竞赛分享-自动文摘(bytecup 2018)
自动文摘(Auto Text Summarization)
自动文摘,也称自动摘要生成,是NLP中较难的技术,难点很多,至今并没有一个非常让人满意的、成熟的技术来解决这个问题。
介绍
应用
- 自动文摘技术应用最广的领域在于新闻,由于新闻信息的过载,人们迫切地希望有这么一个工具可以帮助自己用最短的时间了解最多的最有用的新闻。
ps:为什么不直接看标题呢?因为很多新闻为了哗众取宠,故意将标题起的特别吸引人眼球,但却名不副实,因此就有了Yahoo3000w$收购summly的交易。 - 搜索引擎也是应用之一,基于query的自动文摘会帮助用户尽快地找到感兴趣的内容。
前者是单文档摘要技术,后者是多文档摘要技术,后者较于前者会更加复杂一些。
自动文摘出现的重要原因之一是信息过载问题的困扰(个性化推荐系统也是一个好的办法),另外一个重要原因是人工文摘的成本较高。
问题描述
自动文摘要解决的问题描述:用一些精炼的话来概括整篇文章的大意,用户通过阅读文摘就可以了解到原文要表达的意思,即提炼文章的中心思想。
解决思路
问题包括两种解决思路:
- extractive,抽取式的,从原文中找到一些关键的句子,组合成一篇摘要;现阶段,相对成熟的是抽取式的方案,有很多很多的算法(TextRank、TextTeaser等),也有一些baseline的测试,但得到的摘要效果差强人意。
- abstractive,摘要式的,这需要计算机可以读懂原文的内容,并且用自己的意思将其表达出来。人类语言包括字、词、短语、句子、段落、文档这几个level,研究难度依次递增,理解句子、段落尚且困难,何况是文档,这是自动文摘最大的难点,也是更接近机器智能的味道。
难点
Abstractive是一个True AI的方法,要求系统理解文档所表达的意思,然后用可读性强的人类语言将其简练地总结出来。这里包含这么几个难点:
- 理解文档。所谓理解,和人类阅读一篇文章一样,可以说明白文档的中心思想,涉及到的话题等等。
- 可读性强。可读性是指生成的摘要要能够连贯(Coherence)与衔接(Cohesion),通俗地讲就是人类读起来几乎感觉不出来是AI生成的(通过图灵测试)。
- 简练总结。在理解了文档意思的基础上,提炼出最核心的部分,用最短的话讲明白全文的意思。
上述三个难点对于人类来说都不是一件容易的事情,对自然语言处理技术挑战也很大。
竞赛
2018 Byte Cup国际机器学习竞赛的主题是自动生成文本标题。比赛官网:https://biendata.com/competition/bytecup2018/
简介
说明比赛内容,数据,奖励,评测方法,取得的成绩。
数据预处理
- 分词
- 文本分析
a)训练数据的文章长度: b)标题长度: c)待预测文章长度: 论文:Rush et al.2015 Alexander M. Rush, Sumit Chopra, and Jason Weston. 2015. A neural attention model for abstractive sentence summarization. EMNLP 2015 Abstractive是学术界研究的热点,尤其是Machine Translation(MT)中的encoder-decoder框架和attention mechanism十分火热,大家都试着将abstractive问题转换为sequence-2-sequence问题,套用上面两种技术,得到state-of-the-art结果,2015年来已经有许多篇paper都是这种套路,于是就有了下面的吐槽: Encoder-Decoder不是一种模型,而是一种框架,一种处理问题的思路,最早应用于机器翻译领域,输入一个序列,输出另外一个序列。机器翻译问题就是将一种语言序列转换成另外一种语言序列,将该技术扩展到其他领域,比如输入序列可以是文字,语音,图像,视频,输出序列可以是文字,图像,可以解决很多别的类型的问题。这一大类问题就是上图中的sequence-to-sequence问题。这里以输入为文本,输出也为文本作为例子进行介绍: 论文:IBM Watson,Abstractive Text Summarization using Seq2Seq RNNs and Beyond. 2016 本文的贡献点有三个: 目前,解决seq2seq的问题,都是借鉴machine translation的方法。 本文与之前seq2seq类的paper有着一个很明显的区别,就是将摘要问题和机器翻译问题严格区别开,而不是简单地套用MT的技术来解决摘要问题,根据摘要问题的特点提出了更加合适的模型,相比于之前的研究更进了一步。 之前大量的研究都是集中于extractive摘要方法,在DUC2003和2004比赛中取得了不俗的成绩。但人类在做摘要工作时,都是采用abstractive方法,理解一篇文档然后用自己的语言转述出来。随着深度学习技术在NLP任务中的广泛使用,研究者们开始更多地研究abstractive方法,比如Rush组的工作,比如哈工大Hu的工作。 这个模型本文的基准模型,Encoder是一个双向GRU-RNN,Decoder是一个单向GRU-RNN,两个RNN的隐藏层大小相同,注意力模型应用在Encoder的hidden state上,一个softmax分类器应用在Decoder的生成器上。 