + b ( 6 ) ) f(\tilde{x})=\sigma(\boldsymbol{W^{(6)}_1\tilde{x}}^{(5)}+b^{(6)}) f(x~)=σ(W1(6)x~(5)+b(6))
假设网络的激活函数为Relu,则有:
f ( x ~ ) = m a x ( W 1 ( 6 ) x ~ ( 5 ) + b ( 6 ) , 0 ) f(\tilde{x})=max(\boldsymbol{W^{(6)}_1\tilde{x}}^{(5)}+b^{(6)}, 0) f(x~)=max(W1(6)x~(5)+b(6),0)
要找到0点,本质上就等于解线性方程组:
W 1 ( 6 ) x ~ ( 5 ) + b ( 6 ) = 0 \boldsymbol{W^{(6)}_1\tilde{x}}^{(5)}+b^{(6)}= 0 W1(6)x~(5)+b(6)=0
显然,这个方程的解集是一个超平面。我们可以来看一个二维的例子:
假设 W = [ 1 , − 1 ] , x ~ = [ x , y ] , b = − 1 W=[1,-1], \tilde{x} = [x, y], b = -1 W=[1,−1],x~=[x,y],b=−1, 我们有: x − y − 1 = 0 x-y-1 = 0 x−y−1=0
上图左侧为平面 z = x − y − 1 z=x-y-1 z=x−y−1, 右侧为其与平面 z = 0 z=0 z=0的交集,即方程的解集(超平面): x − y − 1 = 0 x-y-1=0 x−y−1=0
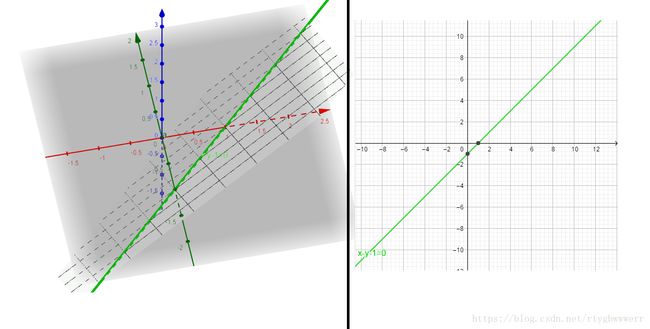
显然,在上边的情形下, x ~ \tilde{x} x~ 将有无数个,该取哪一个呢? 我们先假设从样本点 x x x开始,沿方向v按步长t开始搜索(注意下标 k k k表示向量的一个分量,粗体的符号均为向量)结合 R a k = 0 R_{ak}=0 Rak=0的假设,我们可得到下边的约束方程组:
{ x ~ = x − t v , R a = f ( x ~ ) = W 1 ( 6 ) x ~ + b ( 6 ) = 0 \begin{cases} \boldsymbol{\tilde{x}} = \boldsymbol{x} - t \boldsymbol{v} , \\ R_{a}=f(\tilde{x})=\boldsymbol{W_1^{(6)}\tilde{x}}+b^{(6)}=0 \\ \end{cases} {x~=x−tv,Ra=f(x~)=W1(6)x~+b(6)=0
将上边的第一个约束代入第二个:
W 1 ( 6 ) ( x − t v ) + b ( 6 ) = 0 \boldsymbol{W_1^{(6)}}(\boldsymbol{x} - t \boldsymbol{v})+b^{(6)}=0 W1(6)(x−tv)+b(6)=0
即:
W 1 ( 6 ) x + b ( 6 ) = W 1 ( 6 ) v t \boldsymbol{W_1^{(6)}} \boldsymbol{x}+b^{(6)}=\boldsymbol{W_1^{(6)}} \boldsymbol{v} t W1(6)x+b(6)=W1(6)vt
可以求出 t = W 1 ( 6 ) x + b ( 6 ) W 1 ( 6 ) v t = \frac{\boldsymbol{W_1^{(6)}} \boldsymbol{x}+b^{(6)}}{\boldsymbol{W_1^{(6)}} \boldsymbol{v} } t=W1(6)vW1(6)x+b(6)
我们先把 σ = R e l u , R a k = 0 \sigma=Relu,R_{ak}=0 σ=Relu,Rak=0的假设带入(2):
R k ( 5 ) = ∂ f ( x ~ ) ∂ x k ( x k − x ~ k ) = w k ( 6 ) ( x k − x ~ k ) R^{(5)}_{k} =\frac{\partial f(\tilde{x})}{\partial x_k}(x_k - \tilde{x}_k)= w^{(6)}_k (x_k - \tilde{x}_k) Rk(5)=∂xk∂f(x~)(xk−x~k)=wk(6)(xk−x~k)
