机器学习实战--对亚马逊森林卫星照片进行分类(1)
一个写代码的滚青,公众号: 程序员小王。

写在前面:
今天的文章是自己翻译的一篇文章,由于水平有限,在不影响阅读且忠于原文情况下对文中部分内容做了修改,原文篇幅太长我准备将文章分成三次发。
如何建立卫星照片多标签分类模型
该卫星数据集已经成为一个标准的计算机视觉基准,涉及对亚马逊热带雨林的内容卫星照片进行分类或标记。
该数据集是Kaggle网站数据科学竞赛的基础,它可以作为学习和实践如何开发、评估和使用卷积深度学习神经网络从头开始图像分类的基础。
这包括如何开发一个强大的测试工具来估计模型的性能,如何探索模型的改进,以及如何保存模型,然后加载它以对新数据进行预测。
在本教程中,您将了解如何开发卷积神经网络来对亚马逊热带雨林的卫星照片进行分类。
完成本教程后,您将了解:
如何加载和准备亚马逊热带雨林的卫星照片进行建模。
如何从头开发卷积神经网络进行照片分类,提高模型性能。
如何开发最终模型并使用它来对新数据进行临时预测。
让我们开始吧。

教程概述
本教程分为七个部分,分别是:
- 卫星数据集简介
- 如何为建模准备数据
- 模型评估措施
- 如何评估基本模型
- 如何提高模型性能
- 如何使用转移学习
- 如何最终确定模型并做出预测
卫星数据集简介
2017年,“ 卫星:从太空了解亚马逊”(https://www.kaggle.com/c/planet-understanding-the-amazon-from-space)比赛在Kaggle举行。
比赛涉及对从巴西亚马逊热带雨林空间拍摄的小方块卫星图像进行分类,分为17类,如“农业””和“水”。鉴于竞争的名称,数据集通常简称为“ 卫星数据集 ”。
彩色图像以TIFF和JPEG格式为主,大小为256×256像素。在训练数据集中总共提供了40,779张图像,并且在测试集中提供了40,669张图像,需进行预测。
问题是多标签图像分类任务的示例,其中必须为每个标签预测一个或多个类标签。这与多类分类不同,其中每个图像从许多类中分配一个。
为训练数据集中的每个图像提供了多个类标签,其中附带的文件将图像文件名映射到字符串类标签。
比赛大约进行了四个月(2017年4月至7月),共有938个团队参加,围绕使用数据准备,数据增强和卷积神经网络的使用进行了大量讨论。
冠军由一位名为“bestfitting”的选手赢得,在66%的测试数据集中,公开排行榜F-beta得分为0.93398,在34%的测试数据集中,私人排行榜F-beta得分为0.93317。他的模型在“卫星:从太空中了解亚马逊,第一名获胜者的访谈”(http://blog.kaggle.com/2017/10/17/planet-understanding-the-amazon-from-space-1st-place-winners-interview/)一文中进行了描述,并涉及大量模型的评估和组合,这些模型主要是具有转移学习的卷积神经网络。
这是一个具有挑战性的比赛,而且数据集仍然是免费的(如果你有一个kaggle帐户),并为使用卷积神经网络进行卫星数据集的图像分类提供了一个很好的实例。
如何为建模准备数据
第一步是下载数据集。
要下载数据文件,您必须拥有Kaggle帐户。如果您没有Kaggle帐户,可以在此处创建一个(https://www.kaggle.com)
数据集可以从卫星数据页面下载(https://www.kaggle.com/c/planet-understanding-the-amazon-from-space/data)
本教程所需的特定文件如下:
train-jpg.tar.7z(600MB)
train_v2.csv.zip(159KB)
要下载给定的文件,请单击文件旁边的“下载”按钮的小图标(当您用鼠标悬停在该文件上时),如下图所示。
下载数据集文件后,必须解压缩它们。可以使用您喜欢的解压缩程序解压缩CSV文件的.zip文件。
包含JPEG图像的7z文件也可以使用您喜欢的解压缩程序解压缩。如果这是一种新的zip格式,您可能需要其他软件,例如MacOS上的“ Unarchiver ”软件。
例如,在大多数基于POSIX的工作站的命令行上,可以使用p7zip和tar文件解压缩.7z文件,如下所示:

解压缩后,您将在当前工作目录中拥有CSV文件和目录,如下所示:
![]()
检查文件夹,您将看到许多jpeg文件。
检查train_v2.csv文件,您将看到训练数据集(train-jpg/)中jpeg文件的映射以及它们与类标签的映射,每个类标签由一个空格隔开; 例如:

必须在建模之前准备数据集。
我们至少可以探索两种方法; 它们是:内存方法和渐进式加载方法。
准备数据集,目的是在拟合模型时将整个训练数据集加载到内存中。这将需要具有足够RAM的机器来保存所有图像(例如32GB或64GB的RAM),例如Amazon EC2实例,这样训练模型将显着更快。
或者,可以在训练期间按批次按需加载数据集。这需要开发数据生成器。训练模型会明显变慢,但可以在RAM较少的工作站(例如8GB或16GB)上进行训练。
在本教程中,我们将使用前一种方法。因此,我强烈建议您在具有足够RAM和访问GPU的Amazon EC2实例上运行本教程,例如Deep Learning AMI(Amazon Linux)AMI上价格合理的p3.2xlarge实例,每小时大约花费3美元。有关如何设置AmazonEC2实例进行深度学习的逐步教程,请参阅以下文章:
https://machinelearningmastery.com/develop-evaluate-large-deep-learning-models-keras-amazon-web-services/
如果使用EC2实例不适合您,那么我将在下面提供有关如何进一步减小训练数据集大小的方法,以便它适合您工作站的内存,让您可以完成本教程。
可视化数据集
第一步是检查训练数据集中的一些图像。
我们可以通过加载一些图像并使用Matplotlib在一个图中绘制多个图像来实现。
下面列出了完整的示例。
# plot the first 9 images in the planet dataset
from matplotlib import pyplot
from matplotlib.image import imread
# define location of dataset
folder = 'train-jpg/'
# plot first few images
for i in range(9):
# define subplot
pyplot.subplot(330 + 1 + i)
# define filename
filename = folder + 'train_' + str(i) + '.jpg'
# load image pixels
image = imread(filename)
# plot raw pixel data
pyplot.imshow(image)
