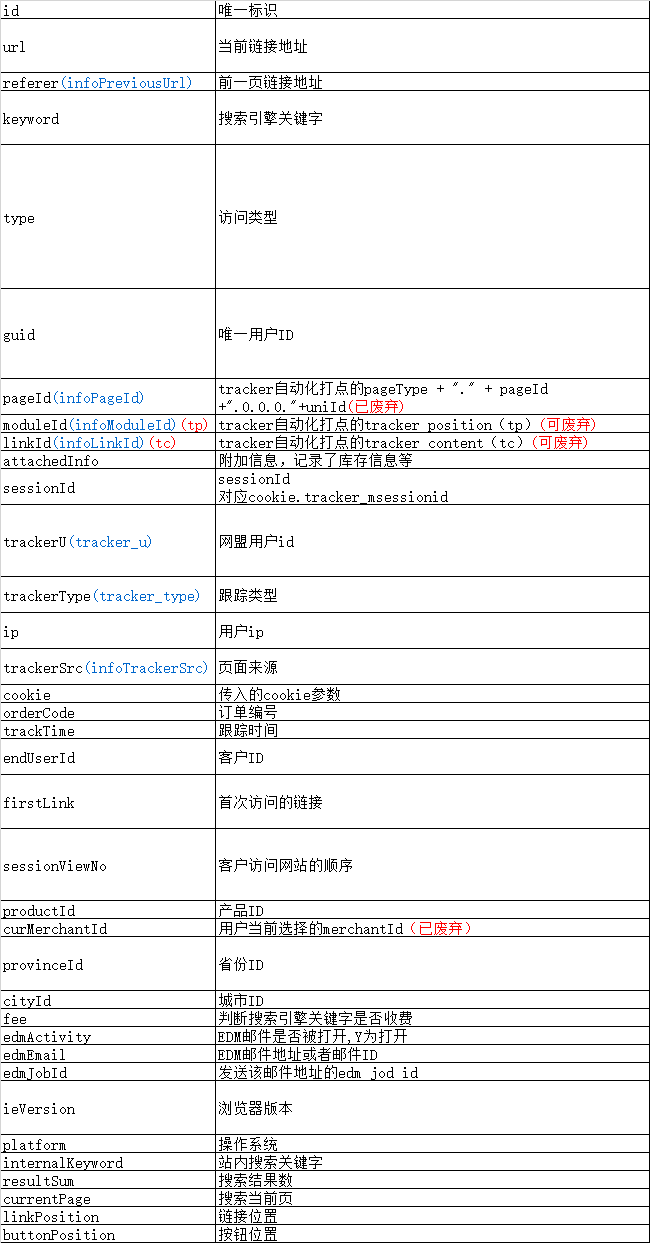
分析
- 数据源格式
121508281810000000 http://www.yhd.com/?union_ref=7&cp=0 3 PR4E9HWE38DMN4Z6HUG667SCJNZXMHSPJRER VFA5QRQ1N4UJNS9P6MH6HPA76SXZ737P 10977119545 124.65.159.122 unionKey:10977119545 2015-08-28 18:10:00 50116447 http://image.yihaodianimg.com/virtual-web_static/virtual_yhd_iframe_index_widthscreen.html?randid=2015828 6 1000 Mozilla/5.0 (Windows NT 6.1; rv:40.0) Gecko/20100101 Firefox/40.0 Win32 lunbo_tab_3 北京市 2 北京市 1 1 1 1 1440*900 1440756285639
Paste_Image.png
- 需求分析
现在每天中的每一个小时,都有一个日志文件,想要统计每天内每个时段的PV和UV(根据guid然后去重计数)。最后的结果形式:
| 日期 | 时间 | PV | UV | |
|---|---|---|---|---|
- 数据清洗
- 从日志文件中获取需要的字段id,url,guid,trackTime
- 时间字段trackTime的格式转换
- 数据分析后导出到MySQL
实现流程
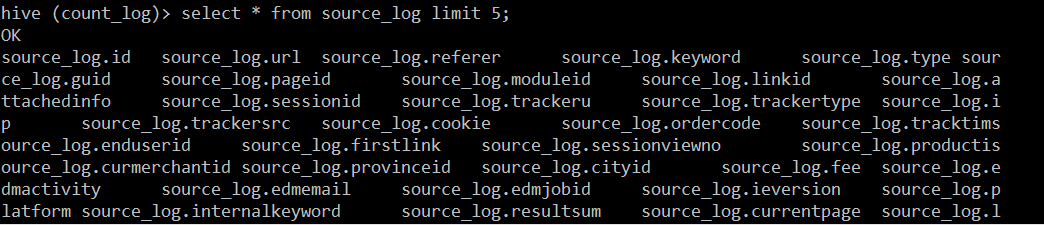
- 在Hive中建源表并导入日志数据
create database count_log;
use count_log;
create table source_log(
id string,
url string,
referer string,
keyword string,
type string,
guid string,
pageId string,
moduleId string,
linkId string,
attachedInfo string,
sessionId string,
trackerU string,
trackerType string,
ip string,
trackerSrc string,
cookie string,
orderCode string,
trackTime string,
endUserId string,
firstLink string,
sessionViewNo string,
productId string,
curMerchantId string,
provinceId string,
cityId string,
fee string,
edmActivity string,
edmEmail string,
edmJobId string,
ieVersion string,
platform string,
internalKeyword string,
resultSum string,
currentPage string,
linkPosition string,
buttonPosition string
)
row format delimited fields terminated by '\t'
stored as textfile;
load data local inpath '/opt/datas/2015082818' into table source_log;
load data local inpath '/opt/datas/2015082819' into table source_log;
hive16.png
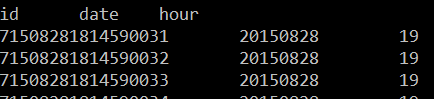
- 建一个清洗表用来存储转换后的时间字段
hive (count_log)> create table date_clear(
