python︱sklearn一些小技巧的记录(训练集划分/pipelline/交叉验证等)
sklearn里面包含内容太多,所以一些实用小技巧还是挺好用的。
sklearn.cross_validation 如果没有了,则需要使用 sklearn.model_selection
文章目录
- 1、LabelEncoder
- 2、OneHotEncoder
- 3、sklearn.model_selection.train_test_split随机划分训练集和测试集
- 附加:shuffle 一键随机打乱:
- 4、pipeline
- Pipeline 的工作方式
- 5 稀疏矩阵合并
- 6 sklearn中的交叉验证
- 来源于达观杯的实践
- 来源于:kaggle恶意评价比赛的实践
1、LabelEncoder
简单来说 LabelEncoder 是对不连续的数字或者文本进行编号
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit([1,5,67,100])
le.transform([1,1,100,67,5])
输出: array([0,0,3,2,1])
2、OneHotEncoder
OneHotEncoder 用于将表示分类的数据扩维:
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder()
ohe.fit([[1],[2],[3],[4]])
ohe.transform([2],[3],[1],[4]).toarray()
输出:[ [0,1,0,0] , [0,0,1,0] , [1,0,0,0] ,[0,0,0,1] ]
正如keras中的keras.utils.to_categorical(y_train, num_classes)
来看一个笔者自己写的关于:dataframe onehot的小函数:
from sklearn.preprocessing import OneHotEncoder
import pandas as pd
#原始数据集
data = [['自有房',40,50000],
['无自有房',22,13000],
['自有房',30,30000]]
data = pd.DataFrame(data,columns=['house','age','income'])
def dataframe_one_hot(data,select_col = 'house'):
word2id = {ds:n for n,ds in enumerate(set(data[select_col]))}
id2word = {n:ds for n,ds in enumerate(set(data[select_col]))}
data[select_col] = data[select_col].map(lambda x : word2id[x] )
onehot_data = data[[select_col]]
enc = OneHotEncoder(categories='auto')
enc.fit(onehot_data)
onehot_data = enc.transform(onehot_data).toarray()
onehot_data = pd.DataFrame(onehot_data )
onehot_data.columns = [id2word[od] for od in onehot_data.columns]
#for od in onehot_data.columns:
# data[od] = onehot_data[od]
return onehot_data
onehot_data = dataframe_one_hot(data,select_col = 'house')
最后的结果如下:

.
3、sklearn.model_selection.train_test_split随机划分训练集和测试集
一般形式:
train_test_split是交叉验证中常用的函数,功能是从样本中随机的按比例选取train data和testdata,形式为:
X_train,X_test, y_train, y_test =
cross_validation.train_test_split(train_data,train_target,test_size=0.4, random_state=0)
参数解释:
- train_data:所要划分的样本特征集
- train_target:所要划分的样本结果
- test_size:样本占比,如果是整数的话就是样本的数量
- random_state:是随机数的种子。
- 随机数种子:其实就是该组随机数的编号,在需要重复试验的时候,保证得到一组一样的随机数。比如你每次都填1,其他参数一样的情况下你得到的随机数组是一样的。但填0或不填,每次都会不一样。
随机数的产生取决于种子,随机数和种子之间的关系遵从以下两个规则: - 种子不同,产生不同的随机数;种子相同,即使实例不同也产生相同的随机数。
from sklearn.cross_validation import train_test_split
train= loan_data.iloc[0: 55596, :]
test= loan_data.iloc[55596:, :]
# 避免过拟合,采用交叉验证,验证集占训练集20%,固定随机种子(random_state)
train_X,test_X, train_y, test_y = train_test_split(train,
target,
test_size = 0.2,
random_state = 0)
train_y= train_y['label']
test_y= test_y['label']
附加:shuffle 一键随机打乱:
from sklearn.utils import shuffle
shuffle([1,2,3])
>>>[1, 3, 2]
shuffle随机打乱
.
