浅显易懂入门大数据系列:三、Zookeeper(超详细)
文章目录
- 一、Zookeeper在Hadoop生态圈的位置
- 分布式环境下常见的问题
- 二、Zookeeper的概念及特点
- Zookeeper的概念
- Zookeeper的特点
- Zookeeper的相关名词解释
- 三、Zookeeper的常用应用场景
- 四、配套教程详解
- 配套教程六之Zookeeper集群的安装与配置
- 五、常见错误总结
- 文章总览
前面的过程已经学习完了Hadoop的三大组件了,那么就可以去学习新的东西了,原本是应该学习HBase的。但是,因为 HBase严重依赖Zookeeper组件,所以,我们先简单将Zookeeper总结完,再学习HBase。
一、Zookeeper在Hadoop生态圈的位置
分布式环境下常见的问题
- 集群的管理问题,如何检测各个节点的生命状态
- 如何实现分布式锁
- 如何统一管理集群的配置文件
- 集群中某个节点的信息更新如何同步到整个集群的机器
- 集群内部的选举问题如何实现
- 抢占资源的时候,容易出现死锁和活锁,当处于活锁时每个线程都抢不到资源,会造成CPU的耗费,如何减少消耗
了解完分布式环境下所面临的问题后,其实我们接下来所要介绍的组件,就可以很轻松地来解决这些情况。我们继续来看一下什么是Zookeeper,Zookeeper的英文意思是动物管理员。Zookeeper在Hadoop生态圈里面,是处于一个分布式协调的服务,请看下面Hadoop生态圈的图:
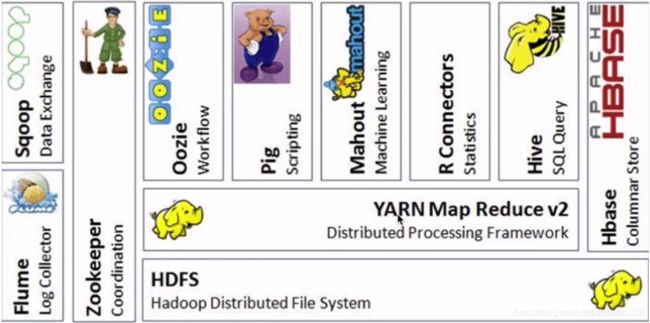
Hadoop生态圈中包含了很多组件,一眼望去,几乎所有组件的头像都是动物,唯独这个Zookeeper,是一个人的形象。我们都知道,我们人是要比动物高级的,其实也可以说明一个问题,我们的Zookeeper其实在大数据环境中,是一个非常重要的角色,主要体现在可以协调我们的其他组件。
二、Zookeeper的概念及特点
Zookeeper的概念
什么是Zookeeper?其实可以用一句简单的话来总结:Zookeeper是一个长得像Linux系统,但是每个目录又是可以存放内容的小型数据库。Zookeeper的每个目录,其实是称为我们Zookeeper里面的节点。操作起Zookeeper,其实就像在操作Linux系统一样。每个节点,又可以存放内容,比如说,可以简单存一下HBase(分布式列式数据库,数据主要存放在HDFS上)与HDFS的路由信息等。
Zookeeper的特点
部署Zookeeper的时候是要单独部署、单独配置,但是多个Zookeeper也将会组成一个集群。整个集群对外展示的是一个完整统一的视图,比如我们去操作Zookeeper集群,只需要对其中一台操作即可,其会同步到整个集群。
Zookeeper集群往往是部署奇数台,这是由于其内部选举机制所限制的。
Zookeeper的相关名词解释
节点:即目录,目录里面可以存放内容,各种应用场景,与节点的特性密切相关。
节点的特性有两种维度,第一维度为是持久还是临时,另一维度为是否有序。组合成四种类型:
1、临时节点(EPHEMERAL):创建者超时连接或者失去连接时,节点会被删除
2、持久节点(PERSISTENT):节点创建后会被持久化,客户端与Zookeeper断开连接后,该节点依旧存在
3、临时有序节点(EPHEMERAL_SEQUENTIAL)与持久有序节点(PERSISTENT_SEQUENTIAL)
创建的节点名称后会自动添加序号,如节点名称为"node",自动添加为"node1",顺序添加为"node2",以此类似,序号不断添加。
watcher机制:我们都知道Zookeeper是一个分布式协调服务,那么是怎么协调的呢?其实Zookeeper自己本身有一个watcher机制,监控着我们的节点变化的,就像是我们人的眼睛,可以监控着你的大数据集群里面哪些动物(服务器)出问题了,出了问题又会怎么操作,这些都离不开Zookeeper的watcher机制。
三、Zookeeper的常用应用场景
1、配置文件的同步:当集群里面,往往很多台服务器都使用相同的配置,如果突然配置文件里面的配置有改变,那么需要去修改每一台服务器的配置,这个时候就非常地麻烦,如果有了Zookeeper,那么我们可以在Zookeeper里的一个节点上存放好配置文件,因为我们的Zookeeper拥有监控机制,所以,当一台服务器的节点发生变化的时候,会被Zookeeper监控到,然后将改变结果,同步到Zookeeper集群,即同步到其他服务器。