> id string,
> url string,
> guid string,
> date string,
> hour string
> )
> row format delimited fields terminated by '\t';
insert into table date_clear
hive (count_log)> insert into table date_clear
> select id,url,guid ,substring(trackTime,9,2) date,substring(trackTime,12,2) hour from source_log;
hive22.png
- 创建分区表(以日期和时间分区,方便实现每小时进行PV、UV统计)
- 方式一: 创建静态分区表
hive (count_log)> create table part1(
> id string,
> url string,
> guid string
> )
> partitioned by (date string,hour string)
> row format delimited fields terminated by '\t';
hive (count_log)> insert into table part1 partition (data='20150828',hour='18')
> select id,url,guid from date_clear where date;
hive (count_log)> insert into table part1 partition (date='20150828',hour='18')
> select id,url,guid from date_clear where date='28' and hour='18';

hive20.png
- 方式二:创建动态分区表(会自动的根据与分区列字段名相同的列进行分区)
使用动态分区表前,需要设置两个参数值
hive (count_log)> set hive.exec.dynamic.partition=true;
hive (count_log)> set hive.exec.dynamic.partition.mode=nonstrict;
hive (count_log)> create table part2(
> id string,
> url string,
> guid string
> )
> partitioned by (date string,hour string)
> row format delimited fields terminated by '\t';
hive (count_log)> insert into table part2 partition (date,hour)
> select * from date_clear;

hive21.png
- 实现统计PV和UV
PV统计
hive (count_log)> select date,hour,count(url) PV from part1 group by date,hour;

hive23.png
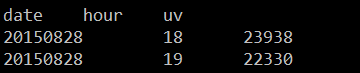
UV统计
hive (count_log)> select date,hour,count(distinct guid) uv from part1 group by date,hour;
hive24.png
- 在hive中保存PV数和UV数
hive (count_log)> create table if not exists result row format delimited fields terminated by '\t' as
> select date ,hour,count(url) PV ,count(distinct guid) UV from part1 group by date,hour;```

6. 利用sqoop把最后结果导出到MySQL


