使用Python完成你的第一个学习项目
你是否想使用python进行机器学习但却难以入门? 在这篇教程中,你将用Python完成你的第一个机器学习项目。 在以下的教程中,你将学到:
下载并安装Python SciPy,为Python中的机器学习安装最有用的软件包。
使用统计摘要和数据可视化加载数据集并了解其结构。
创建6个机器学习模型,并挑选出最佳模型以确保准确性。
本教程为决心使用python进行机器学习的新手做一个讲解。 让我们开始吧!
2017/01 更新:更新后反映了版本0.18中的scikit- learn API的变化。
2017/03 更新:添加了有助于设置Python环境的链接。
如何开始在Python中的机器学习?
学习机器学习的最好方式是设计和完成小型项目。
在入门时Python遇到的困难
Python是一种当下流行并且功能强大的解释型语言。与R语言不同,Python有完善的语言和平台,能用来研究和开发。 还有很多模块和库可以选择,提供多种方式来完成每个任务。 开始使用Python进行机器学习的最好方法是完成一个项目。
它将促使你安装并启动Python解释器。
它让你全面的观察怎样通过一个小项目。
它会给你信心,也许会驱动你继续做自己的小项目。
初学者需要一个小型的端到端项目
很多书籍和课程让人失望。他们给你很多方法和片段,但你永远不会看到他们如何融合在一起。 当你将机器学习应用在自己的数据集时,你已经开始了一个项目。 机器学习项目可能不是线性的,但它有许多典型的步骤:
定义问题
准备数据
评估算法。
改善成绩。
得到结果。
真正开始新平台或工具的最佳方式是通过一个机器学习项目进行端到端,并覆盖关键步骤。也就是从加载数据、总结数据、评估算法和做出一些预测。 如果可以这样做,您将有一个可以在数据集之后的数据集上使用的模板。一旦你有更多的信心,你可以进一步的填补数据和改进结果的差距。
机器学习的Hello World
开始使用新工具的最好的小项目是鸢尾花的分类(如鸢尾花数据集)。 这是一个很好理解的项目。
属性是数值型的,因此你必须弄清楚如何加载和处理数据。
这是一个分类问题,允许你练习更简单的监督学习算法。
这是一个多类的分类问题(多项式),可能需要一些专门的处理。
它只有4种属性和150行,这意味着它很小,很容易与内存(以及屏幕或A4页面)相匹配。
所有的数值属性都是相同的单位和相同的比例,不需要任何特殊的缩放或变换来开始。
让我们开始使用Python中的hello world机器学习项目。
Python中的机器学习:分步教程
在本节中,我们将通过端到端的小型机器学习项目进行工作。 以下是我们将要介绍的内容:
安装Python和SciPy平台
加载数据集
汇总数据集
可视化数据集
评估一些算法
做一些预测
慢慢来,一步一步做。 你可以尝试自己输入命令也可以通过复制粘贴来加快速度。
1.下载,安装和启动Python SciPy
如果你的系统上没安装Python和SciPy平台那就要安装。 我不想太详细地介绍这个,因为有别人已经有介绍过了,这对一个开发人员来说很简单。
1.1安装SciPy库
本教程假定Python版本为2.7或3.5。 你需要安装5个关键库。以下是本教程所需的Python SciPy库列表:
SciPy
numpy
matplotlib
pandas
sklearn
有很多方法来安装这些库。 该SciPy的安装页面对多个不同的平台提供了极好的说明书,如Linux,Mac OS X和Windows。如果你有任何疑问或疑问,请参阅本说明。
在Mac OS X上,你可以使用macports来安装Python 2.7和这些库。有关macports的更多信息,请参阅主页。
在Linux上,你可以使用包管理器,例如Fedora上的yum来安装RPM。
如果你使用Windows或者你没什么信心,我建议安装免费版本的Anaconda,其中包含你需要的一切。 注意:本教程假设你已经安装scikit-learn版本0.18或更高版本。 需要更多帮助?请参阅以下教程之一:
如何为Anaconda设置机器学习和深度学习的Python环境
如何使用Python创建用于机器学习开发的Linux虚拟机
