机器学习实战--对亚马逊森林卫星照片进行分类(2)
一个写代码的滚青,公众号: 程序员小王。

前文回顾:
机器学习实战--对亚马逊森林卫星照片进行分类(1)
模型评估措施
在我们开始建模之前,我们必须选择一个模型的性能指标。
分类准确性通常适用于二进制分类任务,每个类中具有平衡数量的示例。在这种情况下,我们既不使用二进制或多类分类任务; 相反,它是一个多标签分类任务,标签数量不均衡,有些使用比其他标签更重要。因此,Kaggle比赛组织选择了F-beta指标,特别是F2得分。这是与F1分数(也称为F-measure)相关的度量。
您可能还记得查准率和查全率计算如下:

查准率(Precision ratio,简称为P),查准率反映检索准确性,其补数就是误检率。查全率(Recall ratio,简称为R查全率反映检索全面性。
F1是这两个分数的平均值,在评估不平衡数据集上模型的性能时,F1优于准确度,对于最差和最佳可能分数,值介于0和1之间
![]()
F-beta指标是F1的推广,允许引入称为beta的术语,在计算均值时权衡查准率与查全率的重要性
![]()
beta的常见值是2,这是比赛中使用的值,其中查全率的值是精度的两倍。这通常被称为F2分数。
正类和负类的概念只适用于二元分类问题。当我们预测多个类时,以one vs. rest的方式计算每个类的正、负和相关术语的概念,然后在每个类中求平均值。
scikit-learn库通过fbeta_score()函数提供了F-beta的实现。我们可以调用这个函数来评估一组预测,并指定beta值为2,“average”参数集为“samples”。
![]()
例如,我们可以在准备好的数据集上测试它。
我们可以将加载的数据集分割成单独的训练和测试数据集,我们可以使用这些数据集训练和评估此问题的模型。这可以使用train_test_split()和指定一个“random_state”参数来实现,这样每次运行代码时都会给出相同的数据分割。
我们将使用70%的训练集和30%的测试集。
![]()
下面的load_dataset()函数通过加载保存的数据集,将其分解为训练和测试组件,并返回准备使用的组件来实现。
# load train and test dataset
def load_dataset():
# load dataset
data = load('planet_data.npz')
X, y = data['arr_0'], data['arr_1']
# separate into train and test datasets
trainX, testX, trainY, testY = train_test_split(X, y, test_size=0.3, random_state=1)
print(trainX.shape, trainY.shape, testX.shape, testY.shape)
return trainX, trainY, testX, testY
然后,我们可以对独热编码矢量中的所有类或所有1个值进行预测。
# make all one predictions
train_yhat = asarray([ones(trainY.shape[1]) for _ in range(trainY.shape[0])])
test_yhat = asarray([ones(testY.shape[1]) for _ in range(testY.shape[0])])
然后可以使用scikit-learn fbeta_score()函数对预测进行评估,该函数在训练和测试数据集中使用真实值。
train_score = fbeta_score(trainY, train_yhat, 2, average='samples')
test_score = fbeta_score(testY, test_yhat, 2, average='samples')
将这些结合在一起,下面列出了完整的示例。
# test f-beta score
from numpy import load
from numpy import ones
from numpy import asarray
from sklearn.model_selection import train_test_split
from sklearn.metrics import fbeta_score
# load train and test dataset
def load_dataset():
# load dataset
data = load('planet_data.npz')
X, y = data['arr_0'], data['arr_1']
# separate into train and test datasets
trainX, testX, trainY, testY = train_test_split(X, y, test_size=0.3, random_state=1)
print(trainX.shape, trainY.shape, testX.shape, testY.shape)
return trainX, trainY, testX, testY
# load dataset
trainX, trainY, testX, testY = load_dataset()
# make all one predictions
train_yhat = asarray([ones(trainY.shape[1]) for _ in range(trainY.shape[0])])
test_yhat = asarray([ones(testY.shape[1]) for _ in range(testY.shape[0])])
# evaluate predictions
train_score = fbeta_score(trainY, train_yhat, 2, average='samples')
test_score = fbeta_score(testY, test_yhat, 2, average='samples')