将上边求出的t(是一个标量值)及 x ~ k = x k − t v k \tilde{x}_k=x_k - t v_k x~k=xk−tvk带入上式,得:
R k ( 5 ) = w k ( 6 ) ( x k − x ~ k ) = w k ( 6 ) v k ⋅ t = w k ( 6 ) v k ⋅ W 1 ( 6 ) x + b ( 6 ) W 1 ( 6 ) v R^{(5)}_{k} =w^{(6)}_k (x_k - \tilde{x}_k)=w^{(6)}_k v_k \cdot t=w^{(6)}_k v_k \cdot \frac{\boldsymbol{W_1^{(6)}} \boldsymbol{x}+b^{(6)}}{\boldsymbol{W_1^{(6)}} \boldsymbol{v} } Rk(5)=wk(6)(xk−x~k)=wk(6)vk⋅t=wk(6)vk⋅W1(6)vW1(6)x+b(6)
即为:
R k ( 5 ) = w k ( 6 ) v k ∑ k w k 1 ( 6 ) v k 1 ⋅ ( W 1 ( 6 ) x + b ( 6 ) ) R^{(5)}_{k} = \frac{w^{(6)}_k v_k}{\sum_k w_{k1}^{(6)} v_{k1}} \cdot (\boldsymbol{W_1^{(6)}} \boldsymbol{x}+b^{(6)}) Rk(5)=∑kwk1(6)vk1wk(6)vk⋅(W1(6)x+b(6))
按上边的假设,所有的神经元激活函数都是Relu, 所以对最后一层一样有:
f ( x ) = R 1 ( 6 ) = W 1 ( 6 ) x + b ( 6 ) f(x) = R^{(6)}_1 = \boldsymbol{W_1^{(6)}} \boldsymbol{x}+b^{(6)} f(x)=R1(6)=W1(6)x+b(6)
带入上式得:
R k ( 5 ) = w k ( 6 ) v k ∑ k w k 1 ( 6 ) v k 1 ⋅ R 1 ( 6 ) R^{(5)}_{k} = \frac{w^{(6)}_k v_k}{\sum_k w_{k1}^{(6)} v_{k1}} \cdot R^{(6)}_1 Rk(5)=∑kwk1(6)vk1wk(6)vk⋅R1(6)
使用 i i i表示低层网络神经元的下标, j j j表示高层网络神经元的下标, l l l表示层序号,则上式可以写成更一般的形式:
R i ← j ( l , l + 1 ) = w i j ( l + 1 ) v i j ∑ i ′ w i ′ j ( l + 1 ) v i ′ j ⋅ R j ( l + 1 ) R^{(l, l+1)}_{i \leftarrow j} = \frac{w^{(l+1)}_{ij} v_{ij}}{\sum_{i'} w_{i'j}^{(l+1)} v_{i'j}} \cdot R^{(l+1)}_j Ri←j(l,l+1)=∑i′wi′j(l+1)vi′jwij(l+1)vij⋅Rj(l+1)
通过上式,我们可以算出单个链接上的Relevance,如果要求出 l l l层第 i i i个节点的Relevance总和,只需要将所有上层对应链接上的值相加即可:
R i ( l ) = ∑ j R i ← j ( l , l + 1 ) = ∑ j w i j ( l + 1 ) v i j ∑ i ′ w i ′ j ( l + 1 ) v i ′ j ⋅ R j ( l + 1 ) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ( 3 ) R^{(l)}_{i} = \sum_j R^{(l, l+1)}_{i \leftarrow j}= \sum_j \frac{w^{(l+1)}_{ij} v_{ij}}{\sum_{i'} w_{i'j}^{(l+1)} v_{i'j}} \cdot R^{(l+1)}_j..............................(3) Ri(l)=j∑Ri←j(l,l+1)=j∑∑i′wi′j(l+1)vi′jwij(l+1)vij⋅Rj(l+1)..............................(3)
