性能篇系列—stream详解
Stream API
- Java 8集合中的Stream相当于高级版的Iterator
- Stream API通过Lambda表达式对集合进行各种非常便利高效的聚合操作,或者大批量数据操作
- Stream的聚合操作与数据库SQL的聚合操作sorted、filter、map等非常类似
- 在数据操作方面,Stream不仅可以通过串行的方式实现数据操作,还可以通过并行的方式处理大批量数据,提高处理效率
// java.util.Collection
default Stream stream() {
return StreamSupport.stream(spliterator(), false);
}
default Stream parallelStream() {
return StreamSupport.stream(spliterator(), true);
}
@Data
class Student {
private Integer height;
private String sex;
}
Map> map = Maps.newHashMap();
List list = Lists.newArrayList();
// 传统的迭代方式
for (Student student : list) {
if (student.getHeight() > 160) {
String sex = student.getSex();
if (!map.containsKey(sex)) {
map.put(sex, Lists.newArrayList());
}
map.get(sex).add(student);
}
}
// Stream API,串行实现
map = list.stream().filter((Student s) -> s.getHeight() > 160).collect(Collectors.groupingBy(Student::getSex));
// Stream API,并行实现
map = list.parallelStream().filter((Student s) -> s.getHeight() > 160).collect(Collectors.groupingBy(Student::getSex));
优化遍历
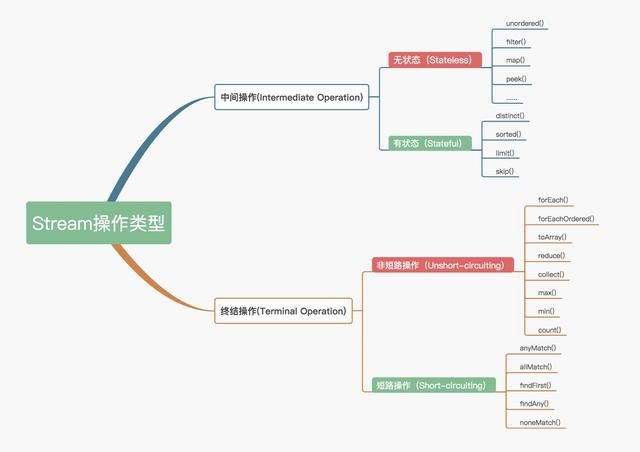
Stream操作分类
- 分为两大类:中间操作(Intermediate operations)和终结操作(Terminal operations)
- 中间操作只对操作进行了记录,即只会返回一个流,不会进行计算操作,而终结操作是实现了计算操作
- 中间操作又分为无状态(Stateless)操作和有状态(Stateful)操作
- 无状态操作:元素的处理不受之前元素的影响
- 有状态操作:该操作只有拿到所有元素之后才能继续下去
- 终结操作又分为短路(Short-circuiting)操作与非短路(UnShort-circuiting)操作
- 短路操作:遇到某些符合条件的元素就可以得到最终结果
- 非短路操作:必须处理完所有元素才能得到最终结果
- 通常会将中间操作称为懒操作,正是因为懒操作结合终结操作,数据源构成的处理管道(Pipeline),实现了Stream的高效
Stream源码实现
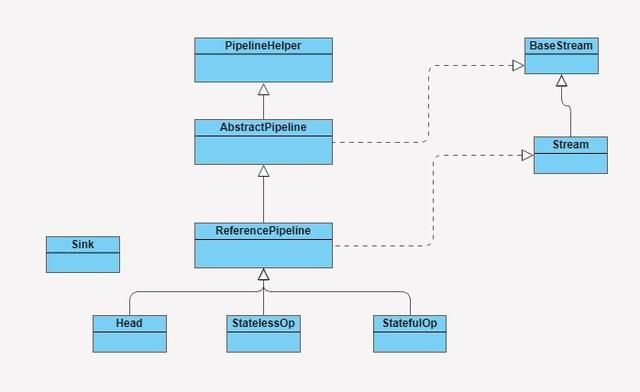
- BaseStream和Stream为最顶端的接口类
- BaseStream定义了流的基本接口方法,如spliterator、isParallel等
- Stream定义了流的常用操作方法,如map、filter等
- ReferencePipeline是一个结构类,通过定义内部类组装各种操作流
- 内部定义了Head、StatelessOp和StatefulOp三个内部类,实现了BaseStream和Stream的接口方法
- Sink接口定义每个Stream操作之间关系的协议,包含了begin、end、cancellationRequested、accept方法
- ReferencePipeline最终会将整个Stream流操作组装成一个调用链
- 而调用链上的每个Stream操作的上下文关系就是通过Sink接口来定义实现的
Stream操作叠加

- 一个Stream的各个操作是由处理管道组装的,并统一完成数据处理
- 在JDK中,每次的中断操作都会以使用阶段(Stage)命名
- 管道结构通常是由ReferencePipeline类实现的,ReferencePipeline包含Head、StatelessOp、StatefulOp三个内部类
- Head类主要用来定义数据源操作,初次调用.stream()时,会初次加载Head对象
- 接着加载中间操作,分为StatelessOp对象和StatefulOp对象
- 此时的Stage并没有执行,而是通过AbstractPipeline生成了中间操作的Stage链表
- 当调用终结操作时,会生成一个最终的Stage
- 通过这个Stage触发之前的中间操作,从最后一个Stage开始,递归产生一个Sink链
样例
List names = Arrays.asList("张三", "李四", "王老五", "李三", "刘老四", "王小二", "张四", "张五六七");
String maxLenStartWithZ = names.stream()
.filter(name -> name.startsWith("张"))
.mapToInt(String::length)
.max()
.toString();
names是ArrayList集合,names.stream会调用集合类基础接口Collection的stream方法
default Stream stream() {
return StreamSupport.stream(spliterator(), false);
}
Collection.stream方法会调用StreamSupport.stream方法,方法中初始化了一个ReferencePipeline的Head内部类对象
public static Stream stream(Spliterator spliterator, boolean parallel) {
Objects.requireNonNull(spliterator);
return new ReferencePipeline.Head<>(spliterator,
StreamOpFlag.fromCharacteristics(spliterator),
parallel);
}
调用filter和map,两者都是无状态的中间操作,因此并没有执行任何操作,只是分别创建了一个Stage来标识用户的每一次操作
通常情况下,Stream的操作需要一个回调函数,所以一个完整的Stage是由数据来源、操作、回调函数组成的三元组表示
@Override
public final Stream filter(Predicate predicate) {
Objects.requireNonNull(predicate);
return new StatelessOp(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SIZED) {
@Override
Sink opWrapSink(int flags, Sink sink) {
return new Sink.ChainedReference(sink) {