print('All Ones: train=%.3f, test=%.3f' % (train_score, test_score))
运行此示例首先加载准备好的数据集,然后将其拆分为训练集和测试集,并报告准备好的数据集的形状。我们可以看到,我们在训练数据集中有超过28,000个示例,在测试集中有超过12,000个示例。
接下来,准备所有预测,然后评估并报告分数。我们可以看到两个数据集的全部预测结果得分约为0.48。

我们将在Keras中使用F-beta分数计算版本作为指标。
Keras用于在库2.0版之前支持二进制分类问题(2个类)的度量标准; 我们可以在这里看到这个旧版本的代码:metrics.py。此代码可用作定义可与Keras一起使用的新度量函数的基础。该功能的一个版本也在名为“Keras的F-beta得分”的Kaggle内核中提出。下面列出了这个新功能。
from keras import backend
# calculate fbeta score for multi-class/label classification
def fbeta(y_true, y_pred, beta=2):
# clip predictions
y_pred = backend.clip(y_pred, 0, 1)
# calculate elements
tp = backend.sum(backend.round(backend.clip(y_true * y_pred, 0, 1)), axis=1)
fp = backend.sum(backend.round(backend.clip(y_pred - y_true, 0, 1)), axis=1)
fn = backend.sum(backend.round(backend.clip(y_true - y_pred, 0, 1)), axis=1)
# calculate precision
p = tp / (tp + fp + backend.epsilon())
# calculate recall
r = tp / (tp + fn + backend.epsilon())
# calculate fbeta, averaged across each class
bb = beta ** 2
fbeta_score = backend.mean((1 + bb) * (p * r) / (bb * p + r + backend.epsilon()))
return fbeta_score
它可以在Keras中编译模型时使用,通过metrics参数指定; 例如:
![]()
我们可以测试这个新函数,并将结果与scikit-learn函数进行比较,如下所示。
# compare f-beta score between sklearn and keras
from numpy import load
from numpy import ones
from numpy import asarray
from sklearn.model_selection import train_test_split
from sklearn.metrics import fbeta_score
from keras import backend
# load train and test dataset
def load_dataset():
# load dataset
data = load('planet_data.npz')
X, y = data['arr_0'], data['arr_1']
# separate into train and test datasets
trainX, testX, trainY, testY = train_test_split(X, y, test_size=0.3, random_state=1)
print(trainX.shape, trainY.shape, testX.shape, testY.shape)
return trainX, trainY, testX, testY
# calculate fbeta score for multi-class/label classification
def fbeta(y_true, y_pred, beta=2):
# clip predictions
y_pred = backend.clip(y_pred, 0, 1)
# calculate elements
tp = backend.sum(backend.round(backend.clip(y_true * y_pred, 0, 1)), axis=1)
fp = backend.sum(backend.round(backend.clip(y_pred - y_true, 0, 1)), axis=1)
fn = backend.sum(backend.round(backend.clip(y_true - y_pred, 0, 1)), axis=1)
# calculate precision
p = tp / (tp + fp + backend.epsilon())
# calculate recall
r = tp / (tp + fn + backend.epsilon())
# calculate fbeta, averaged across each class
bb = beta ** 2
fbeta_score = backend.mean((1 + bb) * (p * r) / (bb * p + r + backend.epsilon()))
return fbeta_score
# load dataset
trainX, trainY, testX, testY = load_dataset()
# make all one predictions
train_yhat = asarray([ones(trainY.shape[1]) for _ in range(trainY.shape[0])])
test_yhat = asarray([ones(testY.shape[1]) for _ in range(testY.shape[0])])
