Googlenet论文笔记及代码实现
Googlenet
2014年ImageNet比赛冠军模型,论文发表于cvpr2015
论文原文地址:https://arxiv.org/abs/1409.4842
参考翻译地址:https://blog.csdn.net/c_chuxin/article/details/82856502
卷积神经网络发展史的重要时间点
主要探讨了如何在没有大量增加参数的情况下增加网络深度
LeNet
LeNet是卷积神经网络的开山之作1998年与LeCun提出
缺点:网络层浅,无激活层
AlexNet
AlexNet:2012年在ImageNet竞赛取得了冠军,相较于AlexNet,网络更深,同时第一次引入拉人ReLu激活层,在全链接层引入了Dropout层防止过拟合。
VGGNet
VGGNet:ImageNet 2014年亚军,相比于AlexNet,AlexNet只有8层,而VGG有16~19层,AlexNet使用了11x11的卷积器,VGG使用了3x3卷积核和2x2的最大池化层。
GoogLeNet
GoogLeNet:2014年ImageNet比赛冠军,比VGG更深的网络,而参数却比AlexNet少了12倍。Inception模块。
Inception v1:
增加了网络宽度每个卷积后都做一个relu操作
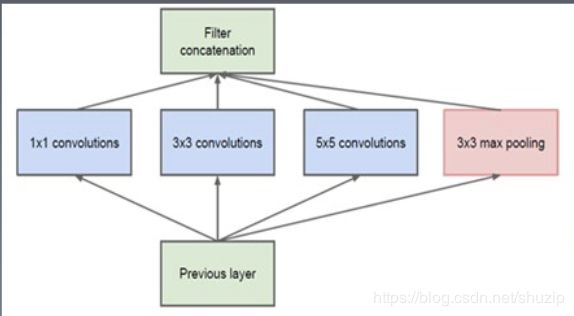
Inception v2:
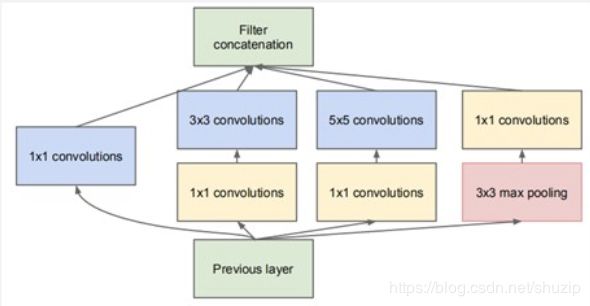
5x5卷积和所需计算量很大,在3x3和5x5前以及max pooling后加上了1x1卷积核,以降低特征图都厚度。
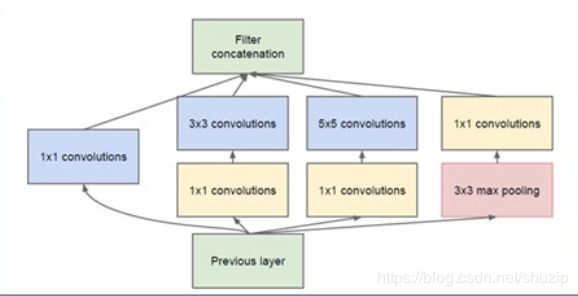
Inception v3:
不改变感受野同时采用1xn和nx1卷积核替代nxn卷积核

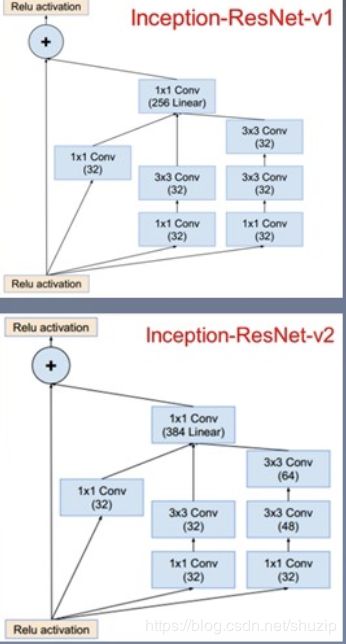
Inception v4:
加入了残差链接改进v3结构
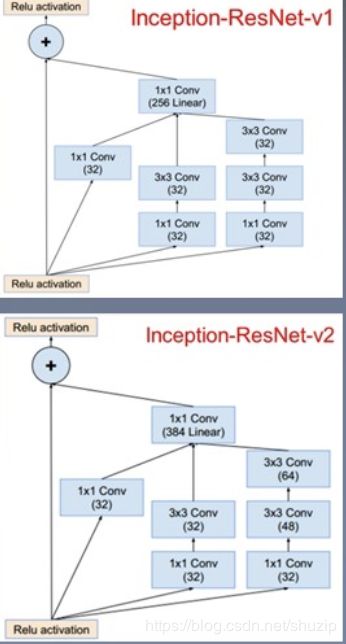
1 x 1 Conv
- 在相同尺寸的感受野中叠加更多的卷积,能提取到更丰富的特种。
- 使用1x1卷积进行降维,降低了计算复杂度。
多尺寸卷积聚合:
-
在直观感觉上在多个尺度上进行同时卷积,能提取到不同尺度到特征。(一张图片中,人和汽车大小是不同到,用不同尺寸到卷积核提取特征效果比单一尺寸卷积核效果好。
-
利用稀疏矩阵分解成密集矩阵计算到原理来加快收敛速度。Inception就是在特征维度上进行分解
-
Hebbin 赫布原理,Inception结构吧相关性强到特征汇聚到一起。
pytorch 代码实现
import sys
sys.path.append('..')