@Override
public void begin(long size) {
downstream.begin(-1);
}
@Override
public void accept(P_OUT u) {
if (predicate.test(u))
downstream.accept(u);
}
};
}
};
}
@Override
@SuppressWarnings("unchecked")
public final Stream map(Function mapper) {
Objects.requireNonNull(mapper);
return new StatelessOp(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
@Override
Sink opWrapSink(int flags, Sink sink) {
return new Sink.ChainedReference(sink) {
@Override
public void accept(P_OUT u) {
downstream.accept(mapper.apply(u));
}
};
}
};
}
new StatelessOp会调用父类AbstractPipeline的构造函数,该构造函数会将前后的Stage联系起来,生成一个Stage链表
AbstractPipeline(AbstractPipeline previousStage, int opFlags) {
if (previousStage.linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
previousStage.linkedOrConsumed = true;
previousStage.nextStage = this; // 将当前的Stage的next指针指向之前的Stage
this.previousStage = previousStage; // 赋值当前Stage当全局变量previousStage
this.sourceOrOpFlags = opFlags & StreamOpFlag.OP_MASK;
this.combinedFlags = StreamOpFlag.combineOpFlags(opFlags, previousStage.combinedFlags);
this.sourceStage = previousStage.sourceStage;
if (opIsStateful())
sourceStage.sourceAnyStateful = true;
this.depth = previousStage.depth + 1;
}
创建Stage时,会包含opWrapSink方法,该方法把一个操作的具体实现封装在Sink类中,Sink采用处理->转发的模式来叠加操作
调用max,会调用ReferencePipeline的max方法
由于max是终结操作,会创建一个TerminalOp操作,同时创建一个ReducingSink,并且将操作封装在Sink类中
@Override
public final Optional max(Comparator comparator) {
return reduce(BinaryOperator.maxBy(comparator));
}
最后调用AbstractPipeline的wrapSink方法,生成一个Sink链表,Sink链表中的每一个Sink都封装了一个操作的具体实现
final Sink wrapSink(Sink sink) {
Objects.requireNonNull(sink);
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink) sink;
}
当Sink链表生成完成后,Stream开始执行,通过Spliterator迭代集合,执行Sink链表中的具体操作
@Override
final void copyInto(Sink wrappedSink, Spliterator spliterator) {
Objects.requireNonNull(wrappedSink);
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
wrappedSink.begin(spliterator.getExactSizeIfKnown());
spliterator.forEachRemaining(wrappedSink);
wrappedSink.end();
}
else {
copyIntoWithCancel(wrappedSink, spliterator);
}
}
- java 8中的forEachRemaining会迭代集合
- 每迭代一次,都会执行一次filter操作,通过后就会触发map操作,然后将结果放入到临时数组object中,再进行下一次迭代
- 完成中间操作后,最后触发终结操作max
Stream并行处理
List names = Arrays.asList("张三", "李四", "王老五", "李三", "刘老四", "王小二", "张四", "张五六七");
String maxLenStartWithZ = names.stream()
.parallel()
.filter(name -> name.startsWith("张"))
.mapToInt(String::length)
.max()
.toString();
Stream的并行处理在执行终结操作之前,跟串行处理的实现是一样的,在调用终结方法之后,会调用TerminalOp.evaluateParallel
final R evaluate(TerminalOp terminalOp) {
assert getOutputShape() == terminalOp.inputShape();
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
}
- 并行处理指的是Stream结合了ForkJoin框架,对Stream处理进行了分片,Spliterator.estimateSize会估算出分片的数据量
- 通过预估的数据量获取最小处理单元的阈值,如果当前分片大小大于最小处理单元的阈值,就继续切分集合
- 每个分片都将会生成一个Sink链表,当所有分片操作完成后,ForkJoin框架将会合并分片任何结果集
合理使用Stream
- 在循环迭代次数较少的情况下,常规的迭代方式性能反而更好
- 在单核CPU服务器配置环境中,也是常规迭代方式更有优势
- 在大数据循环迭代中,如果服务器是多核CPU的情况,采用Stream的并行迭代优势明显
小结
- Stream将整个操作分解成了链式结构,不仅简化了遍历操作,还为实现并行计算奠定了基础
- Stream将遍历元素的操作和对元素的计算分为中间操作和终结操作
- 中间操作又根据元素之间状态有无干扰分为有状态操作和无状态操作,实现了链式结构中的不同阶段
- 串行处理
- Stream在执行中间操作时,并不会做实际的数据操作处理,而是将这些中间操作串联起来,最终由终结操作触发
- 生成一个数据处理链表,通过Java 8的Spliterator迭代器进行数据处理
- 并行处理
- 对中间操作的处理跟串行处理的方式是一样的,但在终结操作中,Stream将结合ForkJoin框架对集合进行切片处理
我是小架,我们下篇文章再见!