# evaluate predictions with sklearn
train_score = fbeta_score(trainY, train_yhat, 2, average='samples')
test_score = fbeta_score(testY, test_yhat, 2, average='samples')
print('All Ones (sklearn): train=%.3f, test=%.3f' % (train_score, test_score))
# evaluate predictions with keras
train_score = fbeta(backend.variable(trainY), backend.variable(train_yhat)).eval(session=backend.get_session())
test_score = fbeta(backend.variable(testY), backend.variable(test_yhat)).eval(session=backend.get_session())
print('All Ones (keras): train=%.3f, test=%.3f' % (train_score, test_score))
运行该示例像以前一样加载数据集,在这种情况下,使用scikit-learn和Keras计算F-beta。我们可以看到两个函数都实现了相同的结果。

我们可以使用测试集上0.483的分数作为一个简单的预测,后面几节中的所有模型都可以对其进行比较,以确定它们是否可用。
如何评估Baseline Model
现在,我们准备为准备好行星数据集开发和评估一个基准卷积神经网络模型。
我们将设计一个VGG-type结构的Baseline模型。这是一组卷积层,带有小的3×3个过滤器,然后是一个最大池化层,随着每个块的添加,这种模式不断重复,过滤器的数量增加一倍。
具体来说,每个block将有两个卷积层,3×3过滤器, ReLU激活,具有相同填充的权重初始化填充相同,确保输出特征映射具有相同的宽度和高度。然后是带有3×3内核的最大池层。其中三个块将分别与32、64和128个过滤器一起使用。
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(128, 128, 3)))
model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
最终汇集层的输出将被展平并送到完全连接的层以进行解释,然后最终到达输出层以进行预测。
该模型必须为每个输出类生成一个17个元素的向量,其预测值介于0和1之间。
model.add(Flatten())
model.add(Dense(128, activation='relu', kernel_initializer='he_uniform'))
model.add(Dense(17, activation='sigmoid'))
如果这是一个多类分类问题,我们将使用softmax激活函数和分类交叉熵损失函数。这不适用于多标签分类,因为我们希望模型输出多个1值,而不是单个1值。在这种情况下,我们将在输出层使用sigmoid激活函数并优化二元交叉熵损失函数。
对模型进行优化,采用小批量随机梯度下降法,保守学习率为0.01,动量为0.9,训练过程中跟踪“fbeta”指标。
# compile model
opt = SGD(lr=0.01, momentum=0.9)
model.compile(optimizer=opt, loss='binary_crossentropy', metrics=[fbeta])
下面的define_model()函数将所有这些联系在一起并参数化输入和输出的形状,以防您想要通过更改这些值或在其他数据集上重用代码进行实验。
该函数将返回一个准备好适合卫星数据集的模型。
# define cnn model
def define_model(in_shape=(128, 128, 3), out_shape=17):
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=in_shape))
model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu', kernel_initializer='he_uniform'))
model.add(Dense(out_shape, activation='sigmoid'))
# compile model
opt = SGD(lr=0.01, momentum=0.9)
model.compile(optimizer=opt, loss='binary_crossentropy', metrics=[fbeta])
return model
选择此模型作为基准模型有点武断。您可能希望探索具有较少层数或不同学习速率的其他基线模型。
我们可以使用上一节中开发的load_dataset()函数来加载数据集并将其拆分为训练集和测试集,以便拟合和评估已定义的模型。
在拟合模型之前,将对像素值进行归一化。我们将通过定义ImageDataGenerator实例并将rescale参数指定为1.0 / 255.0 来实现此目的。这会将每批次的像素值标准化为32位浮点值,这可能比在内存中一次重新调整所有像素值的内存效率更高。
# create data generator
datagen = ImageDataGenerator(rescale=1.0/255.0)
我们可以从这个数据生成器为训练和测试集创建迭代器,在这种情况下,我们将使用相对较大批量的128个图像来加速学习。
# prepare iterators
train_it = datagen.flow(trainX, trainY, batch_size=128)
test_it = datagen.flow(testX, testY, batch_size=128)
然后可以使用训练迭代器拟合定义的模型,并且可以使用测试迭代器在每个时期结束时评估测试数据集。该模型适合50 epochs.