import numpy as np
import torch
from torch import nn
from torch.autograd import Variable
from torchvision.datasets import CIFAR10
# 定义一个卷积加一个 relu 激活函数和一个 batchnorm 作为一个基本的层结构
def conv_relu(in_channel, out_channel, kernel, stride=1, padding=0):
layer = nn.Sequential(
nn.Conv2d(in_channel, out_channel, kernel, stride, padding),
nn.BatchNorm2d(out_channel, eps=1e-3),
nn.ReLU(True)
)
return layer
class inception(nn.Module):
def __init__(self, in_channel, out1_1, out2_1, out2_3, out3_1, out3_5, out4_1):
super(inception, self).__init__()
# 第一条线路
self.branch1x1 = conv_relu(in_channel, out1_1, 1)
# 第二条线路
self.branch3x3 = nn.Sequential(
conv_relu(in_channel, out2_1, 1),
conv_relu(out2_1, out2_3, 3, padding=1)
)
# 第三条线路
self.branch5x5 = nn.Sequential(
conv_relu(in_channel, out3_1, 1),
conv_relu(out3_1, out3_5, 5, padding=2)
)
# 第四条线路
self.branch_pool = nn.Sequential(
nn.MaxPool2d(3, stride=1, padding=1),
conv_relu(in_channel, out4_1, 1)
)
#定义inception前向传播
def forward(self, x):
f1 = self.branch1x1(x)
f2 = self.branch3x3(x)
f3 = self.branch5x5(x)
f4 = self.branch_pool(x)
output = torch.cat((f1, f2, f3, f4), dim=1)
return output
#测试网络
test_net = inception(3, 64, 48, 64, 64, 96, 32)
test_x = Variable(torch.zeros(1, 3, 96, 96))
print('input shape: {} x {} x {}'.format(test_x.shape[1], test_x.shape[2], test_x.shape[3]))
test_y = test_net(test_x)
print('output shape: {} x {} x {}'.format(test_y.shape[1], test_y.shape[2], test_y.shape[3]))
class googlenet(nn.Module):
def __init__(self, in_channel, num_classes, verbose=False):
super(googlenet, self).__init__()
self.verbose = verbose
self.block1 = nn.Sequential(
conv_relu(in_channel, out_channel=64, kernel=7, stride=2, padding=3),
nn.MaxPool2d(3, 2)
)
self.block2 = nn.Sequential(
conv_relu(64, 64, kernel=1),
conv_relu(64, 192, kernel=3, padding=1),
nn.MaxPool2d(3, 2)
)
self.block3 = nn.Sequential(
inception(192, 64, 96, 128, 16, 32, 32),
inception(256, 128, 128, 192, 32, 96, 64),
nn.MaxPool2d(3, 2)
)
self.block4 = nn.Sequential(
inception(480, 192, 96, 208, 16, 48, 64),
inception(512, 160, 112, 224, 24, 64, 64),
inception(512, 128, 128, 256, 24, 64, 64),
inception(512, 112, 144, 288, 32, 64, 64),
inception(528, 256, 160, 320, 32, 128, 128),
nn.MaxPool2d(3, 2)
)
self.block5 = nn.Sequential(
inception(832, 256, 160, 320, 32, 128, 128),
inception(832, 384, 182, 384, 48, 128, 128),
nn.AvgPool2d(2)
)
self.classifier = nn.Linear(1024, num_classes)
def forward(self, x):
x = self.block1(x)
if self.verbose:
print('block 1 output: {}'.format(x.shape))
x = self.block2(x)
if self.verbose:
print('block 2 output: {}'.format(x.shape))
x = self.block3(x)
if self.verbose:
print('block 3 output: {}'.format(x.shape))
x = self.block4(x)
if self.verbose:
print('block 4 output: {}'.format(x.shape))
x = self.block5(x)
if self.verbose:
print('block 5 output: {}'.format(x.shape))
x = x.view(x.shape[0], -1)
x = self.classifier(x)
return x