1.2启动Python并检查版本
确保你的Python环境安装成功并按预期工作。 下面的脚本将帮助你测试你的环境。它导入本教程中所需的每个库并打印出版本。 打开命令行并启动python解释器:
python
我建议直接在解释器中工作,或者编写脚本,并在命令行上运行它们,而不是用大型编辑器和IDE。不要让事情变复杂,专注于机器学习而不是工具链。 键入或者粘贴以下脚本:
# Check the versions of libraries
# Python version
import sys
print('Python: {}'.format(sys.version))
# scipy
import scipy
print('scipy: {}'.format(scipy.__version__))
# numpy
import numpy
print('numpy: {}'.format(numpy.__version__))
# matplotlib
import matplotlib
print('matplotlib: {}'.format(matplotlib.__version__))
# pandas
import pandas
print('pandas: {}'.format(pandas.__version__))
# scikit-learn
import sklearn
print('sklearn: {}'.format(sklearn.__version__))
这是我在我的OS X工作站上得到的输出:
Python: 2.7.11 (default, Mar 1 2016, 18:40:10)
[GCC 4.2.1 Compatible Apple LLVM 7.0.2 (clang-700.1.81)]
scipy: 0.17.0
numpy: 1.10.4
matplotlib: 1.5.1
pandas: 0.17.1
sklearn: 0.18.1
将上述输出与你的版本进行比较。 理想情况下,你的版本应该匹配或更新。API不会很快改变,所以如果你的版本更高,不必担心,本教程中的所有内容很有可能仍然适用于你。 如果你收到错误,请停止。现在是修复它的时候了。 如果你无法正常运行上述脚本,也无法完成本教程。 我最好的建议是在Google上搜索你的错误信息或在Stack Exchange上发布问题。
2.加载数据
我们将使用鸢尾花数据集。这个数据集很有名,因为它几乎被大家用作机器学习和统计中的“hello world”。 该数据集包含150个鸢尾花观测值。有四列测量花的尺寸。第五列是观察到的花的种类。所有观察到的花只有三种。 你可以在维基百科上了解有关此数据集的更多信息。 在此步骤中,我们将从CSV文件的URL加载鸢尾数据。
2.1导入库
首先,我们将导入我们将在本教程中使用的所有模块,函数和对象。
# Load libraries
import pandas
from pandas.tools.plotting import scatter_matrix
import matplotlib.pyplot as plt
from sklearn import model_selection
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
这些加载应该没有错误。如果你有错误,请停止。回到上面,你需要一个可行的SciPy环境。请参阅上面关于设置环境的建议。
2.2加载数据集
我们可以直接从UCI机器学习存储库加载数据。 我们正在使用pandas来加载数据。我们还将使用pandas来探索具有描述性统计数据和数据可视化的数据。 请注意,我们在装载数据时指定了每个列的名称。这有助于我们稍后研究数据。
# Load dataset
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']
dataset = pandas.read_csv(url, names=names)
数据集应该会加载的很顺利 如果你有网络问题,可以下载iris。将数据文件放入工作目录,并使用相同的方法加载它,将URL更改为本地文件名。