# fit model
history = model.fit_generator(train_it, steps_per_epoch=len(train_it),
validation_data=test_it, validation_steps=len(test_it), epochs=50, verbose=0)
一旦拟合成功,我们就可以在测试数据集上计算最终的损失和F-beta分数来估计模型。
# evaluate model
loss, fbeta = model.evaluate_generator(test_it, steps=len(test_it), verbose=0)
print('> loss=%.3f, fbeta=%.3f' % (loss, fbeta))
所述fit_generator()调用,以适应模型函数返回一个包含记录在训练和测试数据集的每个epoch的损失和F-β分数的字典。我们可以创建这些痕迹的图表,以便深入了解模型的学习动态。
在()summarize_diagnostics函数将创建从该一个数字记录的历史数据与一个情节表示损失,另一个用于在训练上的数据集(蓝线)和测试数据集的每个训练时期结束时的模型在F-β分数(橙色线)。
创建的图形将保存到PNG文件中,文件名与脚本的扩展名为“ _plot.png ”相同。这允许将相同的测试工具与多个不同的脚本文件一起用于不同的模型配置,从而将学习曲线保存在单独的文件中
# plot diagnostic learning curves
def summarize_diagnostics(history):
# plot loss
pyplot.subplot(211)
pyplot.title('Cross Entropy Loss')
pyplot.plot(history.history['loss'], color='blue', label='train')
pyplot.plot(history.history['val_loss'], color='orange', label='test')
# plot accuracy
pyplot.subplot(212)
pyplot.title('Fbeta')
pyplot.plot(history.history['fbeta'], color='blue', label='train')
pyplot.plot(history.history['val_fbeta'], color='orange', label='test')
# save plot to file
filename = sys.argv[0].split('/')[-1]
pyplot.savefig(filename + '_plot.png')
pyplot.close()
我们可以将它们联系在一起并定义一个函数run_test_harness()来驱动测试工具,包括数据的加载和准备以及模型的定义,拟合和评估。
# run the test harness for evaluating a model
def run_test_harness():
# load dataset
trainX, trainY, testX, testY = load_dataset()
# create data generator
datagen = ImageDataGenerator(rescale=1.0/255.0)
# prepare iterators
train_it = datagen.flow(trainX, trainY, batch_size=128)
test_it = datagen.flow(testX, testY, batch_size=128)
# define model
model = define_model()
# fit model
history = model.fit_generator(train_it, steps_per_epoch=len(train_it),
validation_data=test_it, validation_steps=len(test_it), epochs=50, verbose=0)
# evaluate model
loss, fbeta = model.evaluate_generator(test_it, steps=len(test_it), verbose=0)
print('> loss=%.3f, fbeta=%.3f' % (loss, fbeta))
# learning curves
summarize_diagnostics(history)
下面列出了评估卫星数据集上基准模型的完整示例。
# baseline model for the planet dataset
import sys
from numpy import load
from matplotlib import pyplot
from sklearn.model_selection import train_test_split
from keras import backend
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers import Dense
from keras.layers import Flatten
from keras.optimizers import SGD
# load train and test dataset
def load_dataset():
# load dataset
data = load('planet_data.npz')
X, y = data['arr_0'], data['arr_1']
# separate into train and test datasets
trainX, testX, trainY, testY = train_test_split(X, y, test_size=0.3, random_state=1)
print(trainX.shape, trainY.shape, testX.shape, testY.shape)
return trainX, trainY, testX, testY
# calculate fbeta score for multi-class/label classification
def fbeta(y_true, y_pred, beta=2):
# clip predictions
y_pred = backend.clip(y_pred, 0, 1)
# calculate elements
tp = backend.sum(backend.round(backend.clip(y_true * y_pred, 0, 1)), axis=1)
fp = backend.sum(backend.round(backend.clip(y_pred - y_true, 0, 1)), axis=1)