4、pipeline
本节参考与文章:用 Pipeline 将训练集参数重复应用到测试集
pipeline 实现了对全部步骤的流式化封装和管理,可以很方便地使参数集在新数据集上被重复使用。
pipeline 可以用于下面几处:
- 模块化 Feature Transform,只需写很少的代码就能将新的 Feature 更新到训练集中。
- 自动化 Grid Search,只要预先设定好使用的 Model 和参数的候选,就能自动搜索并记录最佳的 Model。
- 自动化 Ensemble Generation,每隔一段时间将现有最好的 K 个 Model 拿来做 Ensemble。
问题是要对数据集 Breast Cancer Wisconsin 进行分类,
它包含 569 个样本,第一列 ID,第二列类别(M=恶性肿瘤,B=良性肿瘤),
第 3-32 列是实数值的特征。
from pandas as pd
from sklearn.cross_validation import train_test_split
from sklearn.preprocessing import LabelEncoder
df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/'
'breast-cancer-wisconsin/wdbc.data', header=None)
# Breast Cancer Wisconsin dataset
X, y = df.values[:, 2:], df.values[:, 1]
encoder = LabelEncoder()
y = encoder.fit_transform(y)
>>> encoder.transform(['M', 'B'])
array([1, 0])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.2, random_state=0)
我们要用 Pipeline 对训练集和测试集进行如下操作:
- 先用 StandardScaler 对数据集每一列做标准化处理,(是 transformer)
- 再用 PCA 将原始的 30 维度特征压缩的 2 维度,(是 transformer)
- 最后再用模型 LogisticRegression。(是 Estimator)
- 调用 Pipeline 时,输入由元组构成的列表,每个元组第一个值为变量名,元组第二个元素是 sklearn 中的 transformer
或 Estimator。
注意中间每一步是 transformer,即它们必须包含 fit 和 transform 方法,或者 fit_transform。
最后一步是一个 Estimator,即最后一步模型要有 fit 方法,可以没有 transform 方法。
然后用 Pipeline.fit对训练集进行训练,pipe_lr.fit(X_train, y_train)
再直接用 Pipeline.score 对测试集进行预测并评分 pipe_lr.score(X_test, y_test)
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
pipe_lr = Pipeline([('sc', StandardScaler()),
('pca', PCA(n_components=2)),
('clf', LogisticRegression(random_state=1))
])
pipe_lr.fit(X_train, y_train)
print('Test accuracy: %.3f' % pipe_lr.score(X_test, y_test))
# Test accuracy: 0.947
还可以用来选择特征:
例如用 SelectKBest 选择特征,
分类器为 SVM,
anova_filter = SelectKBest(f_regression, k=5)
clf = svm.SVC(kernel='linear')
anova_svm = Pipeline([('anova', anova_filter), ('svc', clf)])
当然也可以应用 K-fold cross validation:
model = Pipeline(estimators)
seed = 7
kfold = KFold(n_splits=10, random_state=seed)
results = cross_val_score(model, X, Y, cv=kfold)
print(results.mean())
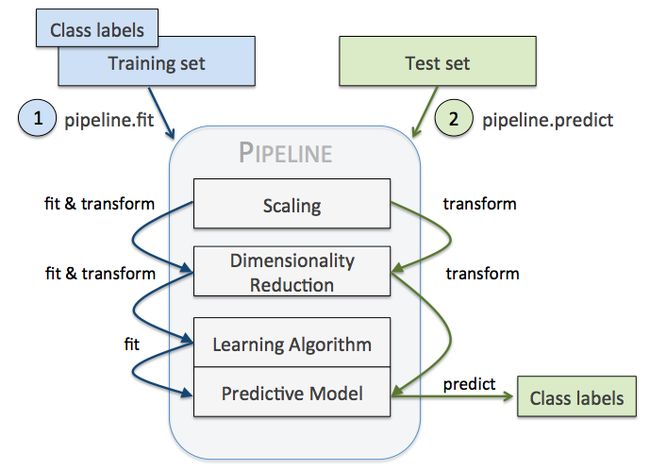
Pipeline 的工作方式
当管道 Pipeline 执行 fit 方法时,
首先 StandardScaler 执行 fit 和 transform 方法,
然后将转换后的数据输入给 PCA,
PCA 同样执行 fit 和 transform 方法,
再将数据输入给 LogisticRegression,进行训练。
参考:
python 数据处理中的 LabelEncoder 和 OneHotEncoder
sklearn 中的 Pipeline 机制
用 Pipeline 将训练集参数重复应用到测试集
5 稀疏矩阵合并
from scipy.sparse import hstack
x_train_spar = hstack([x_train_ens_s, x_train_tfidf])
hstack([X, csr_matrix(char_embed), csr_matrix(word_embed)], format='csr')
多项式PolynomialFeatures,有点类似FFM模型,可以组合特征
poly = PolynomialFeatures(degree=2, interaction_only=True, include_bias=False)
#degree控制多项式最高次数
x_train_new = poly.fit_transform(x_train)
6 sklearn中的交叉验证
X = np.array([[1, 2,5,6,6,6], [3, 4], [1, 2], [3, 4]])
y = np.array([1, 2, 3, 4])
kf = KFold(n_splits=2, random_state=None, shuffle=False)
kf.get_n_splits(X)
print(kf)
for train_index, test_index in kf.split(X):
print("TRAIN:", train_index, "TEST:", test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
>>> KFold(n_splits=2, random_state=None, shuffle=False)
>>> TRAIN: [2 3] TEST: [0 1]
>>> TRAIN: [0 1] TEST: [2 3]
KFold是将X,Y分成两份,x样本个数为4,则随机抽2次,每次2个样本。Y为长度为4的List,也对应X进行划分。
kf.split(X) 就等于[(array([2, 3]), array([0, 1])), (array([0, 1]), array([2, 3]))],这个是index,所以需要从X之中根据Index取出数据。
如果用在文本分类之中,在此举两个例子:
来源于达观杯的实践
