多益网络2019秋招笔试题
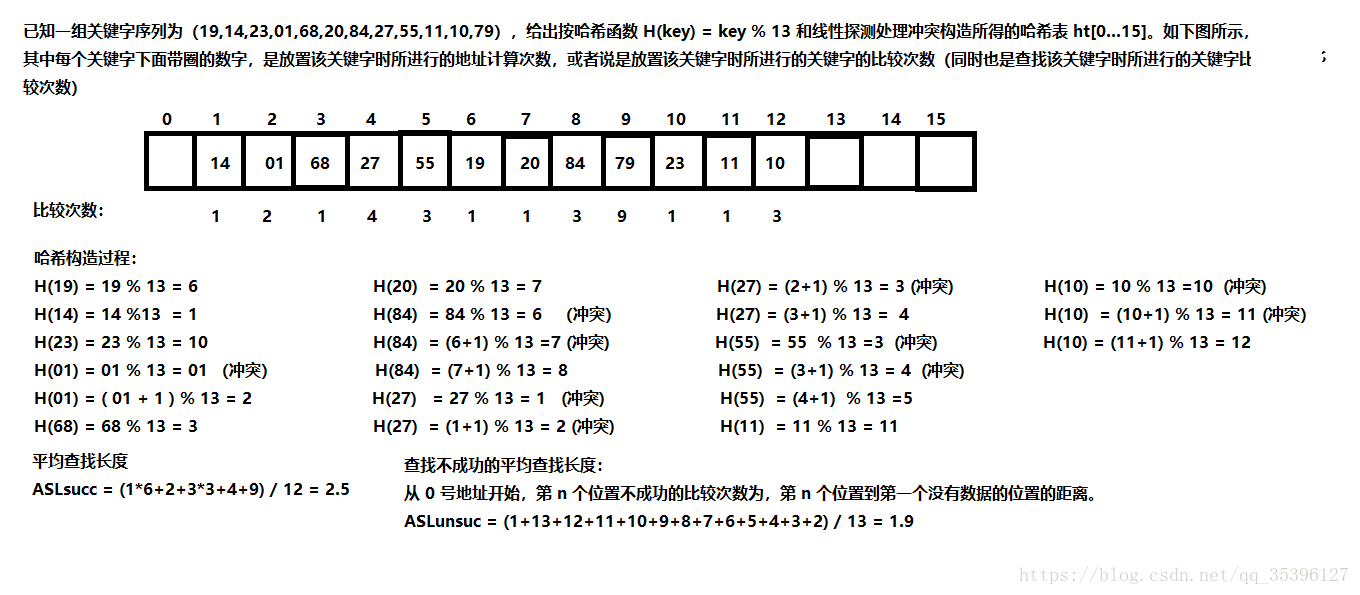
1、哈希散列值的计算平均查找长度
哈希表的构造方法:
(1)、数字分析法:事先知道关键字的集合,且每个关键字的位数比哈希表的地址码位数多时,可以从关键字中选出分布比较均匀的若干位,构成哈希地址。
(2)、平方取中法:当无法确定关键字中哪几位分布比较均匀时,可以先求出关键字的平方值的中间几位作为哈希地址
(3)、分段叠加法:按哈希表的地址位数将关键字分成位数相等的几部分(最后一部分较短),然后将这几部分相加,舍弃最高位后的结果就是该关键字的哈希地址。
(4)、除留余数法:假设哈希表长为 m,p为小于等于 m 的 最大数数,则哈希 函数为 H(k) = k%p
(5)、伪随机数为:采用一个伪随机函数作为哈希函数,即 H(key) = random(key)
哈希表处理冲突的方法:
(1)、开放定址法
(2)、再哈希法
(3)、链地址法
(4)、建立公共溢出区
哈希表的性能分析:
哈希法中影响关键字比较次数的因素有三个:哈希函数,处理冲突的方法,哈希表的装填因子。装填因子 a 的定义如下: a = 哈希表中元素的个数 / 哈希表的长度 a 可描述哈希表的装满程度。a 越小,发生冲突的可能性越小; a 越大 ,发生冲突的可能性越大。
2、堆的排序算法
3、后缀表达式
前缀表达式、中缀表达式、后缀表达式都是四则运算的表达方式,用以四则运算表达式求值,即数学表达式的求值。
前缀表达式:前缀表达式又称波兰式,前缀表达式的运算符位于操作数之前。比如:- × + 3 4 5 6。前缀表达式求值:从右至左扫描表达式,遇到数字时,将数字压入堆栈,遇到运算符时,弹出栈顶的两个数,用运算符对它们做相应的计算(栈顶元素 op 次顶元素),并将结果入栈;重复上述过程直到表达式最左端,最后运算得出的值即为表达式的结果
中缀比表达式:中缀表达式就是常见的运算表达式,如(3+4)×5-6。
后缀表达式:后缀表达式又称逆波兰表达式,与前缀表达式相似,只是运算符位于操作数之后。比如: 3 4 + 5 × 6 - 。
具体使用方法,参考博客:https://www.cnblogs.com/Hslim/p/5008460.html
4、哈夫曼编码
参考博客:https://blog.csdn.net/dongfei2033/article/details/80657360
5、二叉树的结点计算问题及性质
性质1 : 二叉树的第 i 层上至多有 2^(i-1) 个结点 (i>=1)
性质2 : 深度为 k 的二叉树至多有 2^k -1 个结点( k>=1)
性质3 : 对任意的一颗二叉树 T ,若叶子结点数为 n0,而其度数为 2 的结点数为 n2,则 n0 = n2+1
性质4 : 具有 n 个结点的完全二叉树的深度 [log2n]+1
性质 5: 如果有一颗有n个节点的完全二叉树的节点按层次序编号,对任一层的节点i(1<=i<=n)有
(1).如果i=1,则节点是二叉树的根,无双亲,如果i>1,则其双亲节点为[i/2],向下取整
(2).如果2i>n那么节点i没有左孩子,否则其左孩子为2i
(3).如果2i+1>n那么节点没有右孩子,否则右孩子为2i+1
6、关系型数据库的构成
关系型数据是指以关系数学模型来表示的数据,关系数学模型中以二维表的形式来描述数据。关系型数据库是存储在计算机上的、可共享的、有组织的关系型数据的集合。 关系模型由关系数据结构,关系操作集合、关系完整性约束三部分组成。
7、文件逻辑记录和文件物理记录
记录是文件存取操作的基本单位。逻辑记录:是按用户观点的基本存取单位。物理记录:是按外存设备观点的基本存取单位。通常逻辑记录和物理记录之间存在三种关系:(1)一个物理记录存放一个逻辑记录; (2)一个物理记录包含多个逻辑记录; (3)多个物理记录表示一个逻辑记录。
8、sql 的索引,主键,唯一索引,联合索引的区别,对数据库有什么影响
(1)索引是一种特殊的文件,它们包含数据表里的所有记录的引用指针。索引的遵照原则:
