SQL 按照两个字段去除列重复的数据,保留一行。
首先创建一个例子要用的表
CREATE TABLE [dbo].[as1]
(
[id] [nchar] (10) COLLATE Chinese_PRC_CI_AS NULL,
[a] [nchar] (10) COLLATE Chinese_PRC_CI_AS NULL,
[b] [nchar] (10) COLLATE Chinese_PRC_CI_AS NULL
) ON [PRIMARY]
GO
插入例子要用的数据
INSERT INTO dbo.as1
( id, a, b )
VALUES ( N'1', -- id - nchar(10)
N'2', -- a - nchar(10)
N'3' -- b - nchar(10)
),
( N'2', -- id - nchar(10)
N'2', -- a - nchar(10)
N'2' -- b - nchar(10)
),
( N'3', -- id - nchar(10)
N'2', -- a - nchar(10)
N'1' -- b - nchar(10)
),
( N'4', -- id - nchar(10)
N'2', -- a - nchar(10)
N'2' -- b - nchar(10)
),
( N'5', -- id - nchar(10)
N'1', -- a - nchar(10)
N'2' -- b - nchar(10)
)
-----------分割线---------
SELECT * FROM dbo.as1

--简单查看全部数据
GROUP BY a.a, a.b HAVING COUNT(*) > 1
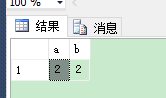
--查询出重复的数据
WHERE EXISTS
(
SELECT 1 FROM dbo.as1 WHERE a= T.a AND b= T.b
GROUP BY a, b HAVING COUNT(*) > 1
)
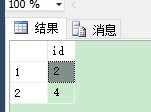
--查询出重复数据对应的ID号
SELECT min(id)AS 最小的ID FROM dbo.as1 GROUP BY a, b HAVING COUNT(*) > 1
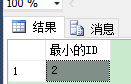
--下面是要删除的语句的查询
SELECT * FROM dbo.as1
WHERE id IN
(
SELECT id FROM dbo.as1 T
WHERE EXISTS
(
SELECT 1 FROM dbo.as1 WHERE a= T.a AND b= T.b
GROUP BY a, b HAVING COUNT(*) > 1
)
AND
T.id NOT IN
(
SELECT min(id) FROM dbo.as1 GROUP BY a, b HAVING COUNT(*) > 1
)
)
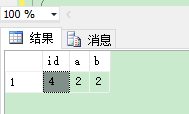
--删除语句
DELETE FROM dbo.as1
WHERE id IN
(
SELECT id FROM dbo.as1 T
WHERE EXISTS
(
SELECT 1 FROM dbo.as1 WHERE a= T.a AND b= T.b
GROUP BY a, b HAVING COUNT(*) > 1
)
AND
T.id NOT IN
(
SELECT min(id) FROM dbo.as1 GROUP BY a, b HAVING COUNT(*) > 1
)
)
--------------
DELETE FROM 表名
WHERE ID号 IN
(
SELECT ID号 FROM 表名 T
WHERE EXISTS
(
SELECT 1 FROM 表名 WHERE 字段1= T.字段1 AND 字段2= T.字段2
GROUP BY 字段1, 字段2 HAVING COUNT(*) > 1
)
AND
T. ID号 NOT IN
(
SELECT min( ID号) FROM 表名GROUP BY 字段1, 字段2 HAVING COUNT(*) > 1
)
)