分析:基准模型是套用Bahdanau,2014在机器翻译中的方法,解决方案的思路都与之前的paper类似,并无新颖之处。 这个模型引入了large vocabulary trick(LVT)技术到文本摘要问题上。本文方法中,每个mini batch中decoder的词汇表受制于encoder的词汇表,decoder词汇表中的词由一定数量的高频词构成。这个模型的思路重点解决的是由于decoder词汇表过大而造成softmax层的计算瓶颈。本模型非常适合解决文本摘要问题,因为摘要中的很多词都是来自于原文之中。 分析:LVT是一个针对文本摘要问题的有效方法,考虑到了摘要中的大部分词都是来源于原文之中,所以将decoder的词汇表做了约束,降低了decoder词汇表规模,加速了训练过程。 LVT技术很好地解决了decoder在生成词时的计算瓶颈问题,但却不能够生成新颖的有意义的词。为了解决这个问题,本文提出了一种扩展LVT词汇表的技术,将原文中所有单词的一度最邻近单词扩充到词汇表中,最邻近的单词在词向量空间中cosine相似度来计算得出。 分析:词汇表的扩展是一项非常重要的技术,word embedding在这里起到了关键作用。用原文中单词的最邻近单词来丰富词汇表,不仅仅利用LVT加速的优势,也弥补了LVT带来的问题。 文本摘要面临一个很大的挑战在于确定摘要中应该包括哪些关键概念和关键实体。因此,本文使用了一些额外的features,比如:词性,命名实体标签,单词的TF和IDF。将features融入到了word embedding上,对于原文中的每个单词构建一个融合多features的word embedding,而decoder部分,仍采用原来的word embedding。 分析:本文的一个创新点在于融入了word feature,构建了一组新的word embedding,分别考虑了单词的词性、TF、IDF和是否为命名实体,让单词具有多个维度的意义,而这些维度上的意义对于生成摘要至关重要。本文结果的优秀表现再一次印证了简单粗暴的纯data driven方法比不上同时考虑feature的方法。后面的研究可以根据本文的思路进行进一步地改进,相信会取得更大的突破。 文本摘要中经常预见这样的问题,一些关键词出现很少但却很重要,由于模型基于word embedding,对低频词的处理并不友好,所以本文提出了一种decoder/pointer机制来解决这个问题。模型中decoder带有一个开关,如果开关状态是打开generator,则生成一个单词;如果是关闭,decoder则生成一个原文单词位置的指针,然后拷贝到摘要中。pointer机制在解决低频词时鲁棒性比较强,因为使用了encoder中低频词的隐藏层表示作为输入,是一个上下文相关的表示,而仅仅是一个词向量。 分析:Pointer机制与Copy机制有异曲同工之妙,都是用来解决OOV问题的,本文的最关键的是如何计算开关状态是generator的概率,这一层的计算关系到当前time step是采用generator模式还是pointer模式。 数据集中的原文一般都会很长,原文中的关键词和关键句子对于形成摘要都很重要,这个模型使用两个双向RNN来捕捉这两个层次的重要性,一个是word-level,一个是sentence-level,为了区别与Li的工作,本文在两个层次上都使用注意力模型。 分析:注意力机制的本质是一组decoder与encoder之间相关联的权重,本文在两个层次上重新定义了attention weight,既考虑了某个encoder中每个word对于decoder的重要性,也考虑了该word所在sentence对于decoder的重要性。 为了作对比,本文采用了Rush文章中的Gigaword数据集和他的开源代码来处理数据,形成了380万训练样本和约40万验证样本和测试样本,本文随机选取2000组样本作为验证和测试集来测试本文模型的性能,为了更加公平地对比,本文使用了Rush采用的测试集来对比。 分析:从表中清晰地看到switching generator/pointer模型在各个指标上都是最好的模型,本文的模型在Rush测试集中的结果都优于Rush的ABS+模型。 本文的模型在一些数据的处理会理解错原文的意思,生成一些“错误”的摘要。另外,Switching Generator/Pointer模型不仅仅在处理命名实体上有优势,而且在处理词组上表现也非常好。未来的工作中,将会对该模型进行更多的实验。效果见下图: 分析:本文模型相对于Rush的模型有了更进一步的效果,但对于文本摘要问题来说,并没有本质上的提升,也会经常出现这样或者那样的错误。指标上的领先是一种进步,但与评价指标太过死板也有关系,现有的评价指标很难从语义这个层次上来评价结果。所以,文本摘要问题的解决需要解决方方面面的问题,比如数据集,比如评价指标,比如模型,任何一个方面的突破都会带来文本摘要问题的突破。 本文是一篇非常优秀的paper,在seq2seq+attention的基础上融合了很多的features、trick进来,提出了多组对比的模型,并且在多种不同类型的数据集上做了评测,都证明了本文模型更加出色。从本文中得到了很多的启发。 just show code: https://github.com/tshi04/AbsSum