2、分布式锁实现:每个用户都去Zookeeper里面创建临时序列节点,创建的节点是有序的,而且是临时的。我们可以让最小的有序节点来获取分布式锁,当获得锁的用户执行完程序,则删除其对应的节点,然后其他节点就是最小节点了,此时执行其他节点,以此类型进行下去,达到分布式锁的作用…
3、各个组件的HA(High Availability:高可用性)的实现:比如说,我们前面的HDFS集群,master节点上有一个Namenode进程,其余slaves节点分别有一个Datanode进程,当Namenode进程挂掉之后,整一个集群就挂了,这在大数据场景里面是不允许的。此时就可以用上我们的Zookeeper,监控集群的状态,比如说部署两个Namenode,其中一个是活跃状态,一个是备用状态,当活跃的Namenode服务器挂掉后,Zookeeper会监控到情况,并自动地切换备用状态Namenode会活跃状态。
四、配套教程详解
配套教程六之Zookeeper集群的安装与配置
教程:Zookeeper集群的安装与配置
此教程主要有两个步骤:
一、解压、配置Zookeeper
首先需要进入Zookeeper/conf路径下,将样本配置文件复制一份出来,当然更改名字也可以。配置主要配置两个东西,即datadir目录和log目录,一个是存放数据的,一个是存放日志的。配置好之后 ,教程里是先配置好环境变量就启动了,环境变量在前面已经说过了,启动后可以看到Zookeeper的主进程,但目前,Zookeeper是单节点的,不是集群的,下面我们来进行集群的配置。
1、给集群添加关系
我们继续编辑Zookeeper的配置文件,在里面添加服务器之间的关系,我们现在的情况是master、slave1、slave2,一共三台服务器,我们都准备安装Zookeeper,现在分配角色,比如说例子为:
server.0=hadoop-master:8880:7770
server.1=hadoop-slave1:8881:7771
server.2=hadoop-slave2:8882:7772
server.0,0表示此机器的机器标识符,hadoop-master为自己的集群的主机名,然后主机名后面是加上了两个端口,一个8880,一个是7770,前者是用来集群通讯的,后者是用来选举使用的,此端口号可以改变,但不可以冲突。所以,此处的配置是master为标识0,slave1为标识1,slave2为标识2,在后面我们还会用到此标识符。
2、加上标识符
在前面配置的datadir文件夹里面新建一个文件,叫myid,然后在里面添加上自己的标识符,比如说,master的为0。
二、同步Zookeeper到slavas节点并修改配置
修改好后,就可以同步master上的Zookeeper文件夹到从节点上了。同步完后,记得要修改各自的标识符,关系不需要改变,因为大家都是一样的,但myid记得要改。
同步后之后,就可以启动各自的Zookeeper了,启动后查看自己各自的状态,会发现其中一个为leader、两个为follower。
五、常见错误总结
1、很多初学者在配置Zookeeper集群关系的时候,经常忘记添加域名后面的两个端口号。
2、在Docker上安装Zookeeper,有时会没那么稳定,这跟资源使用情况也有关系,注意留意报错信息。
3、server.0的0需要与myid对应上,不对应上会报错。
文章总览
一、Zookeeper在Hadoop生态圈的位置
二、Zookeeper的概念及特点
Zookeeper的概念
Zookeeper的特点
Zookeeper的相关名词解释
三、Zookeeper的常用应用场景
四、配套教程详解
配套教程六之Zookeeper集群的安装与配置
五、常见错误总结
文章总览
后期更精彩
Zookeeper客户端实操?
Zookeeper的选举机制原理?
通过实操观察四种节点的特点?
通过实操理解Zookeeper三大应用场景?
通过实操实现HDFS的HA配置等等?
因为此文章仅根据个人了解,用白话形式记录,所以难免有些地方使用描述地不够恰当,甚至也会理解错误,恳请读者们指正,谢谢!我们努力提供更加友好的资料,不误导人。如果您想要加入我们,请与我们联系,谢谢。
作者简介:邵奈一
全栈工程师、市场洞察者、专栏编辑
| 公众号 | 微信 | 微博 | CSDN | 简书 |
福利:
邵奈一的技术博客导航
邵奈一 原创不易,如转载请标明出处。