# show the figure
pyplot.show()
运行该示例会创建一个图形,用于绘制训练数据集中的前九个图像。
我们可以看到这些图像确实是雨林的卫星照片。有些显示出明显的雾霾,有些则显示树木,道路,河流和其他结构。
这些图表明,建模可能受益于数据扩充以及使图像中的特征更加可见的简单技术。

创建映射
下一步涉及了解可能分配给每个图像的标签。
我们可以使用Pandas的read_csv()函数直接加载训练数据集(train_v2.csv)的CSV映射文件。
下面列出了完整的示例。
# load and summarize the mapping file for the planet dataset
from pandas import read_csv
# load file as CSV
filename = 'train_v2.csv'
mapping_csv = read_csv(filename)
# summarize properties
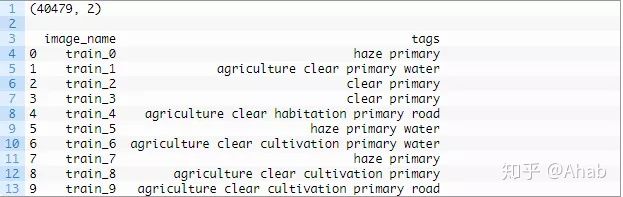
print(mapping_csv.shape)
print(mapping_csv[:10])首先运行该示例我们可以看到文件中确实有40,479个训练图像。
接下来,汇总文件的前10行。我们可以看到文件的第二列包含一个以空格分隔的标记列表,以分配给每个图像。
我们需要将所有已知标记的集合分配给图像,以及应用于每个标记的唯一且一致的整数。这使得我们可以利用独热热编码为每个图像开发目标矢量,例如,对于应用于图像的每个标签,具有全零的矢量和索引处的一个矢量。
这可以通过循环遍历“tags”列中的每一行,按空格分割标记,并将它们存储在一个集合中来实现。然后我们将拥有一组所有已知的标签。例如:
# create a set of labels
labels = set()
for i in range(len(mapping_csv)):
# convert spaced separated tags into an array of tags
tags = mapping_csv['tags'][i].split(' ')
# add tags to the set of known labels
labels.update(tags)
# convert set of labels to a list to list
labels = list(labels)
# order set alphabetically
labels.sort()
我们可以创建一个将标签映射到整数的字典,以便我们可以对训练数据集进行编码以进行建模。
我们还可以使用从整数到字符串标记值的反向映射创建字典,因此稍后当模型进行预测时,我们可以将其转换为可读的内容。
# dict that maps labels to integers, and the reverse
labels_map = {labels[i]:i for i in range(len(labels))}
inv_labels_map = {i:labels[i] for i in range(len(labels))}
我们可以将所有这些绑定到一个名为create_tag_mapping()的便捷函数中,该函数将获取包含train_v2.csv数据的加载DataFrame 并返回映射和逆映射字典。
# create a mapping of tags to integers given the loaded mapping file
def create_tag_mapping(mapping_csv):
# create a set of all known tags
labels = set()
for i in range(len(mapping_csv)):
# convert spaced separated tags into an array of tags
tags = mapping_csv['tags'][i].split(' ')
# add tags to the set of known labels
labels.update(tags)
# convert set of labels to a list to list
labels = list(labels)
# order set alphabetically
labels.sort()
# dict that maps labels to integers, and the reverse
labels_map = {labels[i]:i for i in range(len(labels))}
inv_labels_map = {i:labels[i] for i in range(len(labels))}
return labels_map, inv_labels_map
我们可以测试这个函数,看看我们有多少和哪些标签可以使用; 下面列出了完整的示例。
from pandas import read_csv
# create a mapping of tags to integers given the loaded mapping file
def create_tag_mapping(mapping_csv):
# create a set of all known tags
labels = set()
for i in range(len(mapping_csv)):
# convert spaced separated tags into an array of tags
tags = mapping_csv['tags'][i].split(' ')
# add tags to the set of known labels
labels.update(tags)
# convert set of labels to a list to list
labels = list(labels)
# order set alphabetically
labels.sort()
# dict that maps labels to integers, and the reverse
labels_map = {labels[i]:i for i in range(len(labels))}
inv_labels_map = {i:labels[i] for i in range(len(labels))}
return labels_map, inv_labels_map
# load file as CSV
filename = 'train_v2.csv'
mapping_csv = read_csv(filename)
# create a mapping of tags to integers
mapping, inv_mapping = create_tag_mapping(mapping_csv)