fn = backend.sum(backend.round(backend.clip(y_true - y_pred, 0, 1)), axis=1)
# calculate precision
p = tp / (tp + fp + backend.epsilon())
# calculate recall
r = tp / (tp + fn + backend.epsilon())
# calculate fbeta, averaged across each class
bb = beta ** 2
fbeta_score = backend.mean((1 + bb) * (p * r) / (bb * p + r + backend.epsilon()))
return fbeta_score
# define cnn model
def define_model(in_shape=(128, 128, 3), out_shape=17):
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=in_shape))
model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu', kernel_initializer='he_uniform'))
model.add(Dense(out_shape, activation='sigmoid'))
# compile model
opt = SGD(lr=0.01, momentum=0.9)
model.compile(optimizer=opt, loss='binary_crossentropy', metrics=[fbeta])
return model
# plot diagnostic learning curves
def summarize_diagnostics(history):
# plot loss
pyplot.subplot(211)
pyplot.title('Cross Entropy Loss')
pyplot.plot(history.history['loss'], color='blue', label='train')
pyplot.plot(history.history['val_loss'], color='orange', label='test')
# plot accuracy
pyplot.subplot(212)
pyplot.title('Fbeta')
pyplot.plot(history.history['fbeta'], color='blue', label='train')
pyplot.plot(history.history['val_fbeta'], color='orange', label='test')
# save plot to file
filename = sys.argv[0].split('/')[-1]
pyplot.savefig(filename + '_plot.png')
pyplot.close()
# run the test harness for evaluating a model
def run_test_harness():
# load dataset
trainX, trainY, testX, testY = load_dataset()
# create data generator
datagen = ImageDataGenerator(rescale=1.0/255.0)
# prepare iterators
train_it = datagen.flow(trainX, trainY, batch_size=128)
test_it = datagen.flow(testX, testY, batch_size=128)
# define model
model = define_model()
# fit model
history = model.fit_generator(train_it, steps_per_epoch=len(train_it),
validation_data=test_it, validation_steps=len(test_it), epochs=50, verbose=0)
# evaluate model
loss, fbeta = model.evaluate_generator(test_it, steps=len(test_it), verbose=0)
print('> loss=%.3f, fbeta=%.3f' % (loss, fbeta))
# learning curves
summarize_diagnostics(history)
# entry point, run the test harness
run_test_harness()
运行示例首先加载数据集,并将其分割为训练集和测试集。打印每个训练和测试数据集的输入和输出元素的形状,确认执行了与之前相同的数据分割。
对模型进行拟合和评估,并在测试数据集上报告最终模型的F-beta评分。
由于学习算法的随机性,您的特定结果可能会有所不同。
在本例中,基线模型的F-beta评分约为0.831,比上一节报告的0.483的初值好很多。这表明基准模型是成熟的。

F-beta得分还创建了一个图并保存到文件中,显示了训练上模型和测试集上关于损失和F-beta的学习曲线。
在这种情况下,损失学习曲线的曲线图表明,模型对训练数据集过度拟合,可能在epoch 20 / 50左右,尽管过度拟合似乎并没有对模型在测试数据集上的F-beta分数产生负面影响。
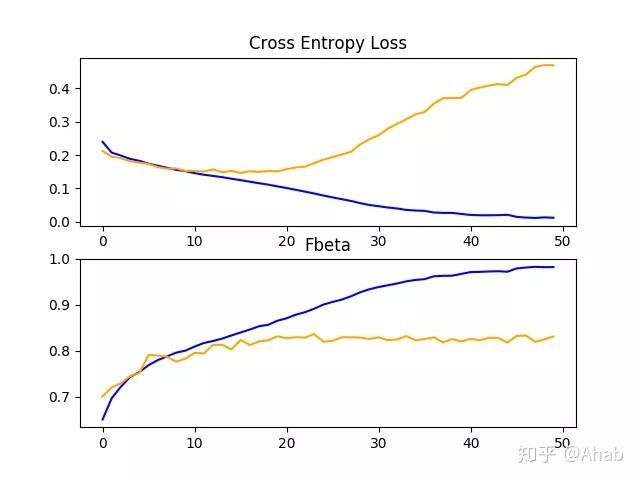
现在,我们已经为数据集建立了一个基准模型,这为实验和改进打下了坚实的基础。
在下一节中,我们将探讨一些改进模型性能的想法。
如何提高模型性能
在上一节中,我们定义了一个基线模型,可用作改进卫星数据集的基础。
该模型获得了合理的F-beta评分,尽管学习曲线表明该模型过度拟合了训练数据集。探索过度拟合的两种常见方法是丢失正则化和数据增强。两者都具有扰乱和减慢学习过程的效果,特别是模型在训练时期上提高的速度。
我们将在本节中探讨这两种方法。鉴于我们期望学习速度减慢,我们通过将训练时期的数量从50增加到200来为模型提供更多的学习时间。
丢弃正则化
Dropout正则化是一种计算成本较低的深度神经网络正则化方法。
丢失通过概率性地移除或“ 丢弃 ”到层的输入来工作,该层可以是数据样本中的输入变量或来自前一层的激活。它具有模拟具有非常不同的网络结构的大量网络的效果,并且反过来使网络中的节点通常对输入更强健。
通常,在每个VGG块之后可以应用少量的dropout,在模型输出层附近的全连接层应用更多的dropout。
下面是define_model()函数,用于添加Dropout的基准模型的更新版本。在这种情况下,每个VGG块后应用20%的dropout,模型中分类器部分的全连通层后应用更大的dropout率为50%。
