北理网课 - Python语言程序设计 - 9.3 从Web解析到网络空间
一、Python库之网络爬虫
Requests:最友好的网络爬虫功能库
-提供了简单易用的类HTTP协议网络爬虫功能 
-支持连接池、SSL、Cookies、HTTP(S)代理等
-Python最主要的页面级网络爬虫功能库
例:
import requests
r = requests.get('https://python123.io/student/courses', auth = ('user', 'pass'))#访问某一个连接,获取其中的网页信息
r.status_code#获得访问网络的状态效果
r.headers['content-type']
r.encoding
r.text#获得其中的文本信息
但这个我试过了,终端没有输出任何信息
网址:http://www.python-requests.org/
---------------------------------------------------------------------------------------------------------------------------
Scrapy:优秀的网络爬虫框架
-提供了构建网络爬虫系统的框架(框架:功能的半成品,讲很多的基础功能已经完成,只需要用户进行扩展开发或额外配置即可)功能
-支持批量和网页定时爬取,提供数据处理流程等
-Python最主要且最专业的网络爬虫框架

网址:https://scrapy.org
---------------------------------------------------------------------------------------------------------------------------
pyspider:强大的Web页面爬取系统
-提供了完整的网页爬取系统构建功能
-支持数据库后端、消息队列、优先级、分布式架构等
-Python重要的网络爬虫类第三方库
网址:https://docs.pyspider.org
=======================================================================
二、Web库之信息提取
Beautiful Soup:HTML和XML的解析库
-提供了解析HTML和XML等Web信息功能
-又名beautifulsoup4或bs4,可加载多种解析引擎
-常与网络爬虫库搭配使用,如Scrapy、requests等
以下为工作方式,遍历

网址:https://www.crummy.com/software/BeautifulSoup4/bs4
---------------------------------------------------------------------------------------------------------------------------
Re:正则表达式解析和处理功能库(Regular Expression)
-提供了定义和解析正则表达式的一批通用功能
-可用于各类场景,包括定点的Web信息提取
-Python最主要的标准库之一,无需安装
比如我们定义有:
r'\d{3}-\d{8}|\d{4}-\d{7}'
我们可以用re.search()、re.match、re.findall()、re.split()、re.finditer()、re.sub()围绕这个定义的正则表达式进行信息查找和信息匹配
网址:https://docs.python.org/3.6/library/re.html
---------------------------------------------------------------------------------------------------------------------------
Python-Goose:提取文章类型Web页面的功能库
-提供了对Web页面中文章信息/视频等元素的提取功能
-针对特定类型的Web页面,但由于文章类型在互联网上及其常用,所以应用覆盖十分广泛
-Python中最主要的Web信息提取库
from goose import Goose
url = 'http://www.elmundu.es/elmundu/2012/10/28/espana/1351388909.html'
g = Goose({'use_meta_language':False, 'target_language:':'es'})
article = g.extract(url = url)
article.cleaned_text[:150]
以上goose库我没安装成功,后面我会回来看的
网址:https://github.com/grangier/python-goose
=======================================================================
三、Python库之Web网站开发
Django:最流行的Web应用框架
-提供了构建Web系统的基本应用框架
-MTV模式:模型(model)、模版(Template)、视图(Views)
-Python最主要的应用框架,略微复杂的应用框架
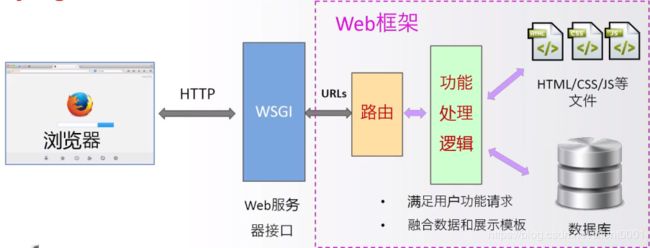
我们需要知道WSGI、URLs、路由等
网址:https://www.djangoproject.com
---------------------------------------------------------------------------------------------------------------------------
Pyramid:规模适中的应用框架
-提供了简单方便的Web系统应用框架
-不大不小,规模适中,适合快速构建并适度扩展类应用
-Python产品级Web应用框架,起步简单可扩展性好
以下使用10行左右的代码就可完成一个Web应用网站系统:
from wsgiref.simple_server import make_server
from pyramid.config import Configurator
from pyramid.response import Response
def hello_world(request):
return Response('Hello world!')
if _name_ == '_main_':
with Configurator() as config:
config.add_route('hello', '/')
config.add_view(hello_world, route_name = 'hello')
app = config.make_wsgi_app()
server = make_server('0.0.0.0', 6543, app)
server.serve_forever()
以上结果出错,没有定义_name_
网址:https://trypyramid.com/
---------------------------------------------------------------------------------------------------------------------------
Flask:Web应用开发微框架
-提供了最简单构建Web系统的应用框架
-特点:简单、快速、规模小
-复杂→简单:Django→Pyramid→Flask
from flask import Flask
app = Flask(_name_)
@app.route('/')
def hello_world():
return 'Hello,World!'
网址:http://flask.pocoo.org
=======================================================================
四、Python库之网络应用开发
WeRobot:微信公众号开发框架
-提供了解析微信服务器消息及反馈消息的功能
-建立微信机器人的重要技术手段
import werobot
robot = werobot.WeRoBot(token = 'tokenhere')
@robot.handler
def hello(message):
return 'Hello World!'
#对微信每个消息返回一个Hello World
网址:https://github.com/offu/WeRoBot
---------------------------------------------------------------------------------------------------------------------------
aip:百度AI开放平台接口
-提供了访问百度AI服务的Python功能接口
-语音、人脸、OCR、NLP、知识图谱、图像搜索等领域
-Python百度AI应用的最主要的方式
网址:https://github.com/Baidu-AIP/python-sdk
---------------------------------------------------------------------------------------------------------------------------
MyQR:二维码生成第三方库
-提供了生成二维码的系列功能
-可生成基本二维码、艺术二维码、动态二维码
网址:https://github.com/sylnsfar/qrcode
老师所做二维码: