解读Oracle执行计划(二)
解读Oracle执行计划(二)
一些典型的执行计划:AND-EQUAL(Index merge)
AND-EQUAL
这种方式需要查询条件里面包括所有索引列,然后取得每个索引中得到的rowid列表,然后对这些列表做merge join,过滤出相同的rowid后再去表中获取数据或者直接从索引中获得数据。and-equal有一些限制,比如它只对单列索引有效,只对非唯一索引有效,使用到的索引不能超过5个,查询条件只能是”=”。
在10g中,and_equal已经被废弃了,只能通过hint才能生效!
Can operate on 2 to 5 non-unique, single-column indexes with an equality condition on the indexed values. For colX = const each index produces a list of rowids which are guaranteed to be in rowid order, hence pre-sorted and ready for a merge join. rowids that survive the join are used to access the table.
and-equal支持操作2-5个非唯一单列索引,这些索引都有一个基于索引值的等值查询条件。 对于colX = “常量”, 每个索引都生成一个排好了顺序的rowid列表,可以直接进行合并连接。符合连接条件的rowid用来访问表取得结果数据。
示例:
SQL> create table emp_copy
2 as
3 select * from emp;
表已创建。
SQL> create table dept_copy
2 as
3 select * from dept;
表已创建。
SQL> create index idx_mgr on emp_copy(mgr);
索引已创建。
SQL> create index idx_deptno on emp_copy(deptno);
索引已创建。
执行如下SQL查询:
SQL> set timing on;
SQL> set autotrace on;
SQL> select /*+ and_equal(emp_copy idx_mgr idx_deptno) */ empno,job
2 from emp_copy
3 where mgr=7902 and deptno=20;
EMPNO JOB
---------- ------------------
7369 CLERK
已用时间: 00: 00: 00.10
执行计划
----------------------------------------------------------
Plan hash value: 623969103
------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 19 | 3 (0)| 00:00:01 |
|* 1 | TABLE ACCESS BY INDEX ROWID| EMP_COPY | 1 | 19 | 3 (0)| 00:00:01 |
| 2 | AND-EQUAL | | | | | |
|* 3 | INDEX RANGE SCAN | IDX_MGR | 2 | | 1 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | IDX_DEPTNO | 5 | | 1 (0)| 00:00:01 |
------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("MGR"=7902 AND "DEPTNO"=20)
3 - access("MGR"=7902)
4 - access("DEPTNO"=20)
统计信息
----------------------------------------------------------
1 recursive calls
0 db block gets
5 consistent gets
0 physical reads
0 redo size
619 bytes sent via SQL*Net to client
607 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
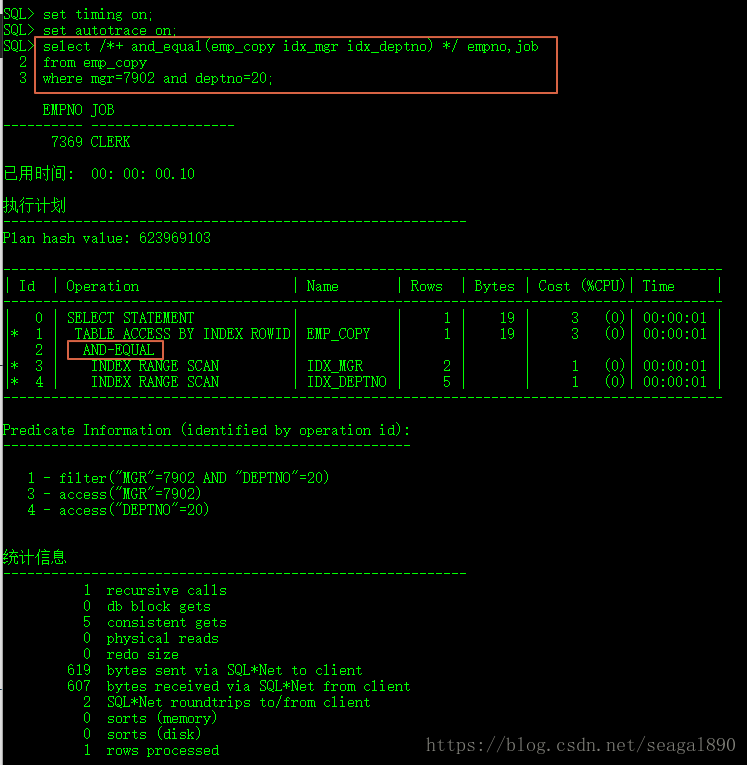
在此执行计划中是对索引IDX_MGR和IDX_DEPTNO的AND-EQUAL,AND-EQUAL在执行计划中对应的关键字就是AND-EQUAL。此执行计划的执行步骤:
1、先以驱动查询条件 access(“MGR”=7902) 去扫描索引IDX_MGR,此时的扫描结果记为结果集R1;
2、再以驱动查询条件 access(“DEPTNO”=20) 去扫描索引IDX_DEPTNO,此时的扫描结果记为结果集R2;
3、然后再以过滤条件 filter(“MGR”=7902 AND “DEPTNO”=20) 去找结果集R1和结果集R2中满足上述过滤查询条件的记录(其实就是找两个结果集中rowid值相同的记录)。
INDEX-JOIN
index join通过hash index join的方式实现了避免对表的访问。所有的数据都从索引中直接获得。它不受查询条件影响,可以是唯一索引,也可以是多列索引。但返回的列中必须全部包含在指定的索引列才有效。