# define cnn model
def define_model(in_shape=(128, 128, 3), out_shape=17):
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=in_shape))
model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.2))
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.2))
model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(128, activation='relu', kernel_initializer='he_uniform'))
model.add(Dropout(0.5))
model.add(Dense(out_shape, activation='sigmoid'))
# compile model
opt = SGD(lr=0.01, momentum=0.9)
model.compile(optimizer=opt, loss='binary_crossentropy', metrics=[fbeta])
return model
下面列出了基准模型的完整代码清单以及行星数据集中的dropout,以获得完整性。
# baseline model with dropout on the planet dataset
import sys
from numpy import load
from matplotlib import pyplot
from sklearn.model_selection import train_test_split
from keras import backend
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers import Dropout
from keras.optimizers import SGD
# load train and test dataset
def load_dataset():
# load dataset
data = load('planet_data.npz')
X, y = data['arr_0'], data['arr_1']
# separate into train and test datasets
trainX, testX, trainY, testY = train_test_split(X, y, test_size=0.3, random_state=1)
print(trainX.shape, trainY.shape, testX.shape, testY.shape)
return trainX, trainY, testX, testY
# calculate fbeta score for multi-class/label classification
def fbeta(y_true, y_pred, beta=2):
# clip predictions
y_pred = backend.clip(y_pred, 0, 1)
# calculate elements
tp = backend.sum(backend.round(backend.clip(y_true * y_pred, 0, 1)), axis=1)
fp = backend.sum(backend.round(backend.clip(y_pred - y_true, 0, 1)), axis=1)
fn = backend.sum(backend.round(backend.clip(y_true - y_pred, 0, 1)), axis=1)
# calculate precision
p = tp / (tp + fp + backend.epsilon())
# calculate recall
r = tp / (tp + fn + backend.epsilon())
# calculate fbeta, averaged across each class
bb = beta ** 2
fbeta_score = backend.mean((1 + bb) * (p * r) / (bb * p + r + backend.epsilon()))
return fbeta_score
# define cnn model
def define_model(in_shape=(128, 128, 3), out_shape=17):
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=in_shape))
model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.2))
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.2))
model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(128, activation='relu', kernel_initializer='he_uniform'))
model.add(Dropout(0.5))
model.add(Dense(out_shape, activation='sigmoid'))
# compile model
opt = SGD(lr=0.01, momentum=0.9)
model.compile(optimizer=opt, loss='binary_crossentropy', metrics=[fbeta])
return model
# plot diagnostic learning curves
def summarize_diagnostics(history):
# plot loss
pyplot.subplot(211)
pyplot.title('Cross Entropy Loss')
pyplot.plot(history.history['loss'], color='blue', label='train')
pyplot.plot(history.history['val_loss'], color='orange', label='test')
# plot accuracy
pyplot.subplot(212)
pyplot.title('Fbeta')
pyplot.plot(history.history['fbeta'], color='blue', label='train')
pyplot.plot(history.history['val_fbeta'], color='orange', label='test')
# save plot to file
filename = sys.argv[0].split('/')[-1]