3.汇总数据集
现在是查看数据的时候了。 在这一步中,我们将以几种不同的方式来查看数据:
数据集的尺寸。
仔细观察数据本身。
所有属性的统计汇总。
按类变量细分数据。
记住每次查看数据的命令。这些都是有用的命令,你可以在以后的项目中反复使用。
3.1数据集的尺寸
我们可以快速了解数据在shape属性中包含多少个实例(行)和多少个属性(列)
# shape
print(dataset.shape)
你应该看到150个实例和5个属性
(150, 5)
3.2观察数据
仔细观察你的数据
# head
print(dataset.head(20))
你应该会看到数据的前20行:
sepal-length sepal-width petal-length petal-width class
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
5 5.4 3.9 1.7 0.4 Iris-setosa
6 4.6 3.4 1.4 0.3 Iris-setosa
7 5.0 3.4 1.5 0.2 Iris-setosa
8 4.4 2.9 1.4 0.2 Iris-setosa
9 4.9 3.1 1.5 0.1 Iris-setosa
10 5.4 3.7 1.5 0.2 Iris-setosa
11 4.8 3.4 1.6 0.2 Iris-setosa
12 4.8 3.0 1.4 0.1 Iris-setosa
13 4.3 3.0 1.1 0.1 Iris-setosa
14 5.8 4.0 1.2 0.2 Iris-setosa
15 5.7 4.4 1.5 0.4 Iris-setosa
16 5.4 3.9 1.3 0.4 Iris-setosa
17 5.1 3.5 1.4 0.3 Iris-setosa
18 5.7 3.8 1.7 0.3 Iris-setosa
19 5.1 3.8 1.5 0.3 Iris-setosa
3.3统计汇总
现在我们可以看一下每个属性的总结。 这包括计数,平均值,最小值和最大值以及一些百分位数
# descriptions
print(dataset.describe())
我们可以看到,所有的数值都有相同的单位(厘米),范围在0到8厘米之间。
sepal-length sepal-width petal-length petal-width
count 150.000000 150.000000 150.000000 150.000000
mean 5.843333 3.054000 3.758667 1.198667
std 0.828066 0.433594 1.764420 0.763161
min 4.300000 2.000000 1.000000 0.100000
25% 5.100000 2.800000 1.600000 0.300000
50% 5.800000 3.000000 4.350000 1.300000
75% 6.400000 3.300000 5.100000 1.800000
max 7.900000 4.400000 6.900000 2.500000
3.4分类
现在来看看属于每个类的实例(行)的数量。我们可以将其视为绝对数。
# class distribution
print(dataset.groupby('class').size())
我们可以看到每个类具有相同数量的实例(50或者说33%的数据集)。
class
Iris-setosa 50
Iris-versicolor 50
Iris-virginica 50
4.数据可视化
我们现在对数据有一个基本的了解。我们需要通过一些可视化来让自己更了解它。 我们要看两种图:
单变量图更好地了解每个属性。
多变量图更好地了解属性之间的关系。
4.1单变量图
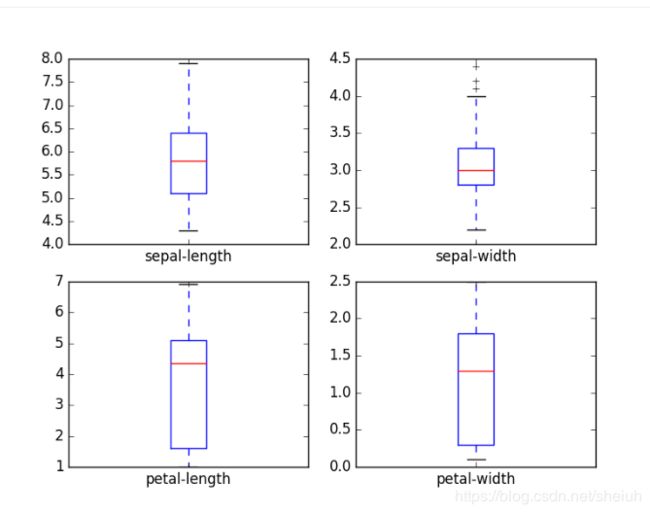
我们从一些单变量开始,即每个变量的曲线。 考虑到输入变量是数值型,我们可以创建每个输入变量的盒型图。