print(len(mapping))
print(mapping)
return labels_map, inv_labels_map
运行该示例,我们可以看到数据集中总共有17个标记。
我们还可以看到映射字典,其中每个标记都被赋予一致且唯一的整数。标签似乎是我们在给定卫星图像中可能看到的特征类型的合理描述。
作为进一步的扩展,探索标签在图像之间的分布,看看它们在训练数据集中的分配或使用是平衡的还是不平衡的,可能会很有趣。这有助于进一步了解预测问题的难度。
17{'agriculture': 0, 'artisinal_mine': 1, 'bare_ground': 2, 'blooming': 3, 'blow_down': 4, 'clear': 5, 'cloudy': 6, 'conventional_mine': 7, 'cultivation': 8, 'habitation': 9, 'haze': 10, 'partly_cloudy': 11, 'primary': 12, 'road': 13, 'selective_logging': 14, 'slash_burn': 15, 'water': 16}
我们还需要将训练集文件名映射到图像的标签。
这是一个简单的字典,其中图像的文件名为键,标签列为值。
下面的create_file_mapping()实现了这一点,同时将加载的DataFrame作为参数,并返回带有作为列表存储的每个文件名的标记值的映射。
# create a mapping of filename to tags
def create_file_mapping(mapping_csv):
mapping = dict()
for i in range(len(mapping_csv)):
name, tags = mapping_csv['image_name'][i], mapping_csv['tags'][i]
mapping[name] = tags.split(' ')
return mapping
我们现在可以准备数据集的图像组件。
创建内存数据集
我们需要能够将JPEG图像加载到内存中。
这可以通过枚举train-jpg/文件夹中的所有文件来实现。Keras提供一个简单的API通过从文件加载图像load_img()函数,并将其覆盖于经由一个NumPy的矩阵img_to_array()函数。
作为加载图像的一部分,我们可以强制缩小尺寸以节省内存并加快培训速度。在这种情况下,我们将图像的大小从256×256减半到128×128。我们还将像素值存储为无符号的8位整数(例如,0到255之间的值)。
# load image
photo = load_img(filename, target_size=(128,128))
# convert to numpy array
photo = img_to_array(photo, dtype='uint8')
照片将代表模型的输入,但我们需要输出照片。
然后,我们可以使用没有扩展名的文件名检索加载图像的标签,使用前面部分中开发的create_file_mapping()函数准备的文件名到标签映射。
# get tags
tags = file_mapping(filename[:-4])
我们需要对图像的标签进行独热编码。这意味着我们将需要一个17元素的向量,每个标签都有一个值。我们可以获得从标记映射到通过上一节中开发的create_tag_mapping()函数创建的整数的1值的位置索引。
下面的one_hot_encode()函数实现了这一点,给定了一个图像标签列表以及标签到整数作为参数的映射,它将返回一个17元素的NumPy数组,该数组描述了一张照片的标签的独热编码。
# create a one hot encoding for one list of tags
def one_hot_encode(tags, mapping):
# create empty vector
encoding = zeros(len(mapping), dtype='uint8')
# mark 1 for each tag in the vector
for tag in tags:
encoding[mapping[tag]] = 1
return encoding
我们现在可以为整个训练数据集加载输入(照片)和输出(一个热编码矢量)元素。
下面的load_dataset()函数实现了这一点,给出了JPEG图像的路径,文件到标签的映射,以及标签到整数作为输入的映射; 它将为X和y元素返回NumPy数组以进行建模。
# load all images into memory
def load_dataset(path, file_mapping, tag_mapping):
photos, targets = list(), list()
# enumerate files in the directory
for filename in listdir(folder):
# load image
photo = load_img(path + filename, target_size=(128,128))
# convert to numpy array
photo = img_to_array(photo, dtype='uint8')
# get tags
tags = file_mapping[filename[:-4]]
# one hot encode tags
target = one_hot_encode(tags, tag_mapping)
# store
photos.append(photo)
targets.append(target)
X = asarray(photos, dtype='uint8')
y = asarray(targets, dtype='uint8')
return X, y
注意:这会将整个训练数据集加载到内存中,并且可能需要至少128x128x3 x 40,479图像x 8位,或大约2GBRAM才能保存已加载的照片。
如果此处耗尽内存,或稍后在建模时(当像素为16或32位时),尝试将加载的照片的大小减小到32×32和/或在加载20,000张照片后停止循环。
加载后,我们可以将这些NumPy数组保存到文件中供以后使用。
我们可以使用save()或savez()函数来保存数组方向。相反,我们将使用savez_compressed()函数以压缩格式将两个数组保存在一个函数调用中,从而节省了几兆字节。加载较小图像的阵列将比在建模期间每次加载原始JPEG图像快得多。
# save both arrays to one file in compressed format
savez_compressed('planet_data.npz', X, y)