结论: 需要去太长及太少的文本,100

结论: 5

结论: length<500模型
sequence-to-sequence(seq2seq)

Encoder-Decoder

这里,每一种模型几乎都可以出一篇paper,尤其是在这个技术刚刚开始应用在各个领域中的时候,大家通过尝试不同的模型组合,得到state-of-the-art结果。
该框架最早被应用在Google Translation中,paper详情可以见Generating News Headlines with Recurrent Neural Networks,2014年12月发表。模型优化
Seq2Seq RNNs and Beyond
Introduction
但文本摘要问题和机器翻译问题有着很大的不同。
那么机器翻译的相关技术是否会在文本摘要问题上表现同样突出呢?本文将会回答这个问题。受文本摘要与机器翻译问题的不同特点所启发,本文将超越一般的架构而提出新的模型来解决摘要问题。Related work
本文的贡献:
Models
Encoder-Decoder with Attention
Large Vocabulary Trick
Vocabulary expansion
Feature-rich Encoder

Switching Generator/Pointer
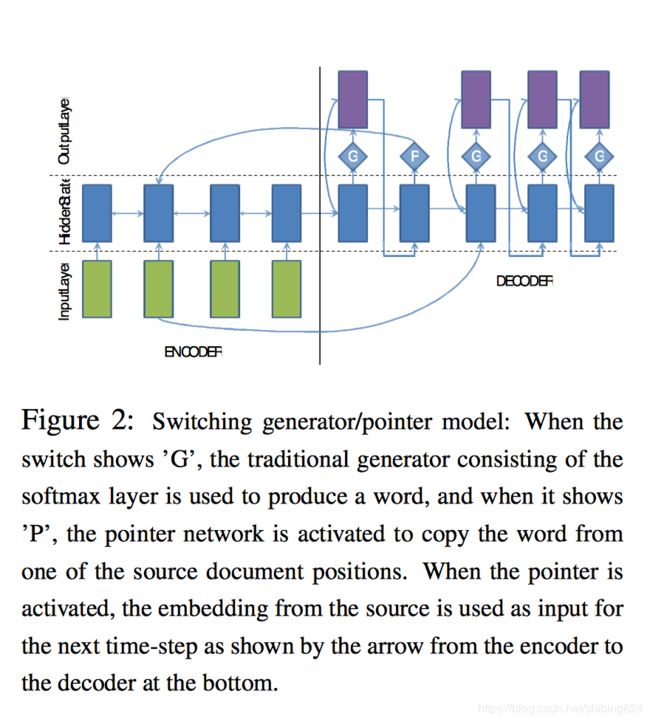
Hierarchical Encoder with Hieratchical Attention
本文模型示意图如下:

Experiments and Results
Gigaword Corpus
初始词向量的生成是用Word2Vec,但在训练的过程中会更新词向量。训练的参数设置也都采用一般的训练设置。
在Decoder阶段,采用大小为5的beam search来生成摘要,并且约束摘要长度不大于30个单词。
评价指标方面,采用full-length Rouge召回率,然而该指标更加青睐于长摘要,所以在比较两个生成不同长度摘要的系统时并不公平,用full-length F1来评价更加合理。
对比实验共有以下几组:
实验结果如下:
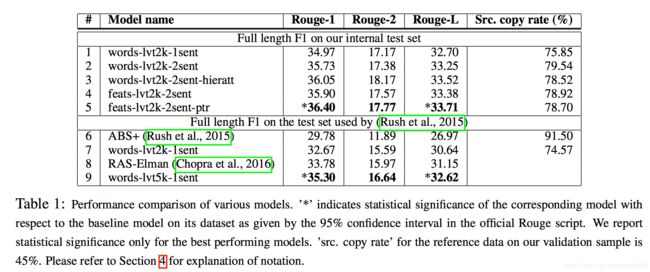
Gigaword由于其数据量大的特点,常被用于文本摘要任务中作为训练数据。本文的训练、生成参数都沿用了传统的方法,评价指标选择了更合适的F1,共设计了8大组实验,从方方面面对比了各个模型之间的优劣,从多个角度说明了本文模型比前人的模型更加优秀。
数据集对于deep learning是至关重要的,构建一个合适的数据集是一个非常有意义的工作。哈工大之前有一个工作就是构建了微博摘要的数据集,方便了研究中文文本摘要的研究者。Qualitative Analysis

Review
代码分析