pyplot.savefig(filename + '_plot.png')
pyplot.close()
# run the test harness for evaluating a model
def run_test_harness():
# load dataset
trainX, trainY, testX, testY = load_dataset()
# create data generator
datagen = ImageDataGenerator(rescale=1.0/255.0)
# prepare iterators
train_it = datagen.flow(trainX, trainY, batch_size=128)
test_it = datagen.flow(testX, testY, batch_size=128)
# define model
model = define_model()
# fit model
history = model.fit_generator(train_it, steps_per_epoch=len(train_it),
validation_data=test_it, validation_steps=len(test_it), epochs=200, verbose=0)
# evaluate model
loss, fbeta = model.evaluate_generator(test_it, steps=len(test_it), verbose=0)
print('> loss=%.3f, fbeta=%.3f' % (loss, fbeta))
# learning curves
summarize_diagnostics(history)
# entry point, run the test harness
run_test_harness()首先运行示例模型,然后在保持测试数据集上报告模型性能。鉴于学习算法的随机性,您的具体结果可能会有所不同。
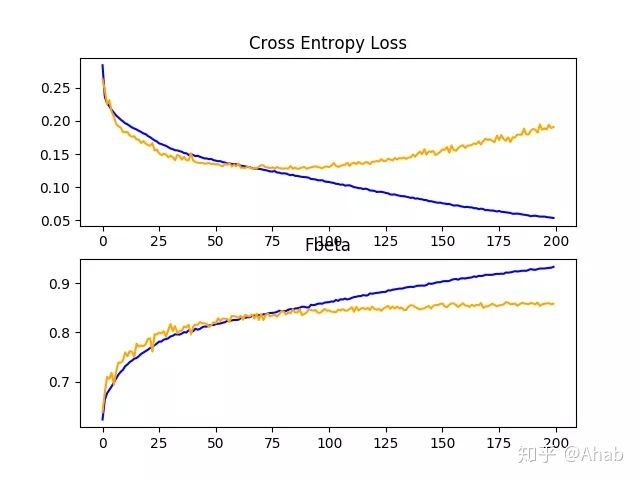
在这种情况下,我们可以看到随着dropout的添加,模型性能从基准模型的F-beta评分约0.831提高到了约0.859。
![]()
回顾学习曲线,我们可以看到dropout对训练和测试组的模型改进率有一定影响。
过拟合已经减少或延迟,尽管性能可能会在运行到中段时(大约epoch 100)开始停滞。
结果表明,可能需要进一步的正规化。这可以通过更大的dropout rate和/或重量衰减的增加来实现。此外,可以减小批量大小,降低学习速度,这两种方法都可能进一步降低模型的改进速度,可能对减少训练数据集的过拟合有积极的作用。
图像数据增强
图像数据增强是一种可用于通过在数据集中创建图像的修改版本来人工扩展训练数据集的大小的技术。
在更多数据上训练深度学习神经网络模型可以产生更熟练的模型,并且增强技术可以创建图像的变体,这可以提高拟合模型将他们学到的东西概括为新图像的能力。
数据增强还可以充当正则化技术,向训练数据添加噪声并鼓励模型学习相同的特征,使其在输入中的位置不变。
卫星照片的输入照片的微小变化可能对此问题有用,例如水平翻转,垂直翻转,旋转,缩放等等。可以将这些扩充指定为ImageDataGenerator实例的参数,用于训练数据集。增强不应该用于测试数据集,因为我们希望评估模型在未修改的照片上的性能。
这要求我们为训练和测试数据集提供单独的ImageDataGenerator实例,然后为各个数据生成器创建的列车和测试集的迭代器。例如:
# create data generator
train_datagen = ImageDataGenerator(rescale=1.0/255.0, horizontal_flip=True, vertical_flip=True, rotation_range=90)
test_datagen = ImageDataGenerator(rescale=1.0/255.0)
# prepare iterators
train_it = train_datagen.flow(trainX, trainY, batch_size=128)
test_it = test_datagen.flow(testX, testY, batch_size=128)
在这种情况下,训练数据集中的照片将被随机水平和垂直翻转以及高达90度的随机旋转所增强。训练和测试步骤中的照片都将按照与基线模型相同的方式缩放像素值。
为了完整起见,下面列出了带有卫星数据集的训练数据增强的基准模型的完整代码清单。
# baseline model with data augmentation for the planet dataset
import sys
from numpy import load
from matplotlib import pyplot
from sklearn.model_selection import train_test_split
from keras import backend
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers import Dense
from keras.layers import Flatten
from keras.optimizers import SGD
# load train and test dataset
def load_dataset():
# load dataset
data = load('planet_data.npz')
X, y = data['arr_0'], data['arr_1']
# separate into train and test datasets
trainX, testX, trainY, testY = train_test_split(X, y, test_size=0.3, random_state=1)
print(trainX.shape, trainY.shape, testX.shape, testY.shape)
return trainX, trainY, testX, testY
# calculate fbeta score for multi-class/label classification
def fbeta(y_true, y_pred, beta=2):
# clip predictions
y_pred = backend.clip(y_pred, 0, 1)
# calculate elements
tp = backend.sum(backend.round(backend.clip(y_true * y_pred, 0, 1)), axis=1)
fp = backend.sum(backend.round(backend.clip(y_pred - y_true, 0, 1)), axis=1)