接下来我们需要确定的就是搜索方向向量 v \boldsymbol{v} v。Taylor逼近中, 最后还有一个省略掉的高阶项 ϵ \epsilon ϵ, 它是随着 ∣ x − x ~ ∣ |x-\tilde{x}| ∣x−x~∣的增大而增大的,也即是说,我们找到的点应该尽可能的靠近 x x x, 这样才能保证逼近值的精度。所以一个直观的想法是,我们只要沿着函数的梯度方向进行搜索,就能找到一个最近的解, 按照Relu函数的定义,其梯度即为权值向量 W j \boldsymbol{W}_j Wj, 代入(3), 我们就得到了 w 2 − R u l e w^2-Rule w2−Rule的公式:
R i ( l ) = ∑ j ( w i j ( l + 1 ) ) 2 ∑ i ′ ( w i ′ j ( l + 1 ) ) 2 ⋅ R j ( l + 1 ) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ( 4 ) R^{(l)}_{i} = \sum_j \frac{(w^{(l+1)}_{ij} )^2}{\sum_{i'} (w_{i'j}^{(l+1)})^2 } \cdot R^{(l+1)}_j..............................(4) Ri(l)=j∑∑i′(wi′j(l+1))2(wij(l+1))2⋅Rj(l+1)..............................(4)
我们把(1)和(3)对比一下,可以看到出这两个式子长得非常相似,唯一的差别就是与w相乘的值,一个取的是神经元的激活值 a a a, 另一个是方向 v v v。两者之间是否有某种联系呢?其实(1)可以看做是 v = a v=a v=a的一种特殊情况,即沿着上层输出向量 x i x_i xi与原点连线方向移动(即在线段 ( 0 , x i ) (0, x_i) (0,xi)上搜索)。
3.如何评估
怎么评估visualization生成的heatmap质量呢?我们知道heatmap代表了输入x的重要程度,屏蔽掉 x x x中影响越大的点对分类函数 f ( x ) f(x) f(x)的输出带来的影响也越大。一种直观的想法是,我们通过对heatmap中的位置按重要程度降序排列并取前L个元素,得到一个序列 O = [ r 1 , r 2 , . . . , r L ] O=[r_1, r_2,...,r_L] O=[r1,r2,...,rL],依次对这些位置的数据点通过函数 g ( x , r k ) g(x, r_k) g(x,rk)进行扰动(比如屏蔽或替换等)

将得到一个 x x x的序列: X M o R F = [ x M o R F ( 1 ) , x M o R F ( 2 ) , . . . , x M o R F ( L ) ] X_{MoRF}=[x^{(1)}_{MoRF}, x^{(2)}_{MoRF}, ..., x^{(L)}_{MoRF}] XMoRF=[xMoRF(1),xMoRF(2),...,xMoRF(L)], 我们只需要计算替换前后f(x)值的变化即可:

其中 v a l u e = ⟨ ⟩ p ( x ) value = \langle \rangle _{p_(x)} value=⟨⟩p(x)表示按分布p(x)求期望,这里就是对所有测试样本求均值。需要注意的是,在NLP任务中,我们的扰动函数 g g g进行的操作为屏蔽,即将操作位置 r k r_k rk对应的字符替换为空字符(仍然占位),其对应embedding 向量为全0向量:
| 帮 | 我 | 来 | 一首 | 刘德华 | 的 | 歌 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
执行 g ( x , r 1 ) g(x, r_1) g(x,r1)后,结果为:
| [BLANK] | 我 | 来 | 一首 | 刘德华 | 的 | 歌 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
AOPC值越大,说明heatmap的质量越高。另外,L可以根据实际输入x的长度灵活选择,如果输入句子普遍较少,L可取1~3.