# daguan-classify-2018-master\src\model.py
def stacking_first(train, train_y, test):
savepath = './stack_op{}_dt{}_tfidf{}/'.format(args.option, args.data_type, args.tfidf)
os.makedirs(savepath, exist_ok=True)
count_kflod = 0
num_folds = 6
kf = KFold(n_splits=num_folds, shuffle=True, random_state=10)
predict = np.zeros((test.shape[0], config.n_class))
oof_predict = np.zeros((train.shape[0], config.n_class))
scores = []
f1s = []
for train_index, test_index in kf.split(train):
kfold_X_train = {}
kfold_X_valid = {}
y_train, y_test = train_y[train_index], train_y[test_index]
kfold_X_train, kfold_X_valid = train[train_index], train[test_index]
model_prefix = savepath + 'DNN' + str(count_kflod)
if not os.path.exists(model_prefix):
os.mkdir(model_prefix)
M = 4 # number of snapshots
alpha_zero = 1e-3 # initial learning rate
snap_epoch = 16
snapshot = SnapshotCallbackBuilder(snap_epoch, M, alpha_zero)
res_model = get_model(train)
res_model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# res_model.fit(train_x, train_y, batch_size=BATCH_SIZE, epochs=EPOCH, verbose=1, class_weight=class_weight)
res_model.fit(kfold_X_train, y_train, batch_size=BATCH_SIZE, epochs=snap_epoch, verbose=1,
validation_data=(kfold_X_valid, y_test),
callbacks=snapshot.get_callbacks(model_save_place=model_prefix))
evaluations = []
for i in os.listdir(model_prefix):
if '.h5' in i:
evaluations.append(i)
preds1 = np.zeros((test.shape[0], config.n_class))
preds2 = np.zeros((len(kfold_X_valid), config.n_class))
for run, i in enumerate(evaluations):
res_model.load_weights(os.path.join(model_prefix, i))
preds1 += res_model.predict(test, verbose=1) / len(evaluations)
preds2 += res_model.predict(kfold_X_valid, batch_size=128) / len(evaluations)
predict += preds1 / num_folds
oof_predict[test_index] = preds2
accuracy = mb.cal_acc(oof_predict[test_index], np.argmax(y_test, axis=1))
f1 = mb.cal_f_alpha(oof_predict[test_index], np.argmax(y_test, axis=1), n_out=config.n_class)
print('the kflod cv is : ', str(accuracy))
print('the kflod f1 is : ', str(f1))
count_kflod += 1
scores.append(accuracy)
f1s.append(f1)
print('total scores is ', np.mean(scores))
print('total f1 is ', np.mean(f1s))
return predict
来源于:kaggle恶意评价比赛的实践
# https://github.com/sermakarevich/jigsaw-toxic-comment-classification-challenge/blob/master/bin/models.py
def predict(self):
test_number = 1
for train_i, valid_i in self.cv.split(self.x_train, self.y_train):
model = self.get_model(**self.model_kwargs)
x_train = self.x_train[train_i]
y_train = self.y_train[train_i]
x_valid = self.x_train[valid_i]
y_valid = self.y_train[valid_i]
for i in self.epochs:
model.fit(x_train, y_train, epochs = 1, batch_size = self.batch_size)
train_prediction = model.predict(x_valid, self.batch_size * 2)
print (f'test_number: {test_number}, epoch: {i}, score: {self.scorrer(y_valid, train_prediction)}')
test_prediction = model.predict(self.x_test, self.batch_size * 2)
self.train_predictions.append([train_prediction, valid_i])
self.test_predictions.append(test_prediction)
self.score.append(self.scorrer(y_valid, train_prediction))
print (f"test_number: {test_number}, avg score: {self.score[-1]}")
test_number += 1
print (np.mean(self.score))
self.train_predictions = (
pd.concat([pd.DataFrame(data=i[0],index=i[1], columns=[self.col_names])
for i in self.train_predictions]).sort_index())