(a). 最左侧原则:表的最左侧一列,往往数据不会发生改变,不影响其他列的数据
(b).命名短小原则:索引命名过长会使索引文件变大,损耗内存。
(2). 普通索引(由关键字 KEY或 INDEX 定义得到的索引):加快数据的查询速度
(3). 唯一索引(由关键字 UNIQUE 把它定义为唯一索引):保证数据的唯一性
(4). 主键:一种特殊的唯一索引,一张表中只能定义一个主键索引,用来标识唯一一条数据,用 PRIMARY KEY 创建
(5). 联合索引:索引可以覆盖多个数据列,如像 INDEX 索引就是联合索引
索引可以极大的提高查询访问速度,但是会降低插入,删除,更新表的速度,应为在执行写的操作的时候还要操作索引文件。
9、TCP 传输的时候怎么保证传输的可靠性
参考我的往期博客:
https://blog.csdn.net/qq_35396127/article/details/80847189
10、如何确定UDP传输中是数据包是否被接收方正确接收。
可以在每个数据包中插入一个唯一的ID,比如timestamp或者递增的int。 发送方在发送数据时将此ID和发送时间记录在本地。 接收方在收到数据后将ID再发给发送方作为回应 发送方如果收到回应,则知道接收方已经收到相应的数据包;如果在指定时间内没有收到回应,则数据包可能丢失,需要重复上面的过程重新发送一次,直到确定对方收到。
11、数据库的安全性:指保护数据库,防止不合法的使用造成的数据泄露、更改或破坏。
SQL Server 2000 的安全性机制由四层构成
第一层:操作系统的登录
第二层(服务器安全管理):SQL Server的登录————特殊账户sa
第三层(数据库安全管理):数据库的访问权————成为数据库用户
第四层(数据库对象安全管理):数据库对象(表、视图等)的访问权———数据库用户获得角色
12、事务隔离级别是由谁实现的?(数据库系统)
在数据库操作中,为了有效保证并发读取数据的正确性,提出的事务隔离级别;为了解决更新丢失,脏读,不可重读(包括虚读和幻读)等问题在标准SQL规范中,定义了4个事务隔离级别,分别为未授权读取,也称为读未提交(read uncommitted);授权读取,也称为读提交(read committed);可重复读取(repeatable read);序列化(serializable).
编程题:
幸福的数字是由以下过程定义的数字:从任何正整数开始,将数字替换为数字的平方和,并重复该过程,直到数字等于1(将保留在哪里),或者循环 一个不包括在内的循环的循环中,这个过程以1结尾的数字是快乐的数字。例如19是幸运数字 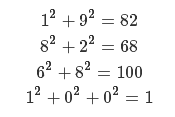 给定一个数,计算是不是幸运数。
给定一个数,计算是不是幸运数。
解题思路:
/*
while 该位上的数不为0{
1.计算给定数的每位上的数
2.计算其每位数上的平方和
}
如果平方和不为1,返回重新计算该平方和的各个位置上数的新的平方和,1000次后还不为1,可能不是幸运数;
如果平方和为1,return true
*/
public class test
{
public static void main(String[] args)
{
int input = 101;
System.out.println(isHappy(input));
}
static boolean isHappy(int n)
{
int cnt = 0, k = n;
while (k != 1 && cnt < 1000)
{
int tmp = 0;
while (k != 0)
{
tmp += (k % 10) * (k % 10);
k /= 10;
}
k = tmp;
cnt++;
}
return k == 1;
}
}转载地址:https://blog.csdn.net/qq_35396127/article/details/80820502