# box and whisker plots
dataset.plot(kind='box', subplots=True, layout=(2,2), sharex=False, sharey=False)
plt.show()
这使我们更清楚地了解输入属性的分布:
4.2多变量图
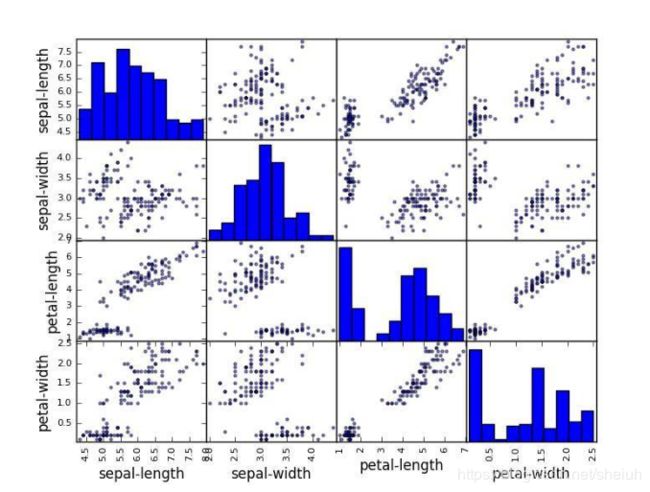
现在我们可以看一下变量之间的相互作用。 首先,我们来看看所有属性对的散点图。这可以有助于发现输入变量之间的结构化关系。
# scatter plot matrix
scatter_matrix(dataset)
plt.show()
注意这些接近对角线的组,这是高度的相关性和可预测关系的表现。
5.评估算法
现在创建一些数据模型,并评估它们对未来数据预测的准确性。 下面是我们将要讨论的内容是:
抽离一个验证数据集。
设置测试工具使用10倍交叉验证。
建立5种不同的模型来预测花卉测量中的种类。
选择最好的模型。
5.1创建验证数据集
我们需要知道,我们创建的模型有什么用。 之后,我们将使用统计方法来估计我们在预测的数据上创建模型的准确性。我们还希望通过对实际预测数据进行评估,从而更具体地估计出最佳模型的准确性。 也就是说,我们将保留一些算法无法看到的数据,我们将利用这些数据来确定模型究竟有多精确。 我们将把加载的数据集分为两部分,其中80%将用于训练我们的模型,20%将被用作验证数据集。
# Split-out validation dataset
array = dataset.values
X = array[:,0:4]
Y = array[:,4]
validation_size = 0.20
seed = 7
X_train, X_validation, Y_train, Y_validation = model_selection.train_test_split(X, Y, test_size=validation_size, random_state=seed)
你现在可以在X_train和Y_train中训练数据为准备模型和X_validation和Y_validation集,因为我们一会儿用得上。
5.2测试工具
我们将使用10倍交叉验证来估计精度。 这将把我们的数据集分为10个部分,在9上训练,并在1上进行测试,并重复训练分组的所有组合。
# Test options and evaluation metric
seed = 7
scoring = 'accuracy'
我们使用“ accuracy” 的度量来评估模型。这是正确预测实例的数量除以数据集中的实例总数乘以100的百分比(例如95%准确)的比率。 当我们运行构建并评估每个模型时,我们将使用评分变量。
5.3建立模型
我们不知道哪些算法对这个问题或什么配置使用是好的。我们从图中得出一些想法,即某些类在某些方面是部分可线性分离的,所以我们期望一般的结果很好。 我们来评估6种不同的算法:
逻辑回归(LR)
线性判别分析(LDA)
邻近算法(KNN)。
分类和回归树(CART)。
高斯朴素贝叶斯(NB)。
支持向量机(SVM)。
这是简单线性(LR和LDA),非线性(KNN,CART,NB和SVM)算法的良好混合。我们在每次运行之前重置随机数种子,以确保使用完全相同的数据分割来执行每个算法的评估。它确保结果直接可比。 我们来建立和评估我们的五个模型:
# Spot Check Algorithms
models = []
models.append(('LR', LogisticRegression()))
models.append(('LDA', LinearDiscriminantAnalysis()))
models.append(('KNN', KNeighborsClassifier()))
models.append(('CART', DecisionTreeClassifier()))
models.append(('NB', GaussianNB()))
models.append(('SVM', SVC()))
# evaluate each model in turn
results = []
