Bert改进模型汇总(3)
目录
SpanBert: Improving Pre-training by Representing and Predicting Spans
Span Masking
Span Boundary Objective
Remove Next Sentence Prediction
RoBERTa:Robustly optimized BERT approach
More Data
Large Batch/More Steps/larger byte level BPE vocab
No Next Sentence Prediction
dynamic masking
XLNet
Reference
SpanBert: Improving Pre-training by Representing and Predicting Spans
论文地址 https://arxiv.org/abs/1907.10529
刚看论文题目 SpanBERT: Improving Pre-training by Representing and Predicting Spans,以为是篇水文章,Bert 遮盖(mask)掉一小段(span)的 idea 并不新了,早有人做过,如百度 ERNIE,还有 Google 放出的 WWM (Whole Word Masking) BERT 模型,都是类似做法,当然细节上会有些不同。
所以细节决定成败,当仔细读完这篇论文,才发现,真香。里面对 Bert 预训练细节的探索非常有趣,很有启发。
这篇论文的主要贡献有三:
- 提出了更好的 Span Mask 方案,也再次展示了随机遮盖连续一段字要比随机遮盖掉分散字好;
- 通过加入 Span Boundary Objective (SBO) 训练目标,增强了 BERT 的性能,特别在一些与 Span 相关的任务,如抽取式问答;
- 用实验获得了和 XLNet 类似的结果,发现不加入 Next Sentence Prediction (NSP) 任务,直接用连续一长句训练效果更好。
整体模型结构如下:

Span Masking
首先什么是 Span Masking,和一般 BERT 训练有何不同。
对于原始的 BERT,训练时,会随机选取整句中的最小输入单元 token 来进行遮盖。因为用到 Byte Pair Encoding (BPE)技术,所以也可以把这些最小单元当作是子词(subword),比如说superman,分成 super+man 两个子词。
但这样会让本来应该有强相关的一些连在一起的字词,在训练时是割裂开来的。
因此我们就会想到,那能不能遮盖掉这样连在一起的片段训练呢?当然可以。
首先想到的做法,既然现在遮盖子词,那能不能直接遮盖整个词,比如说对于 super + man,只要遮盖就两个同时遮盖掉,这便是 Google 放出的 BERT WWM 模型所做的。
于是能不能进一步,因为有些实体是几个词组成的,直接将这个实体都遮盖掉。因此百度在 ERNIE 模型中,就引入命名实体(Named Entity)外部知识,遮盖掉实体单元,进行训练。
以上两种做法比原始做法都有些提升。但这两种做法会让人认为,或许必须得引入类似词边界信息才能帮助训练。但前不久的 MASS 模型,却表明可能并不需要,随机遮盖可能效果也很好,于是就有本篇的 idea:
根据几何分布,先随机选择一段(span)的长度,之后再根据均匀分布随机选择这一段的起始位置,最后按照长度遮盖。文中使用几何分布取 p=0.2,最大长度只能是 10,利用此方案获得平均采样长度分布。
Span Boundary Objective
Span Boundary Objective 是该论文加入的新训练目标,希望被遮盖 Span 边界的词向量,能学习到 Span 的内容。或许作者想通过这个目标,让模型在一些需要 Span 的下游任务取得更好表现,结果表明也正如此。
具体做法是,在训练时取 Span 前后边界的两个词,值得指出,这两个词不在 Span 内,然后用这两个词向量加上 Span 中被遮盖掉词的位置向量,来预测原词。
对于每一个带掩膜的分词 (xs, ..., xe) ,使用(s, e)表示其起点和终点。对于分词中的每个单词 xi ,使用外边界单词 xs-1 和 xe+1 的编码进行表示,并添加其位置嵌入信息 pi ,如下:
![]()
详细做法是将词向量和位置向量拼接起来,作者使用一个两层的前馈神经网络作为表示函数,该网络使用 GeLu 激活函数,并使用层正则化:
 作者使用向量表示 yi 来预测 xi ,并和 MLM 一样使用交叉熵作为损失函数,就是 SBO 目标的损失,之后将这个损失和 BERT 的 Mased Language Model (MLM)的损失加起来,一起用于训练模型。
作者使用向量表示 yi 来预测 xi ,并和 MLM 一样使用交叉熵作为损失函数,就是 SBO 目标的损失,之后将这个损失和 BERT 的 Mased Language Model (MLM)的损失加起来,一起用于训练模型。
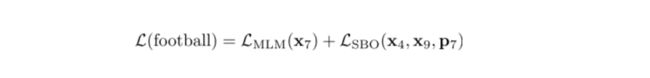
Remove Next Sentence Prediction
SpanBERT 还有一个和原始 BERT 训练很不同的地方,它没用 Next Sentence Prediction (NSP) 任务,而是直接用 Single-Sequence Training,也就是根本不加入 NSP 任务来判断是否两句是上下句,直接用一句来训练。作者推测其可能原因如下:(a)更长的语境对模型更有利,模型可以获得更长上下文(类似 XLNet 的一部分效果;(b)加入另一个文本的语境信息会给MLM 语言模型带来噪音。
因此,SpanBERT 就没采用 NSP 任务,仅采样一个单独的邻接片段,该片段长度最多为512个单词,其长度与 BERT 使用的两片段的最大长度总和相同,然后 MLM 加上 SBO 任务来进行预训练。
RoBERTa:Robustly optimized BERT approach
论文地址 https://arxiv.org/pdf/1907.11692.pdf
Github https://github.com/pytorch/fairseq
RoBerta对于Bert的主要改进有:
(1) 对模型进行更长时间、更大批量、更多数据的训练;
(2) 删除NSP;
(3) 对较长序列进行训练;
(4) 动态改变应用于训练数据的 masking 模式-----dynamic masking。
More Data
训练数据上,RoBERTa 采用了 160G 的训练文本,而 BERT 仅使用 16G 的训练文本, 其中包括: BOOKCORPUS 和英文维基百科:原始 BERT 的训练集,大小 16GB 。 CC-NEWS:6300 万篇英文新闻,大小 76 GB(经过过滤之后)。 OPENWEBTEXT:从 Reddit 上的网页内容,大小 38 GB 。 STORIES:CommonCrawl 数据集的一个子集,大小 31GB 。
Large Batch/More Steps/larger byte level BPE vocab
RoBERTa 模型增加了训练的 batch_size,并将 adam 的 0.999 改成了 0.98, 增加了训练的 step,最后使用的 batch_size 为 8k,训练步数为 500k 步。输入的 token 编码为 BPE 编码。
No Next Sentence Prediction
类似SpanBert
dynamic masking
何为 dynamic,只因原 BERT 预处理数据时,先处理好哪些位置被 mask,于是乎,炼制时,也就用着这些 static mask。而 dynamic 却是在训练时实时 mask,纵然是同一句话,每次 mask 位置也是随机不同。
XLNet
推荐这位大佬的文章,论文中很多讲的很简略的点在这里都解释了:飞跃芝麻街:XLNet 详解
Reference
SpanBert:对 Bert 预训练的一次深度探索
RoBERTa:高级丹药炼制记录