4. NLP中的应用
在NLP中我们有时需要对模型的预测进行分析,即判断哪些输入term对分类结果造成主要影响。如果是RNN,我们可以使用Attention的方式很方便的实现Visualization,但如果是CNN呢?有了LRP我们同样可以很方便的实现针对输入term的定性分析,需要注意的是,原始的keras实现代码是针对图像场景的,并没有考虑NLP中Embedding Layer不可导的问题,直接使用会报错,这里有修改后的版本。
整个框架的使用非常简单,首先参考github上的方法安装:
注意:model即待分析的keras模型,emb_model为基于gensim的词向量矩阵对象,inputs为输入文本的onehot矩阵
def make_drawer(shape, zoom_factor=1):
array = np.ndarray((shape[0] * zoom_factor, shape[1] * zoom_factor, 3), np.uint8)
#set background RGB
array[:, :, 0] = 255
array[:, :, 1] = 255
array[:, :, 2] = 255
image = Image.fromarray(array)
draw = ImageDraw.Draw(image)
return draw, image
def analysis_model(model, emb_model, inputs):
#visualization
import innvestigate
import innvestigate.utils.visualizations as ivis
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
#for Chinese char
id2w = dict([(v.index, k) for (k, v) in emb_model.wv.vocab.items()])
def postprocess(X):
X = X.copy()
X = X / np.max(np.abs(X), axis=-1).reshape([14, 1])
return X
def bk_proj(X):
return ivis.graymap(X)
def heatmap(X):
return ivis.heatmap(X)
def graymap(X):
return ivis.graymap(np.abs(X), input_is_postive_only=True)
# analyzer = innvestigate.create_analyzer("lrp.alpha_beta", model, alpha=1000, beta=999)
# analyzer = innvestigate.create_analyzer("lrp.epsilon", model)
# analyzer = innvestigate.create_analyzer("lrp.w_square", model)
# analyzer = innvestigate.create_analyzer("lrp.z_plus", model)
# analyzer = innvestigate.create_analyzer("lrp.sequential_preset_a", model)
# analyzer = innvestigate.create_analyzer("lrp.sequential_preset_b", model)
# analyzer = innvestigate.create_analyzer("lrp.sequential_preset_a_flat", model)
# analyzer = innvestigate.create_analyzer("lrp.z", model)
analyzer = innvestigate.create_analyzer("gradient", model)
# analyzer = innvestigate.create_analyzer("deconvnet", model)
# analyzer = innvestigate.create_analyzer("smoothgrad", model)
# analyzer = innvestigate.create_analyzer("guided_backprop", model)
# analyzer = innvestigate.create_analyzer("pattern.net", model)
# analyzer = innvestigate.create_analyzer("pattern.attribution", model)
# analyzer = innvestigate.create_analyzer("integrated_gradients", model)
# some analyzers require additional training. For those
analyzer.fit(inputs,
pattern_type='relu',
batch_size=256, verbose=1)
print(inputs.shape)
zoom_factor = 10
drawer, image = make_drawer(inputs.shape, zoom_factor)
img = analyzer.analyze(inputs)
print(np.sum(img, axis=1))
print(img)
img = postprocess(img)
print("after processing:")
print(img)
for i in range(inputs.shape[0]):
for j in range(inputs.shape[1]):
show_char = id2w[inputs[i, j]]
if show_char == END_C:
show_char = ''
r = img[i, j] if img[i, j] > 0 else 0
b = -img[i, j] if img[i, j] < 0 else 0
plt.text(j * zoom_factor, i * zoom_factor, s=show_char, fontdict=None, color=(r, 0, b))
plt.axis('off')
plt.imshow(image)
plt.savefig("result/analysis.png", dpi=800)
plt.show()
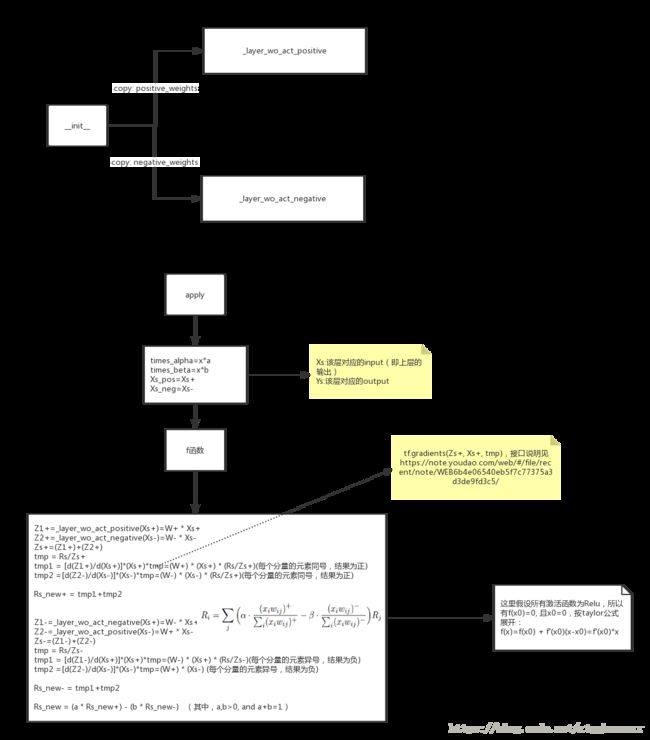
5. Keras 开源框架innvestigate分析
Innvestigate的框架结构如下:
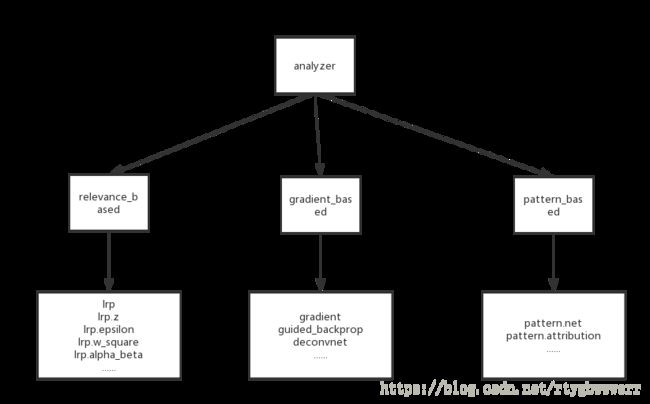
框架共实现了三类计算方法LRP-based,gradient-based(SA), Pattern-based,其基类存放于innvestigate/analyzer 目录下。其中LRP-based的方法实现放在relevance_based文件夹下,由analyzer和rule两部分组成,analyzer实现基本的框架流程,通过代理模式调用不同的rule实现各种计算规则。
由于框架代码结构相对简单,下边直接看图说话:
5.1 框架执行流程图

5.2 Z-Rule
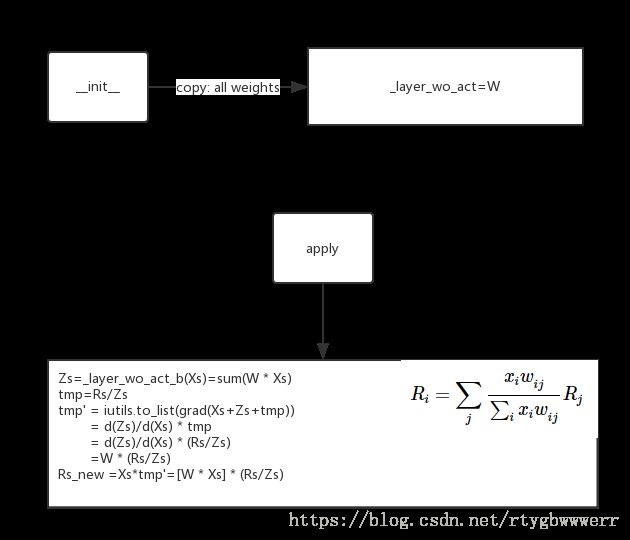
5.3 W 2 W^2 W2-rule

5.4 alpha-beta rule
5.5 Embedding pooling
由于Embedding layer不可导,在Relevance方向传播时会导致报错,为了解决这一问题,我们使用pooling的方式来计算Embedding layer输入的relevance(参见代码:innvestigate/layers.GradientWRT_Pooling【5】)
6.更进一步的思考
1.目前LRP的实现代码仅能在Relu为主要激活函数的模型结构下正常工作,遇到一些较为复杂的模型(比如Capsule)则只能通过SA的方法来进行分析,后边我们是否可以探索复杂模型上的实现方法?
参考文献:
【1】:Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps
【2】:On Pixel-Wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation
【3】:Explaining NonLinear Classification Decisions with Deep Taylor Decomposition
【4】:Evaluating the visualization of what a Deep Neural Network has learned
【5】:“What is Relevant in a Text Document?”:An Interpretable Machine Learning Approach
workshop官网:
[1] : http://www.heatmapping.org/
original代码来源于Keras Explanation Toolbox (LRP and other Methods)