fn = backend.sum(backend.round(backend.clip(y_true - y_pred, 0, 1)), axis=1)
# calculate precision
p = tp / (tp + fp + backend.epsilon())
# calculate recall
r = tp / (tp + fn + backend.epsilon())
# calculate fbeta, averaged across each class
bb = beta ** 2
fbeta_score = backend.mean((1 + bb) * (p * r) / (bb * p + r + backend.epsilon()))
return fbeta_score
# define cnn model
def define_model(in_shape=(128, 128, 3), out_shape=17):
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=in_shape))
model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu', kernel_initializer='he_uniform'))
model.add(Dense(out_shape, activation='sigmoid'))
# compile model
opt = SGD(lr=0.01, momentum=0.9)
model.compile(optimizer=opt, loss='binary_crossentropy', metrics=[fbeta])
return model
# plot diagnostic learning curves
def summarize_diagnostics(history):
# plot loss
pyplot.subplot(211)
pyplot.title('Cross Entropy Loss')
pyplot.plot(history.history['loss'], color='blue', label='train')
pyplot.plot(history.history['val_loss'], color='orange', label='test')
# plot accuracy
pyplot.subplot(212)
pyplot.title('Fbeta')
pyplot.plot(history.history['fbeta'], color='blue', label='train')
pyplot.plot(history.history['val_fbeta'], color='orange', label='test')
# save plot to file
filename = sys.argv[0].split('/')[-1]
pyplot.savefig(filename + '_plot.png')
pyplot.close()
# run the test harness for evaluating a model
def run_test_harness():
# load dataset
trainX, trainY, testX, testY = load_dataset()
# create data generator
train_datagen = ImageDataGenerator(rescale=1.0/255.0, horizontal_flip=True, vertical_flip=True, rotation_range=90)
test_datagen = ImageDataGenerator(rescale=1.0/255.0)
# prepare iterators
train_it = train_datagen.flow(trainX, trainY, batch_size=128)
test_it = test_datagen.flow(testX, testY, batch_size=128)
# define model
model = define_model()
# fit model
history = model.fit_generator(train_it, steps_per_epoch=len(train_it),
validation_data=test_it, validation_steps=len(test_it), epochs=200, verbose=0)
# evaluate model
loss, fbeta = model.evaluate_generator(test_it, steps=len(test_it), verbose=0)
print('> loss=%.3f, fbeta=%.3f' % (loss, fbeta))
# learning curves
summarize_diagnostics(history)
# entry point, run the test harness
run_test_harness()
运行示例首先匹配模型,然后在保持测试数据集上报告模型性能。由于学习算法的随机性,您的特定结果可能会有所不同。
在这种情况下,我们可以看到性能提升了约0.06,从基准模型的F-beta评分约0.831提高到基线模型的评分约0.882,并且只增加了简单的数据。这是一个很大的改进,比我们看到的dropout的强大。

回顾学习曲线,我们可以看到过度拟合受到了极大的影响。学习一直持续到超过100个epochs,尽管在学习结束时可能会有趋于平稳的迹象。结果表明,进一步增强或在此配置中添加其他类型的正则化可能会有所帮助。
探索可能进一步鼓励学习其在输入中的位置不变的特征(例如缩放和移位)的附加图像增强可能是有趣的。

讨论
我们对基准模型进行了两种不同的改进。
虽然由于算法的随机性,我们必须假设这些结果有一定的方差,但结果可以总结如下:
- 基准+ Dropout正则化:0.859
- 基准+数据增加:0.882
正如所怀疑的,正则化技术的添加减缓了学习算法的进程,并减少了过度拟合,从而提高了数据集的性能。这两种方法结合在一起,再加上训练时间的进一步增加,很可能会导致进一步的改善。也就是说,Dropout和数据扩充的结合。
这只是可以在这个数据集上探索的改进类型的开始。除了对所述正则化方法进行调整外,还可以探索其他正则化方法,如重量衰减和早期停止。
它可能值得研究学习算法的变化,例如学习速度的变化、学习速度调度的使用或自适应学习速度(如Adam)。
替代模型体系结构也值得探索。所选择的基线模型预计将提供比这个问题可能需要的更多的容量,较小的模型可能更快地进行训练,从而可能导致更好的性能。
未完待续...
推荐阅读:
在Python中开始使用 XGBoost的7步迷你课程
第 01 课:梯度提升简介
第 02 课:XGBoost 简介
第 03 课:开发您的第一个 XGBoost 模型
隔三岔五聊算法之极小极大算法