names = []
for name, model in models:
kfold = model_selection.KFold(n_splits=10, random_state=seed)
cv_results = model_selection.cross_val_score(model, X_train, Y_train, cv=kfold, scoring=scoring)
results.append(cv_results)
names.append(name)
msg = '%s: %f (%f)' % (name, cv_results.mean(), cv_results.std())
print(msg)
5.3选择最佳模型
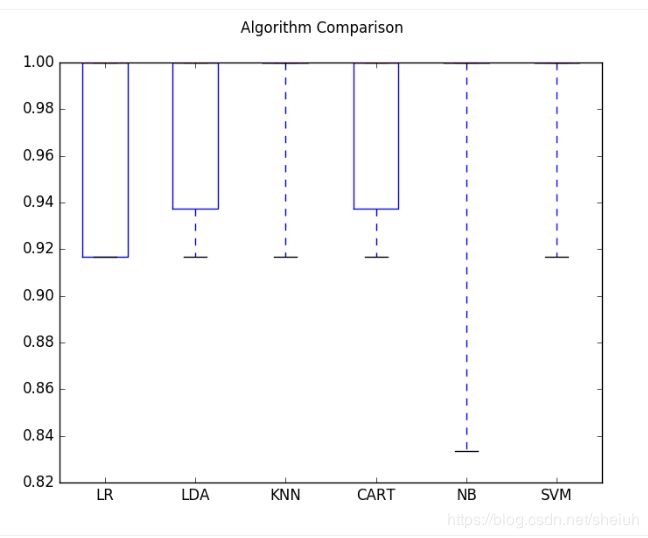
我们现在每个都有6个模型和精度估计。我们需要将模型相互比较,并选择最准确的。 运行上面的例子,我们得到以下原始结果: LR: 0.966667 (0.040825) LDA: 0.975000 (0.038188) KNN: 0.983333 (0.033333) CART: 0.975000 (0.038188) NB: 0.975000 (0.053359) SVM: 0.981667 (0.025000) 我们可以看到,看起来KNN具有最高的估计精度分数。 我们还可以创建模型评估结果的图,并比较每个模型的差异和平均精度。每个算法有一个精确度量的群体,因为每个算法被评估10次(10次交叉验证)。
# Compare Algorithms
fig = plt.figure()
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
plt.boxplot(results)
ax.set_xticklabels(names)
plt.show()
你可以看到盒型图在顶部被压扁,许多样品达到100%的准确度。
6.做预测
KNN算法是我们测试的最精确的模型。现在我们想知道验证集上模型的准确性。 这让我们对最佳模型的准确性进行独立的最终检查。保持一个验证集是有用的,以防万一你在训练过程中犯错,比如过拟合或数据外泄。两者都将导致过于乐观的结果。 我们可以直接在验证集上运行KNN模型,并将结果总结为最终准确度分数,混淆矩阵和分类报告。
# Make predictions on validation dataset
knn = KNeighborsClassifier()
knn.fit(X_train, Y_train)
predictions = knn.predict(X_validation)
print(accuracy_score(Y_validation, predictions))
print(confusion_matrix(Y_validation, predictions))
print(classification_report(Y_validation, predictions))
我们可以看到准确度是0.9即90%。混淆矩阵提供了三个错误的指示。最后,分类报告通过精确度,召回率,f1分数和支撑显示出优异的结果(授予验证数据集很小)提供每个类别的细目。
0.9
[[ 7 0 0]
[ 0 11 1]
[ 0 2 9]]
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 7
Iris-versicolor 0.85 0.92 0.88 12
Iris-virginica 0.90 0.82 0.86 11
avg / total 0.90 0.90 0.90 30
完成上面的教程,只需要5到10分钟。
概要
在这篇文章中,你会逐步发现如何在Python中完成第一个机器学习项目。 你将发现,完成一个小型的端到端项目并将数据加载到预测中,是熟悉新平台的最佳途径
到最后给大家推荐一篇好的文章,文章链接::https://blog.csdn.net/sheiuh/article/details/102575410