Can be used to join any two indexes – no restrictions on number of columns, uniqueness, or predicates. Used to derive results without visiting the table at all. Each index is used to supply a (sub)set of its columns plus the relevant rowids. Oracle then performs a hash join on the two sets of data – using the rowid as the join column. Any data surviving the data is the answer set. Having joined two indexes by hash join, it is possible for Oracle to join a third, and so on until all the required columns have been join into the final result set
index_join可以连接任意两个索引(没有任何限制,如列数量,索引唯一性,以及谓词等),以实现完全不需要访问表就得到结果集的查询。每个索引都提供结果集的一个完整或部分列的集合以及对应的rowid。Oracle接着对这两个数据集进行散列连接-使用rowid作为连接条件。连接得到的结果就是所需的结果集。对Oracle来讲, 可以对两个索引做散列连接, 自然也可以对三个索引进行连接, 一直到所有出现在select list的列都已经取到,从而得到最后需要的结果集。
示例:
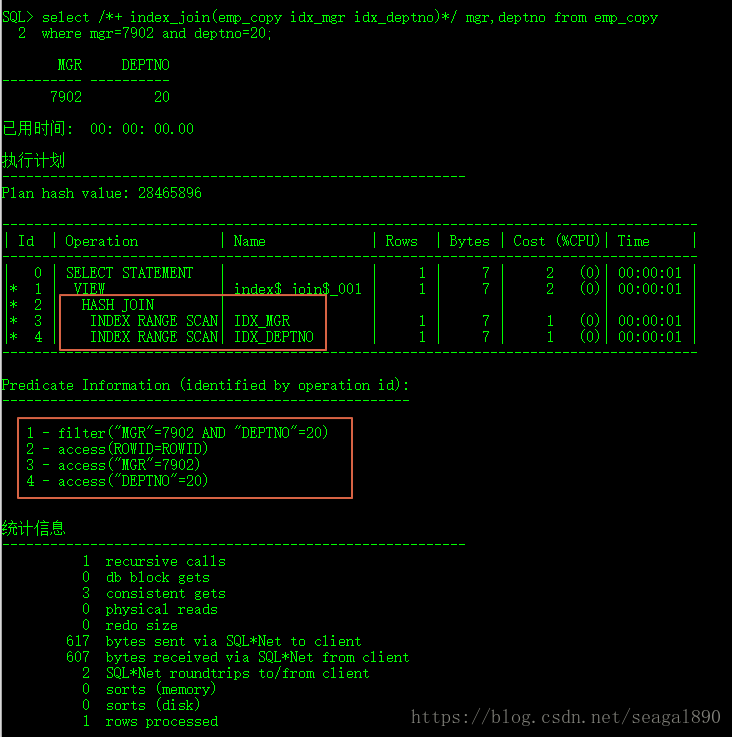
SQL> select /*+ index_join(emp_copy idx_mgr idx_deptno)*/ mgr,deptno from emp_copy
2 where mgr=7902 and deptno=20;
MGR DEPTNO
---------- ----------
7902 20
已用时间: 00: 00: 00.00
执行计划
----------------------------------------------------------
Plan hash value: 28465896
---------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 7 | 2 (0)| 00:00:01 |
|* 1 | VIEW | index$_join$_001 | 1 | 7 | 2 (0)| 00:00:01 |
|* 2 | HASH JOIN | | | | | |
|* 3 | INDEX RANGE SCAN| IDX_MGR | 1 | 7 | 1 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN| IDX_DEPTNO | 1 | 7 | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("MGR"=7902 AND "DEPTNO"=20)
2 - access(ROWID=ROWID)
3 - access("MGR"=7902)
4 - access("DEPTNO"=20)
统计信息
----------------------------------------------------------
1 recursive calls
0 db block gets
3 consistent gets
0 physical reads
0 redo size
617 bytes sent via SQL*Net to client
607 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
INDEX_COMBINE
index_combine最早是用在bitmap index上的,在9i开始Oracle默认可以使用在B-tree索引上,在10G上可以得验证,这是由_b_tree_bitmap_plans参数来控制的。Oracle将B-tree索引中获得的rowid信息通BITMAPCONVERSION FROM ROWIDS的步骤转换成bitmap进行匹配,然后匹配完成后通过BITMAP CONVERSION TO ROWIDS再转换出rowid获得数据或者回表获得数据。
Used for bitmap operators (although you can reference b-tree indexes in the hint to indicate to Oracle that the index is a candidate for ‘rowid conversion to bitmap’). Oracle acquires bitmaps from each index, and uses the AND, OR, NOT, or MERGE operators to produce a result bit string that can then be converted into rowids for visiting the table.
index_combine 主要用来处理bitmap操作(虽然,也可以在提示中引用B-Tree索引来强制Oracle将这个B-Tree索引作为“rowid conversion to bitmap”的一个候选项)。 Oracle会获取每个索引的bitmap,并使用AND/OR/NOT/MERGE 等位图操作来生成一个可转换成rowid的位串,以使用这些rowid来访问数据表。
(完)