我们可以将所有这些联系在一起,为内存建模准备卫星数据集,并将其保存到新的单个文件中,以便稍后快速加载。
下面列出了完整的示例。
# load and prepare planet dataset and save to file
from os import listdir
from numpy import zeros
from numpy import asarray
from numpy import savez_compressed
from pandas import read_csv
from keras.preprocessing.image import load_img
from keras.preprocessing.image import img_to_array
# create a mapping of tags to integers given the loaded mapping file
def create_tag_mapping(mapping_csv):
# create a set of all known tags
labels = set()
for i in range(len(mapping_csv)):
# convert spaced separated tags into an array of tags
tags = mapping_csv['tags'][i].split(' ')
# add tags to the set of known labels
labels.update(tags)
# convert set of labels to a list to list
labels = list(labels)
# order set alphabetically
labels.sort()
# dict that maps labels to integers, and the reverse
labels_map = {labels[i]:i for i in range(len(labels))}
inv_labels_map = {i:labels[i] for i in range(len(labels))}
return labels_map, inv_labels_map
# create a mapping of filename to a list of tags
def create_file_mapping(mapping_csv):
mapping = dict()
for i in range(len(mapping_csv)):
name, tags = mapping_csv['image_name'][i], mapping_csv['tags'][i]
mapping[name] = tags.split(' ')
return mapping
# create a one hot encoding for one list of tags
def one_hot_encode(tags, mapping):
# create empty vector
encoding = zeros(len(mapping), dtype='uint8')
# mark 1 for each tag in the vector
for tag in tags:
encoding[mapping[tag]] = 1
return encoding
# load all images into memory
def load_dataset(path, file_mapping, tag_mapping):
photos, targets = list(), list()
# enumerate files in the directory
for filename in listdir(folder):
# load image
photo = load_img(path + filename, target_size=(128,128))
# convert to numpy array
photo = img_to_array(photo, dtype='uint8')
# get tags
tags = file_mapping[filename[:-4]]
# one hot encode tags
target = one_hot_encode(tags, tag_mapping)
# store
photos.append(photo)
targets.append(target)
X = asarray(photos, dtype='uint8')
y = asarray(targets, dtype='uint8')
return X, y
# load the mapping file
filename = 'train_v2.csv'
mapping_csv = read_csv(filename)
# create a mapping of tags to integers
tag_mapping, _ = create_tag_mapping(mapping_csv)
# create a mapping of filenames to tag lists
file_mapping = create_file_mapping(mapping_csv)
# load the jpeg images
folder = 'train-jpg/'
X, y = load_dataset(folder, file_mapping, tag_mapping)
print(X.shape, y.shape)
# save both arrays to one file in compressed format
savez_compressed('planet_data.npz', X, y
首先运行该示例将加载整个数据集并汇总形状。我们可以确认输入样本(X)是128×128个彩色图像,输出样本是17个元素矢量。
在运行结束时,保存单个文件“ planet_data.npz ”,其中包含大小约为1.2千兆字节的数据集,由于压缩而节省了大约700兆字节。
![]()
稍后可以使用load()函数轻松加载数据集,如下所示:
# load prepared planet dataset
from numpy import load
data = load('planet_data.npz')
X, y = data['arr_0'], data['arr_1']
print('Loaded: ', X.shape, y.shape)
运行此示例确认数据集已正确加载。
![]()
未完待续...
推荐阅读:
在Python中开始使用 XGBoost的7步迷你课程
第 01 课:梯度提升简介
第 02 课:XGBoost 简介
第 03 课:开发您的第一个 XGBoost 模型
隔三岔五聊算法之极小极大算法